




写在前面
之前,我们在 Towhee[1] 的帮助下,完成了「以图搜图」系统、「以文搜图」系统的搭建和部署,并用它们实现了有趣酷炫的搜索任务!
可是,你知道我们搭建的搜索系统背后是如何运作的吗?AI 模型是怎么理解图片的?
在深度学习任务中,非结构化数据(例如图片、视频、音频等)的处理通常处在结构内部而不可见,很多时候我们只能看到结果,却不知道结构深处的数据 、神经网络、向量之间是如何互动的。
幸运的是,Towhee[2] 不仅可以帮我们搭建一个 AI 业务工具,还能可视化 AI 模型内部的业务流程,能帮助我们更好的理解诸如深度学习这一类 AI 任务的运作原理。
本文主要选取了深度学习中常用的 CNN 模型、Transformer 模型、 CLIP 模型(多模态 Transformer),利用 Towhee 可视化各个模型如何一步步理解图片,从细微的角度更直观地帮助我们理解深度学习任务。
是不是迫不及待了呢?那么,就请跟着往下吧!
准备工作
在这之前,我们需要搭建依赖的环境,需要安装的 Python 包有 towhee 、towhee.models 、pillow 、ipython 、captum 、matplotlib。安装代码如下所示:
python -m pip install -q towhee towhee.models pillow ipython captum matplotlib
搭建好环境后,让我们先从最经典的卷积神经网络 CNN 入手吧!
CNN 模型如何分类图像?
神经网络有一个一直被人们诟病的问题,它是一个“黑箱操作”,内部的推理过程不可见。对于网络的输出结果,我们很难解释为什么会得出这样的结果,因此也不容易形成反馈去改进网络的训练。所以,对神经网络模型的解释和可视化是一个很重要的工作,它能帮助我们直接观察模型内部的输出,加深对神经网络的理解,帮助定位问题改善模型。
在本节中,我们选用最经典的卷积神经网络 CNN 提取图像特征,通过比较不同的基于归因(attribution-based)的算法来弄清楚神经网络是如何对图像进行分类的。
Towhee 集成了许多经典CNN网络的可解释性算法,例如 Occlusion, GradientShap, Saliency 等(更多可解释性算法原理可参考 captum[3] )。我们在这里选用预训练好的 resnet-18 模型,以一张鸟的图片( towhee.png[4] )为例,利用Towhee可视化工具展示图片中影响预测结果的部分。
Towhee[5] 红眼雀,属雀形目,比一般雀类有更长的尾巴,主要分布在美洲。
from PIL import Image
from towhee.trainer.utils.plot_utils import interpret_image_classification, predict_image_classification
from torchvision.models import resnet18
from torchvision import transforms
from cls2idx import CLS2IDX # dictionary of labels
resnet_model = resnet18(pretrained=True)
resnet_model.eval()
img1 = Image.open('towhee.png')
val_transform = transforms.Compose([
lambda x: x.convert('RGB') if x.mode != 'RGB' else x,
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
)
])
img = val_transform(img1).unsqueeze(0)
score, idx = predict_image_classification(model, img)
interpret_image_classification(resnet_model.to('cpu'), img1, val_transform, 'Occlusion', fig_size=(5, 5))
interpret_image_classification(resnet_model.to('cpu'), img1, val_transform, 'GradientShap', fig_size=(5, 5))
interpret_image_classification(resnet_model.to('cpu'), img1, val_transform, 'Saliency', fig_size=(5, 5))
print('It is {}.'.format(CLS2IDX[pred_label_idx].lower()))
print('probability = {}'.format(prediction_score))
其中,Occlusion、GradientShap、Saliency 用三种不同方法解释了模型对图片的预测根据:
Occlusion:遮盖输入样本的不同部分,随后计算此改变对最终预测值的影响,分析出不同部分的重要性。 
GradientShap:每个输入样本加上数次白噪音,随机选择一个基线和输入之间的点,计算输出相对于这些随机点的梯度。 
Saliency:基于输入的梯度,计算每个特征的重要性。 
无一例外,每种可解释性算法都表明模型最终的关注点基本都落在了图片中鸟的部分,而不是图片边缘地区的草或者阴影区域。最后,模型将这些具有意义的图片特征(向量)映射到对应的数据集标签中,得到最终结果:
robin, american robin, turdus migratorius
是一种与红眼雀同科目的雀类,外形十分相似。
同时,模型也评估了预测结果对应的分数:
probability = 0.9424256682395935
表明该预测结果的可信度很高。也就是说,在我们的这个例子中,CNN 模型是因为最终向量关注在图片中的鸟上面,才推理出该图片对应的标签为一种鸟类。
Transformer 模型如何分类图像?
Transformer 是一种不同于卷积的新架构,它首先在自然语言领域取得了巨大成功,近年来伴随着 Vision Transformers[6](ViT)的诞生,也成功探索了 Transformer 架构在计算机视觉上的应用。如今,许多先进模型都是基于 Transformer 架构衍生而来,这些变种模型的性能已经在众多计算机视觉任务上超越了卷积模型。
随着 Transformer 架构被越来越广泛地应用, 我们迫切需要一个可视化工具来帮助解释 Transformer 模型。Towhee 提供了专门针对 Transformer 架构的可视化工具,只需要一行代码,即可基于 Transformer 的注意力绘制热力图(heat map)。
在本节中,我们使用 Towhee 的可视化工具绘制注意力的热力图,解释了 Transformer 模型如何进行图像分类。这里我们选择两种最常见和通用的 Transformer 模型进行演示:Vision Transformers[7] (ViT)和 Multiscale Vision Transformers[8] (MViT),衡量注意力重要性的可解释性算法分别采用了 transformer_attribution[9] 和 rollout[10]。
首先,我们将 ViT模型推理最后一层的注意力进行可视化,在不同可解释性算法下进行观察。
from towhee.models.visualization.transformer_visualization import show_image_heatmap
from towhee.models import vit
vit_model = vit.create_model(model_name='vit_base_16x224', pretrained=True)
vit_model.eval()
score, idx = predict_image_classification(vit_model, img)
print('It is {}.'.format(CLS2IDX[idx].lower()), score)
show_image_heatmap(vit_model, img1, transform=val_transform, method='transformer_attribution')
show_image_heatmap(vit_model, img1, transform=val_transform, method='rollout')
transformer_attribution:基于深度泰勒分解分配局部相关性,然后通过网络层传播相关性分数。 
rollout:直观地追踪注意力在每层网络中的变化。 
可以看到,前一种算法关注的区域主要集中在鸟的翅膀和背部,而后一种算法关注的区域集中在有着鲜艳毛色的肚子上。凭借这些局部特征,ViT 模型推测该图片为:
brambling, fringilla montifringilla
虽然与上文中 CNN 模型推理的结果不一致,但同样判定该图片是一种雀类。接下来让我们试一下 Multiscale Vision Transformer(MViT)模型,看一下它是如何判定这张图片的。
from towhee.models.multiscale_vision_transformers import create_mvit_model
# Download pretrained weights from https://github.com/towhee-io/examples/releases/download/data/IN1K_MVIT_B_16_CONV.pyth
mvit_model = create_mvit_model('imagenet_b_16_conv',
checkpoint_path='./IN1K_MVIT_B_16_CONV.pyth')
score, idx = predict_image_classification(mvit_model, img)
print('It is {}.'.format(CLS2IDX[idx].lower()), score)
show_image_heatmap(mvit_model, img1, method='transformer_attribution')
show_image_heatmap(mvit_model, img1, method='rollout')

 从MViT的热力图中,我们惊奇地发现 MViT 模型是主要通过关注鸟喙将该图片判定为某种雀类的。
从MViT的热力图中,我们惊奇地发现 MViT 模型是主要通过关注鸟喙将该图片判定为某种雀类的。
通过以上的展示,我们可以推断 ViT 模型识别鸟类的依据落在鸟的身体上,而 MViT 则更关注鸟的面部特征。与卷积模型相比,Transformer 模型会关注更细节部分,更能捕捉预测的关键因素。让我们使用另一张猫头鹰的图片,通过Towhee可视化最后输出的向量,更明显地比较以上三个模型的侧重点:

 卷积模型更多关注了图片中鸟的整体轮廓和身体特征,只能识别出该图片是“鹰”,却不能判断出是猫头鹰(已知标签中含有“猫头鹰”)。而 ViT 模型关注到了鸟的翅膀等更细节的身体部位,MViT 甚至还成功注意到猫头鹰最具辨别力的脸部特征,因此两个 Transformer 模型能够更准确地将该图片分类为“猫头鹰”。
卷积模型更多关注了图片中鸟的整体轮廓和身体特征,只能识别出该图片是“鹰”,却不能判断出是猫头鹰(已知标签中含有“猫头鹰”)。而 ViT 模型关注到了鸟的翅膀等更细节的身体部位,MViT 甚至还成功注意到猫头鹰最具辨别力的脸部特征,因此两个 Transformer 模型能够更准确地将该图片分类为“猫头鹰”。
CLIP 模型如何匹配文本和图像?
以上我们通过 Towhee 可视化工具观察了模型最后输出的关注偏好,从而比较了 CNN 和 Transformer 模型在分类图像时的不同依据。接下来,我们将通过 Towhee 可视化工具了解跨模态模型是如何理解和匹配不同形式的数据。
CLIP[11] 是这两年来大火的一个多模态模型,首次打通了自然语言与图像之间的鸿沟。CLIP 使用大量的训练数据,成功证明了用自然语言信号来监督图像训练的可行性,并取得了炸裂的效果,衍生出了一系列各式各样下游的模型和任务。
在「以文搜图」任务中,我们就用到了 CLIP 模型。一般来说,给定一个图像-文本对,CLIP 模型可以计算这两个不同模态数据之间的相似度,通过比较相似度实现以文搜图这类跨模态任务。我们可以通过 Towhee 可视化工具解释 CLIP 模型匹配文本与图片的逻辑。只需要一行代码,便可以找到在模型计算相似度时起关键作用的图像区域或文本片段,这有助于我们更好地理解跨模态任务。这里文本/图片多模态模型可视化用到的可解释性算法是 Integrated Gradients[12],能够计算与衡量每个特征对最终预测结果的影响力。
我们选取了一张包含猫、狗、毯子的图片(cat_and_dog.png[13])为例,通过与不同文本匹配,观察 CLIP 模型在计算相似度时,主要受到哪些图片和文本区域的影响。
from towhee.models.visualization.clip_visualization import show_attention_for_clip
from towhee.models.clip import clip
cat_dog_img = Image.open('cat_and_dog.png')
model = clip.create_model(
model_name="clip_vit_b32",
pretrained=True,
device="cpu",
jit=False,
vis=True
)
text_list = ['a dog', 'a cat', 'The blanket on top']
show_attention_for_clip(model, cat_dog_img, text_list)
 在可视化里,颜色越深表示该部分越重要。不难看出,在匹配“a dog”与该图片时,图片中狗的脸部特征和文本中“dog”一词起到了关键作用。同样在匹配“a cat”与该图片时,“cat“一词和图片中猫脸部分被高亮标出。而在匹配”a blanket on top“与该图片时,图中的小动物们不再强烈地影响相似度计算,图中的毯子取而代之与文本中“blanket”一起提高了最终的相似度。
在可视化里,颜色越深表示该部分越重要。不难看出,在匹配“a dog”与该图片时,图片中狗的脸部特征和文本中“dog”一词起到了关键作用。同样在匹配“a cat”与该图片时,“cat“一词和图片中猫脸部分被高亮标出。而在匹配”a blanket on top“与该图片时,图中的小动物们不再强烈地影响相似度计算,图中的毯子取而代之与文本中“blanket”一起提高了最终的相似度。
神经网络如何提取特征?
前面的例子都可视化了神经网络最后一层输出的向量特征对预测结果的影响,然而深度学习往往具有多层网络,由于中间的输出不可见而导致难以解释模型推理过程。Towhee 提供的可视化工具不仅可以帮助理解模型如何预测最终结果,也可以展示模型每个步骤产生的变化,让我们理解模型的推理过程。在 Towhee 特征提取工具 EmbeddingExtractor 的帮助下,我们可以选择模型内部某层输出的向量,然后将其可视化。
这里我们仍用 towhee.png 与 ResNet 18 模型为例,首先我们看下该模型结构:
from towhee.models.embedding.embedding_extractor import EmbeddingExtractor
emb_extractor = EmbeddingExtractor(resnet_model)
# emb_extractor.disp_modules(full=True)
# print(len(emb_extractor.modules_dict))
print(emb_extractor.modules_dict.keys())
共计68层:
dict_keys(['',
'conv1',
'bn1',
'relu',
'maxpool',
'layer1',
'layer1.0',
'layer1.0.conv1',
'layer1.0.bn1',
'layer1.0.relu',
'layer1.0.conv2',
'layer1.0.bn2',
... # 48 layers
'layer4.1',
'layer4.1.conv1',
'layer4.1.bn1',
'layer4.1.relu',
'layer4.1.conv2',
'layer4.1.bn2',
'avgpool',
'fc'])
让我们用可视化工具观察和比较五个在不同深度的卷积层的输出:conv1、layer1.1.conv1、layer2.1.conv1、layer3.1.conv1、layer4.1.conv1。
from towhee.models.embedding.embedding_extractor import show_embeddings
layer_name_list = [
'conv1',
'layer1.1.conv1',
'layer2.1.conv1',
'layer3.1.conv1',
'layer4.1.conv1',
]
for layer_name in layer_name_list:
emb_extractor.register(layer_name)
resnet_model(img)
show_embeddings(emb_extractor.emb_out.embeddings, figsize=(10, 80), emb_name_list=layer_name_list)
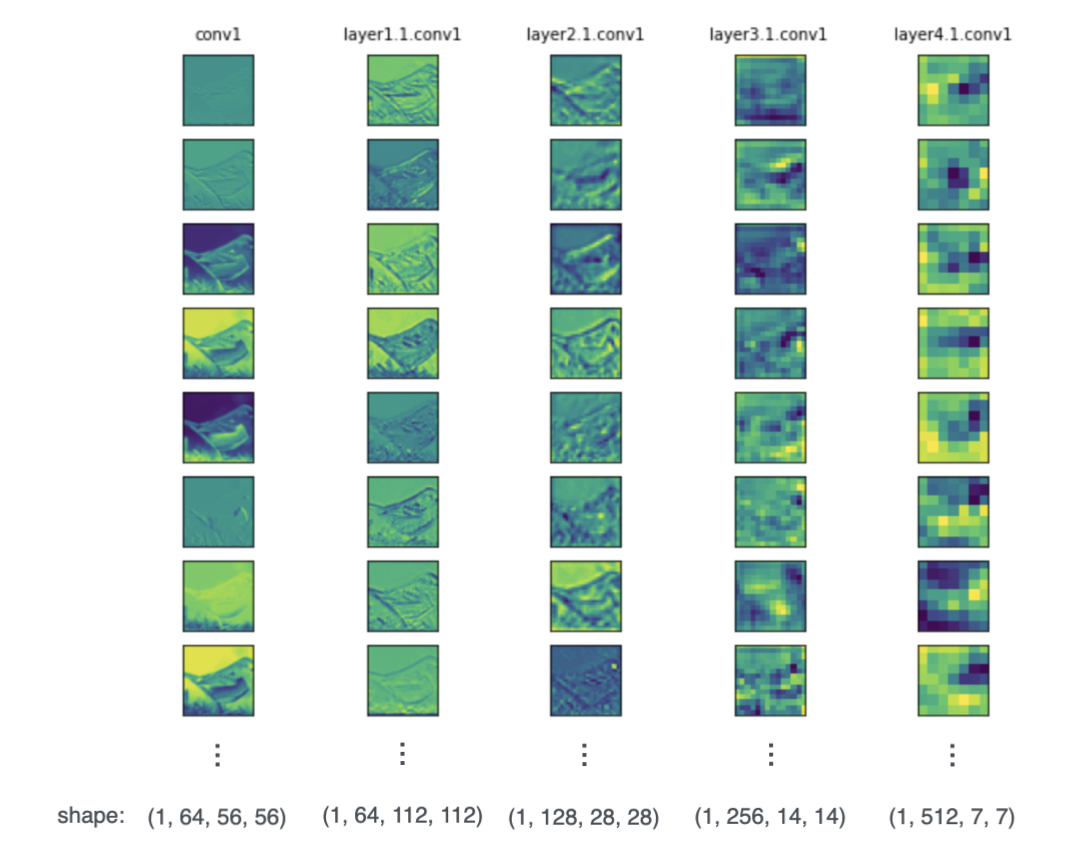 通过 Towhee 的可视化,我们可以清楚地看到模型对图像的理解和推理过程。在浅层网络中,模型用较低维度表示边缘特征,能够识别图片中物体的轮廓信息。随着网络层的加深,模型通过学习逐渐拥有了更强的表示能力,能够用更多维度的特征表达更高级的信息,比如鸟的头部、翅膀等细节。
通过 Towhee 的可视化,我们可以清楚地看到模型对图像的理解和推理过程。在浅层网络中,模型用较低维度表示边缘特征,能够识别图片中物体的轮廓信息。随着网络层的加深,模型通过学习逐渐拥有了更强的表示能力,能够用更多维度的特征表达更高级的信息,比如鸟的头部、翅膀等细节。
总结
在 Towhee 的帮助下,我们不仅可以搭建一个 AI 业务工具,还可以探究这些工具背后的运作原理,以便于我们更容易去理解和解释深度学习任务。本文选取的例子都比较简单有趣,有兴趣的同学不妨跟着试一试,亲自动手体验其中的乐趣!
参考资料
Towhee: https://towhee.io/
[2]Towhee: https://github.com/towhee-io/towhee
[3]captum: https://captum.ai/
[4]towhee.png: https://github.com/towhee-io/examples/blob/main/image/visualization/towhee3.png
[5]Towhee: https://en.wikipedia.org/wiki/Eastern_towhee
[6]Vision Transformers: https://arxiv.org/abs/2010.11929
[7]Vision Transformers: https://github.com/towhee-io/towhee/blob/e64251f67417de22c980ad0846b728772cad376c/towhee/models/vit/vit.py#L50
[8]Multiscale Vision Transformers: https://github.com/towhee-io/towhee/blob/e64251f67417de22c980ad0846b728772cad376c/towhee/models/multiscale_vision_transformers/mvit.py#L729
[9]transformer_attribution: https://github.com/towhee-io/towhee/blob/e64251f67417de22c980ad0846b728772cad376c/towhee/models/vit/vit.py#L194
[10]rollout: https://arxiv.org/pdf/2005.00928v2.pdf
[11]CLIP: https://openai.com/blog/clip/
[12]Integrated Gradients: https://arxiv.org/pdf/1703.01365.pdf
[13]cat_and_dog.png: https://github.com/towhee-io/examples/blob/main/image/visualization/cat_and_dog.png
Zilliz 是向量数据库系统领域的开拓者和全球领先者,研发面向 AI 生产系统的向量数据库系统。Zilliz 以发掘非结构化数据价值为使命,致力于打造面向 AI 应用的新一代数据库技术,帮助企业便捷地开发 AI 应用。Zilliz 的产品能显著降低管理 AI 数据基础设施的成本,帮助 AI 技术赋能更多的企业、组织和个人。

