




节前我处理了一个问题。先上图,可以看出来查询这个表,有两个条件,一个是code一个是实际。最终执行查了5000万行数据。历时900秒。当然最后也是查了个寂寞,没查到。
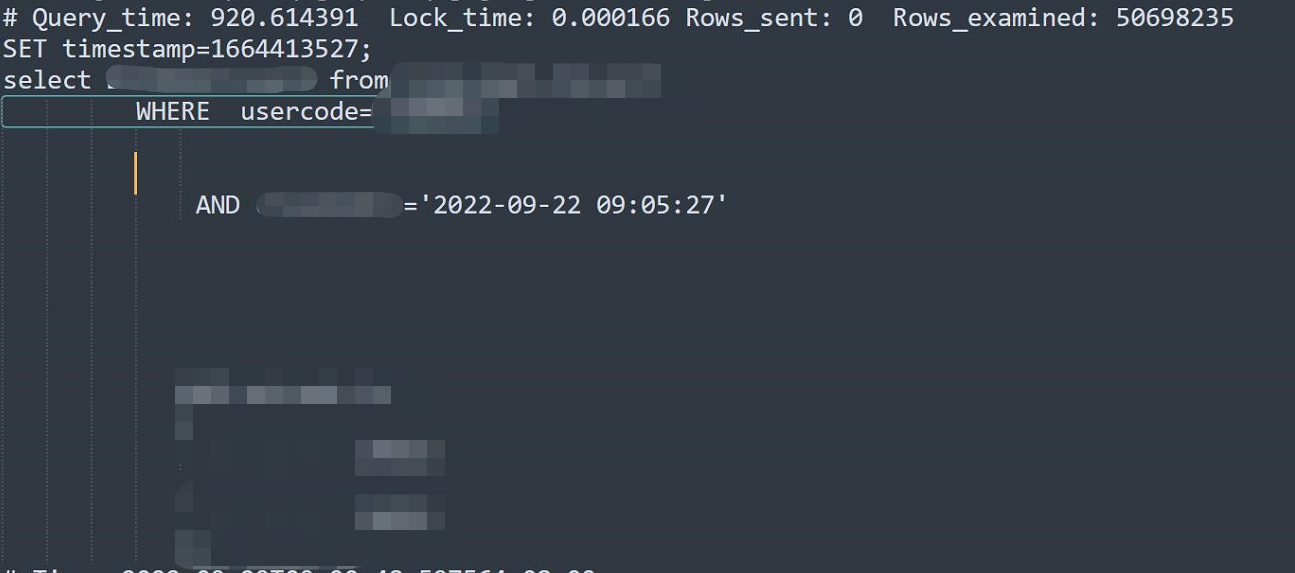
对于5000万扫查了900秒,这个我既能理解,又不能理解。
能理解的是扫描5000万用900多秒,说的过去。 不能理解是。从2022年1月开始到现在这个表一共才2亿条。 我每月一个分区,查询一个星期,怎么也在月的分区中。那个code的一个星期数据在150万左右。不应该会查到5000万。
即使不带code,一个星期也就700万。
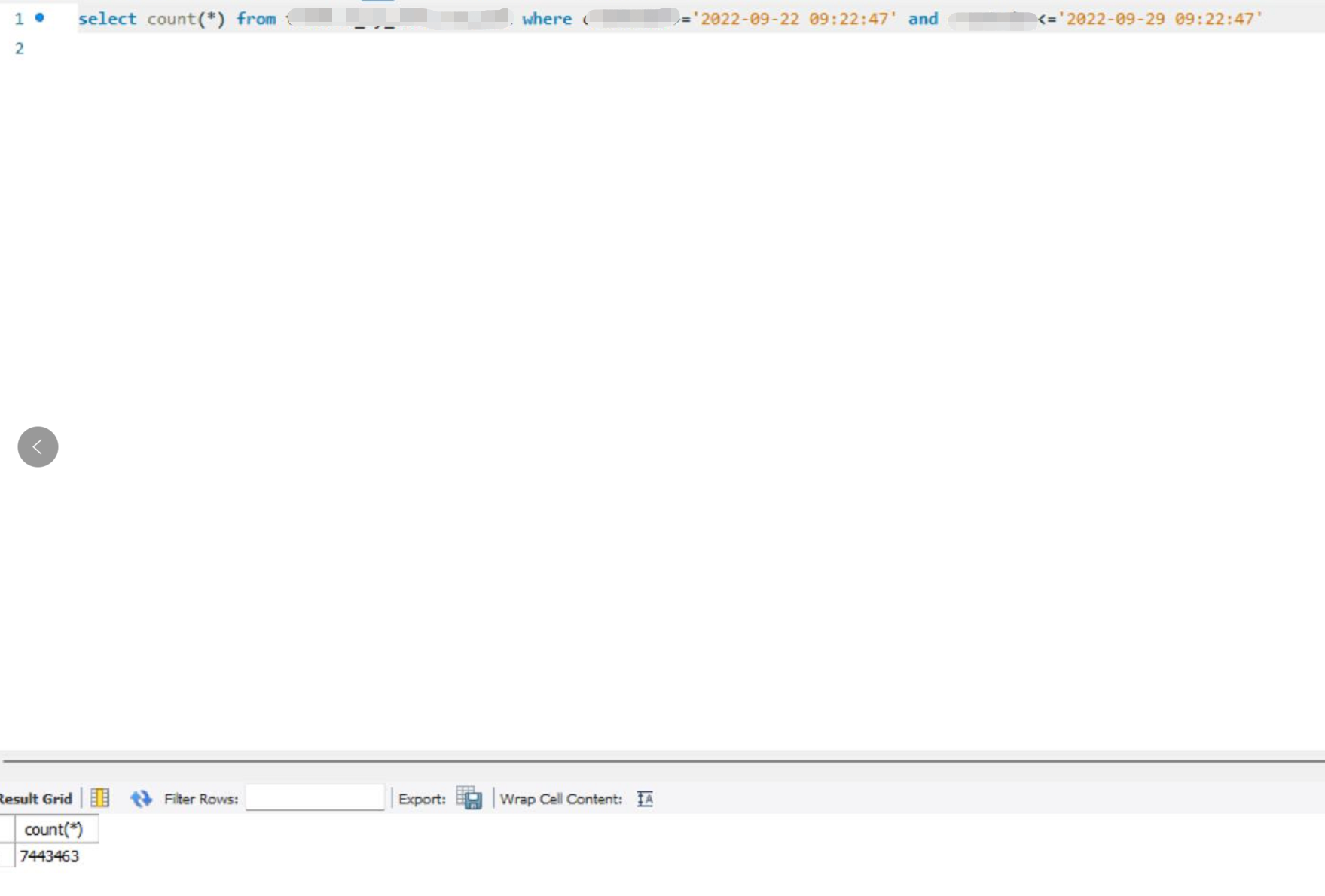
不过我依然相信这个5000万是实际发生的。
我当时就想一个月大不了就700万,要到5000万,那要8个700万差不多。
等等,说到这里,我似乎发现了什么。七八五十六啊,因为差不多现在这个表也就是八九个分区的样子。
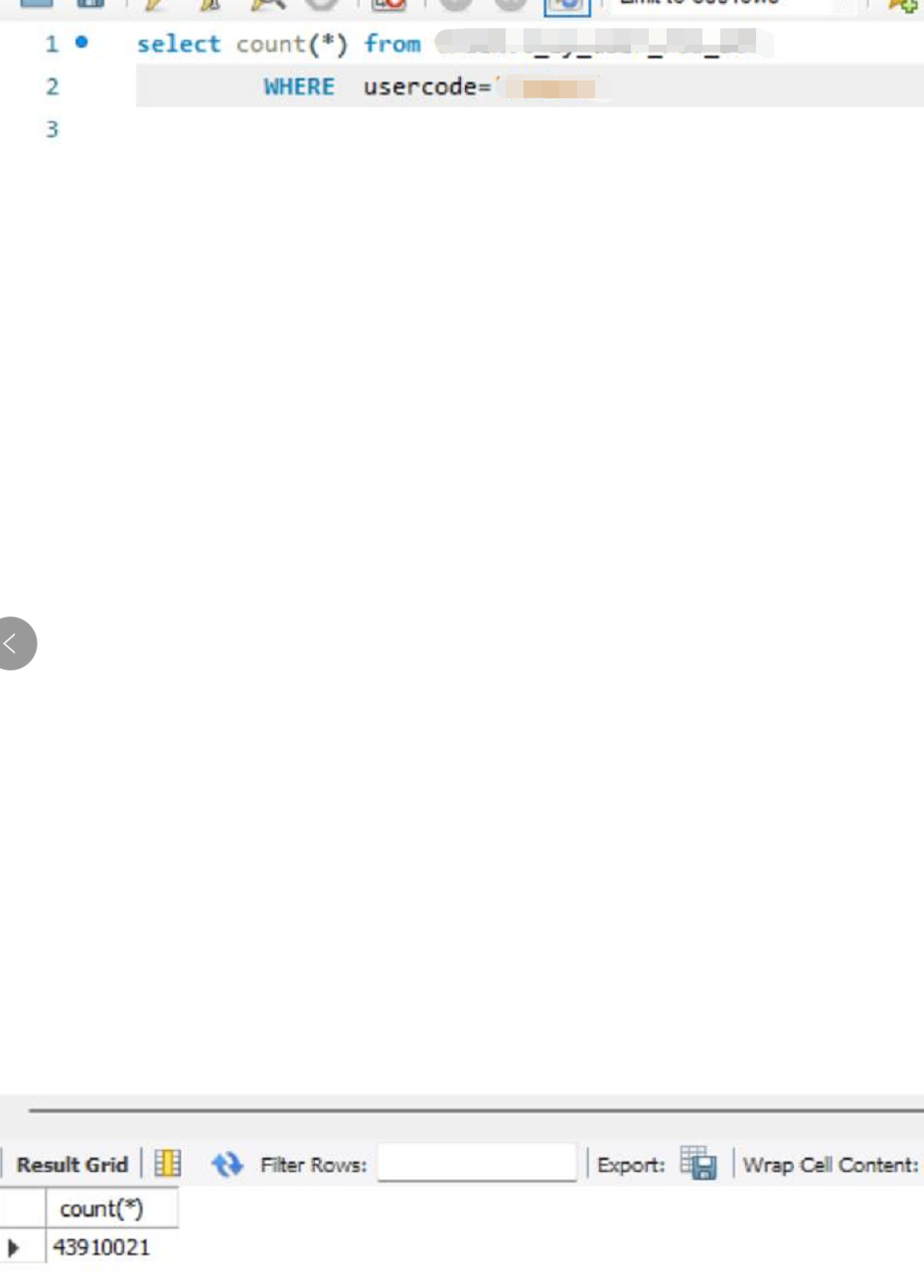
那么我只查code发现大约4300万左右。那么说明在实际查询过程中,那一个星期数据的code数据,被认为只有一个星期而没有code。而在这种情况下,一个星期的和平时一个月数据量大致相等,又变成了跨所有分区执行。
是不是bug我不好说。因为不是每次都这样。这情况倒是第一次遇到。在Oracle中只要时间落在一个月度中的,是不会产生跨月度分区的。
这可能是优化器不同,Oracle优化器目前还是最厉害的。
也许看到这里有人说MySQL的分区不好,不过我用到现在也就是这个场景出了跨分区的问题。如果时间选择不是一周,而是3天或者5天,是没有问题的。或者说一周的数据量和一个月数据量相差很远,不造成数据库误判也是没有问题的。
MySQL分区还是利大于弊。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
