




在本文中,我演示了如何通过使用并行性(将原始查询拆分为多个并行子查询)优化Amazon DynamoDB中的大量数据查询,以满足大型Dynamo DB数据库查询的严格性能SLA。
在与客户接洽期间,我们经常需要从DynamoDB数据库检索大量记录。我曾参与过许多项目,在这些项目中,我们需要处理数据,以便计算关键绩效指标(KPI)或根据数据洞察力做出业务决策。在大多数情况下,这些进程是API的后端,因此处理时间通常为次秒。默认情况下,DynamoDB提供单位数毫秒的读/写性能,但某些用例要求相同的快速响应时间,即使在查询大量记录时也是如此。
DynamoDB是一个键值和文档数据库,它提供了多种方法来使用扫描和查询操作检索大量记录。扫描操作检查表或二级索引中的每个项,查询操作检索项集合中的数据。这一差异意味着在评估大数据块时,查询操作比扫描操作更快。
除了讨论如何针对大量数据优化DynamoDB查询之外,我还将向您展示如何使用一些新的Java8特性来改进这种方法。我讨论了一些现代Java概念,如Java流(常规、并行和反应式)、并行、多线程和反应式编程范式。我分析了各种方法的优缺点,并分享了AWS SDK for Java和AWS SDKfor Java 2.x的代码示例。本演练面向所有经验级别的Java开发人员。
注意:您可以使用并行扫描方法来优化扫描操作。这种方法可以提高扫描性能,但需要额外的表吞吐量。有关比较查询和扫描检索操作的性能和成本的更多信息,请参阅查询和扫描数据的最佳实践。
解决方案概述
优化查询操作的一种方法是将一个大型查询任务拆分为多个较小的任务,每个任务都可以在更短的时间内完成。在这个解决方案中,我通过在多个线程中运行并行子查询来实现总体更快的性能。使用这种方法,查询操作的总持续时间接近最慢子查询的持续时间。
该方法基于著名的范例,如MapReduce、divide-and-corquer和split-apply-combine。
创建子查询
要创建高效的子查询,首先要将大型单个查询拆分为多个子查询。本文分享了一些使用分区键和排序键的有用技巧。
为了说明这种方法,我使用了一个使用id作为主键的orders表。一些主要属性包括产品ID(sku)、产品类别(category)、订单日期(order date)、售出数量(qty)和单价(unit price),如下图1所示。
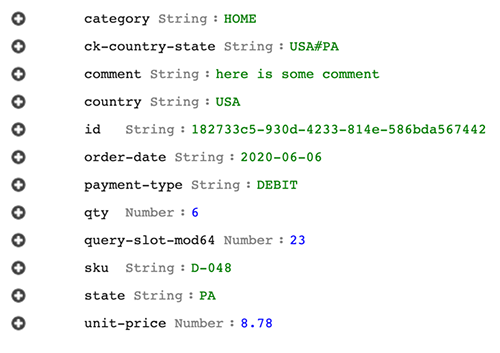
图1–订单表的属性
为了准备解决方案,我使用了DynamoDB控制台来创建表并分配名称和主键。
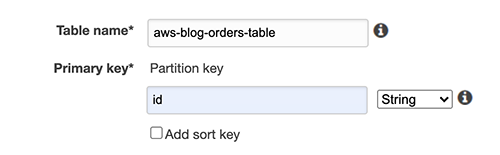
图2–创建订单表
然后,我添加了一个全局二级索引,其中category作为分区键,order date作为排序键。
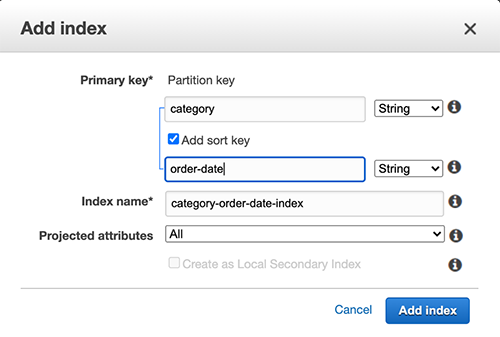
图3–添加全局二级索引
最后一步是将一些测试数据添加到表中。
图4–测试数据
例如,假设您想查询2020年的所有数据(订单日期需要与您搜索的年份相匹配),并且类别值等于SPORT。我的方法是将此查询拆分为几个大小相同的子查询,例如每月查询。在本例中,我有12个子查询可以并行运行。假设订单在一年中有一定程度的均匀分布,尽管这不需要精确,但数量级很好。
上述示例使用以下查询,其语法类似于AWS命令行界面(AWS CLI):
--key-condition-expression "category = :v1 AND begins_with(order-date, :v2")
对于这种情况,我使用订单日期前缀–在前面的代码中表示为:v2值占位符–例如2020-01、2020-02等。类似地,:v1将SPORT作为一个类别包含在查询中。
除了这12个子查询之外,我还尝试了以下内容:
-
48个并行子查询,例如2020-01-0、2020-01-1和2020-01-2等,每个月又增加了4个子查询。
-
365(或366)个子查询,每天一次。
如果没有合适的排序键可用于均匀分割子查询,则可以选择生成一个新列,其中包含某个数字序列的模值(生成测试数据时,序列值递增)。另一个想法是在数据库中插入数据时使用纳米时间。使用mod(modulo)函数的值应该等于预期子查询的数量。对于本例,我有64个查询槽。根据您的情况,您可以创建几个查询插槽属性,例如32、64和128插槽,具体取决于您的用例。只需根据所需的插槽大小修改数字序列或纳米时间值即可。根据数据的不同,此方法可以比使用订单日期更均匀地分割数据(这应该根据实际数据和查询模式进行验证)。
为了简单起见,本文的剩余部分讨论了订单日期的实现。您可以从GitHub下载用于实现订单日期或mod方法的代码。
并行子查询
并行化子查询的方法不止一种。可以使用多线程在同一进程内完成,也可以在同一主机上或在分布式环境中使用多个进程。在下面的解决方案中,我将重点放在具有多个核心的计算环境(在大多数计算环境中都有)的单个进程上。拥有多个核心可以实现真正的并行查询,其中每个核心都可以不间断地运行任务。
注意:有关并发与并行比较的更多信息,请参阅 From concurrent to parallel: Understanding the factors influencing parallel performance.
如前一节所述,解决方案使用相互独立且可以同时运行的任务。这种类型的工作量通常被称为一个令人尴尬的并行问题,可以使用本文中讨论的方法来解决。
在讨论此解决方案的多线程机制之前,讨论与CPU和I/O使用相关的任务类型很重要。依赖高CPU利用率的计算进程称为CPU受限进程。相反,I/O绑定的进程受完成I/O操作所需的时间限制。调用远程服务来执行诸如DynamoDB查询之类的任务是I/O绑定进程的一个示例。
通常,对于CPU绑定的进程,您分配的线程数不应超过内核数减去1。例如,对于16核环境,不与任何其他进程共享,除了主进程线程外,您最多可以创建15个线程来运行并行任务。但在I/O绑定的工作负载中,您可以安全地创建比内核数量多得多的线程,因为内核大多等待远程服务完成其任务。
下面的讨论是基于Java的,但您可以将相同的概念应用于其他编程语言。
实施
在本节中,我将讨论如何通过Java线程化和使用CompletableFuture异步框架并发运行子查询来实现解决方案。
Java和线程
Java提供了几种构建多线程解决方案的方法,包括:
-
基本线程类。
-
使用ExecutorService接口的托管线程池。
-
CompletableFuture类。
每个选项都有优点和缺点。有些方法更容易编码,但功能较少,而其他方法可能需要更多的知识和编码工作。您选择的方法应该在复杂性和灵活性之间取得平衡,使解决方案相对容易实施,同时实现性能目标。
从Java8开始,Java设计者添加了JavaStream特性,这提高了使用迭代的代码的可读性和简单性。此外,他们还添加了并行流,从而简化了多线程的使用。
应该注意,Java8并行流使用公共ForkJoin线程池。公共ForkJoin池中可用的线程数比内核数少1。您可以增加线程池的大小,但这样做会更改使用公共ForkJoin线程方法的所有其他代码实例的池大小,因此应该谨慎实现。
使用order-date方法创建子查询,该方法使用年-月值,如下图5所示。图5显示了一个主查询,用于查找类别为SPORT的所有记录,并根据月份将其拆分为多个子查询。然后将子查询的结果合并为单个结果。

图5–按月份将主查询拆分为子查询
您可以使用下图6所示的设计,使用并行流来收集订单,对上述解决方案进行编码。
1.创建查询参数列表,并决定用于将查询拆分为子查询的逻辑。
2.并行运行子查询以构建数据流。
-
a.为每个查询参数调用子查询。
-
b.将子查询结果扁平化为所有订单的单个流。
-
c.收集结果。
3.返回与查询匹配的所有订单的列表。
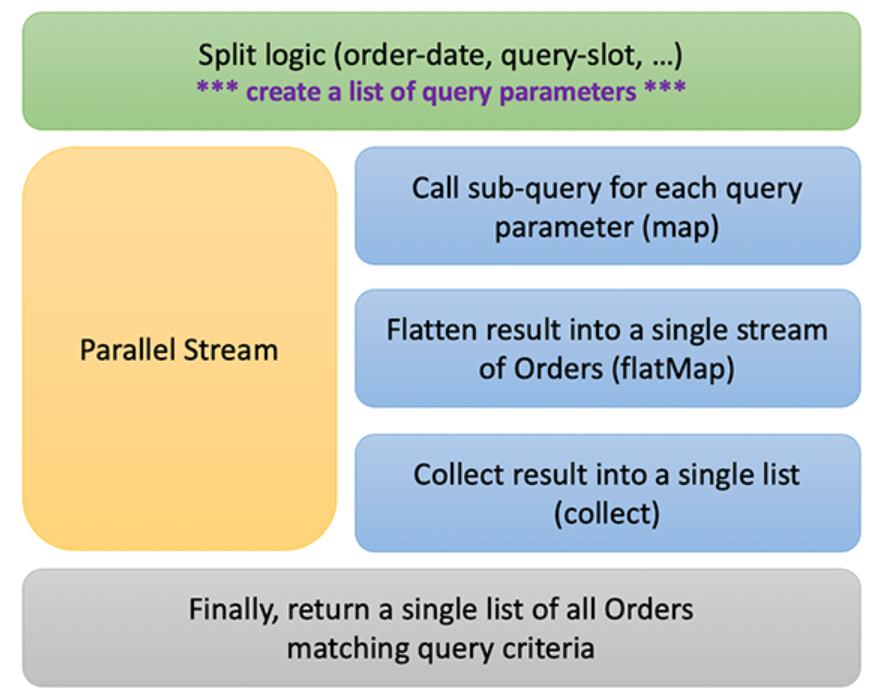
图6–使用Java Streams设计并行查询执行
以下代码显示了用于收集订单的多个并行流的实现:
List<Order> getOrdersByCategoryAndDateUsingParallelStream(final String category) {
List<String> yearMonthsList = IntStream.rangeClosed(1, 12)
.mapToObj(x -> String.format("2020-%02d", x))
.collect(Collectors.toList());
List<Order> orders = yearMonthsList.parallelStream()
.map(x -> listOrdersByCategoryAndOrderDate(category, x))
.flatMap(Collection::stream) // flatten results into a single stream of Orders
.unordered() // do not insist to preserve input order (might be faster)
.collect(Collectors.toCollection(() ->
Collections.synchronizedList(new ArrayList<>())));
return orders;
}List<Order> getOrdersByCategoryAndDateUsingParallelStream(final String category) {
List<String> yearMonthsList = IntStream.rangeClosed(1, 12)
.mapToObj(x -> String.format("2020-%02d", x))
.collect(Collectors.toList());
List<Order> orders = yearMonthsList.parallelStream()
.map(x -> listOrdersByCategoryAndOrderDate(category, x))
.flatMap(Collection::stream) // flatten results into a single stream of Orders
.unordered() // do not insist to preserve input order (might be faster)
.collect(Collectors.toCollection(() ->
Collections.synchronizedList(new ArrayList<>())));
return orders;
}
以下是用于列出订单的主要DynamoDB查询的代码:
public List<Order> listOrdersByCategoryAndOrderDate
(final String category, final String orderDate) {
if (Utils.checkIfNullOrEmptyString(category)) return new ArrayList<>();
DynamoDBMapperConfig mapperConfig = getDefaultMapperConfig(DDB_TABLE_NAME);
Map<String,String> names = new HashMap<>();
Map<String,AttributeValue> values = new HashMap<>();
names.put("#cat", "category");
values.put(":cat", new AttributeValue().withS(category.trim().toUpperCase()));
String keyCondExpr = "#cat = :cat";
String indexName = "category-order-date-index";
if (StringUtils.isNotEmpty(orderDate)) {
names.put("#od", "order-date");
values.put(":od", new AttributeValue().withS(orderDate.trim()));
keyCondExpr += " AND begins_with(#od, :od)";
}
DynamoDBQueryExpression<Order> queryExpr = new DynamoDBQueryExpression<Order>()
.withKeyConditionExpression(keyCondExpr)
.withIndexName(indexName)
.withExpressionAttributeNames(names)
.withExpressionAttributeValues(values)
.withScanIndexForward(false)
.withConsistentRead(false);
return this.dbMapper.query(Order.class, queryExpr, mapperConfig);
}
重要提示:要为本文讨论的方法设计最佳解决方案,在选择数据拆分策略时必须考虑以下几点:
-
查询所针对的数据总量(数千、数百万或数十亿条记录)。
-
计算环境的类型(较小或较大数量的内核)。
-
子查询的类型(按字符串前缀或数值搜索)。
-
子查询数。
-
每个子查询的数据大小的潜在一致性。
-
可用于给定计算环境的线程数。
还有其他性能注意事项,例如记录大小(查询返回的字段数)和应用于查询记录的筛选器表达式。
在测试过程中,我观察到,在并行流实现中使用公共ForkJoin线程池时,由于等待线程可用的队列任务的数量较多,因此在执行大量并行查询时,性能较差。在这种情况下,拥有更多的内核对于整体解决方案性能来说是一个巨大的提升,特别是当进程受到I/O限制时。
Java工具集中的下一个工具是Completablefutures,它是一个反应式异步功能框架,允许您提供定制线程池。可完成的未来允许您为环境和您需要解决的问题创建尽可能多的线程。此外,重要的是要知道Java v2的SDK大量使用可完成的未来和反应流。我将在本文后面讨论SDK v2。
CompletableFuture异步框架
CompletableFuture类是一个相对较新的Java范例。它是在Java8中引入的,有大约50种不同的方法来组合、组合和运行异步计算步骤和处理错误。它对CompletionStage的使用尤其有用,它支持在完成时触发的相关函数和操作。
我用于查询数据并将其拆分为12个月的集合的代码如下所示:
public List<Order> getOrdersUsingCategoryAndDateQueryWithCompletableFuture(final String category) {
// this changes depending on the sub-queries we plan to run (here: 12)
ForkJoinPool executorService = new ForkJoinPool(12);
// this is a place where we create date prefixes, either monthly (12), 4 per month (48),
// or daily splits (365/366)
List<String> yearMonthsList = IntStream.rangeClosed(1, 12)
.mapToObj(x -> String.format("2020-%02d", x))
.collect(Collectors.toList());
// invoke async queries and create futures
List<CompletableFuture<List<Order>>> listFutures = yearMonthsList.stream()
.map(x -> CompletableFuture.supplyAsync(() ->
listOrdersByCategoryAndOrderDate(category, x), executorService))
.collect(Collectors.toCollection(() ->
Collections.synchronizedList(new ArrayList<>())));
// wait for the completion and retrieve final list of Orders as a list
List<Order> list = listFutures.stream()
.map(CompletableFuture::join)
.flatMap(Collection::stream)
.collect(Collectors.toCollection(() ->
Collections.synchronizedList(new ArrayList<>())));
return list;
}
代码显示了一个简单的Future收集步骤,但要获得更好的方法,请参阅Douglas C Schmidt的Understand Advanced Java Completable Future Features:Implementation FuturesCollector。
我选择创建自己的ForkJoin池线程,线程数与子查询数相匹配,订单日期方法为-12、48或365,查询槽案例为64。我使用与并行流实现相同的子查询代码。
无论是使用订单日期还是query-slot-mod64方法,前面的代码都会执行相同的操作:
-
提供拆分数据的条件(如日期前缀或查询槽值)。
-
遍历每个值并提交异步子查询。
-
返回可完成未来的列表。
-
加入所有未来并等待其完成。
-
扁平化所有结果并收集最终订单列表。
虽然我在本文中只展示了带有返回订单列表的基本操作,但您可以使用已经建立的线程池和CompletableFuture登台方法在同一线程中处理每个结果。
测试结果
在本节中,我将讨论我的方法、测试结果和Javav2的SDK。
方法论
我用大约270000条记录填充了DynamoDB表。以下是订单记录的示例:
{
"category":"ELECTRONICS",
"ck-country-state":"USA#MA",
"comment":"anything here … ",
"country":"USA",
"id":"0df39ec1-0437-435a-989f-bd8085e6b3ff",
"order-date":"2020-05-04",
"payment-type":"CREDIT",
"qty":8,
"query-slot-mod64":57,
"sku":"A-026",
"state":"MA",
"unit-price":7.44
}
然后我运行了九个不同的测试用例:
-
单个查询,不拆分为任何子查询。
-
如前所述,并行流方法使用12、48和365个子查询的公共ForkJoin池。
-
一个并行流测试,使用queryslot-mod64属性创建64个子查询。
-
如前所述,使用CompletableFuture和ForkJoin线程池处理12、48和365个子查询的顺序流方法。
-
使用CompletableFuture的顺序流方法,使用用户提供的ForkJoin线程池,使用queryslot-mod64属性和64个子查询。
我将每个测试用例运行10次,并平均每个用例的总时间。我使用两种设置运行每个测试:
-
基本的Amazon Elastic Compute Cloud(Amazon EC2)设置。
-
一个更好的Amazon EC2设置,类似于生产环境中可能使用的设置。
对于基本测试,我使用了一个具有4个vCPU和16 GB RAM的t2.xlarge EC2实例。为了更好地表示真实的生产环境,我使用了一个带有96个vCPU和384 GB RAM的m5.24xlarge EC2实例。使用并行流和公共ForkJoin的实现依赖于底层线程池大小,而CompletableFuture实现针对测试用例所需的线程数进行了优化。
结果和观察结果
下表总结了在DynamoDB表中查询2020年类别为SPORT的所有记录的结果。
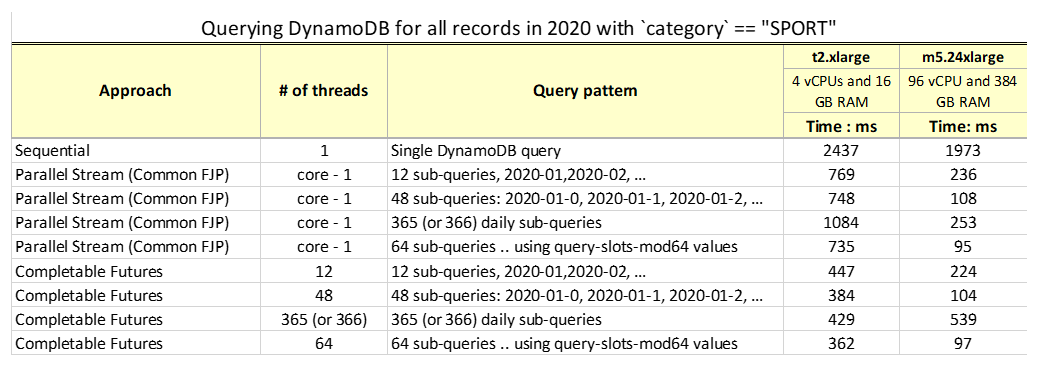
虽然结果很直观,但当您使用数据尝试解决方案时,您可能会发现以下观察结果很有用:
-
在某些情况下,单个查询的性能要比对子查询使用并行性慢近20倍。
-
即使是最受约束的环境,并行性也比单线程执行得好。
注意:您的AWS Lambda函数也可能从这种并行性中受益。
-
将具有约束的环境与健壮的环境(如具有更多核心的环境)进行比较,结果显示出显著的差异。
-
如t2机器和365线程所示,大量子查询可能会降低功能较低的机器上的性能,这些机器具有通用的ForkJoin线程池实现。
-
指定线程池中的线程数有助于提高性能,即使是在受限环境(如t2环境)中也是如此。
-
在功能更强大的EC2实例上,具有公共ForkJoin池的并行流与使用CompletableFuture和用户定义的线程池大小具有相似的性能结果。这在96个vCPU的测试中很明显,其中大多数情况下需要更少的CPU,因此与选择线程池大小的方法相比,普通ForkJoin没有任何缺点。
-
与begin_with()函数进行比较时,数字排序键比较比使用订单日期前缀更快。
-
对于我们的数据大小和测试用例,线程池大小在48到64之间时,所有环境的性能都最佳。
-
分配了查询时隙值的模查询模式在实时数据分布不均匀(如假日购物等季节性变化)的情况下可能性能更好,但需要统一分布来优化多个并行子查询的性能。
-
您的DynamoDB系统需要根据读取容量和吞吐量适当调整大小。构建更多并行性可能会带来成本影响。
-
总之,无论底层环境如何,使用多线程方法获得的结果都令人印象深刻。对于大多数用例来说,在100到360毫秒内返回270000条记录是一个不错的结果。
用于Java v2的AWS SDK
虽然我在这篇文章中主要讨论了Java v1的SDK,但现在正是讨论反应式编程范式和AWS Java v2 SDK带来的新思想的好时机,您可以在将来使用它们。在这篇文章中,我没有深入讨论反应式编程概念的细节,因为有大量关于这个主题的文献,但在这一节中,我分享了一个如何使用推模型以及如何使用异步从DynamoDB获取数据的示例。
新的AWS SDK for Java 2.x提供了实现反应流的API和一个可观察的接口,允许事件和数据的使用者订阅流,从而无需向服务提供商轮询事件或数据。有关此范例的示例,请参阅AWS SDK For Java v2 GitHub存储库。
对于我们的示例,我使用以下代码创建了DynamoDB客户端的异步版本:
this.dynamoDB = DynamoDbAsyncClient.builder()
.region(Region.US_EAST_1)
.credentialsProvider(ProfileCredentialsProvider.builder()
.profileName("default")
.build())
.build();
this.enhancedDynamoDB = DynamoDbEnhancedAsyncClient.builder()
.dynamoDbClient(this.dynamoDB).build();
我可以使用DynamoDB中的查询结果发布器和消费逻辑以及一个流行的外部库来处理反应流,如Project Reactor或RxJava(在下面的示例中使用)来建模查询:
public List<Order> getOrdersListByCategoryAndOrderDate
(final String category, final String orderDate) {
if (Utils.checkIfNullOrEmptyString(category)) return new ArrayList<>();
DynamoDbAsyncIndex<Order> index = this.table.index("category-order-date-index");
QueryConditional queryConditional = QueryConditional
.sortBeginsWith(k -> k.partitionValue(category.trim().toUpperCase())
.sortValue(orderDate.trim()).build());
Publisher<Page<Order>> publisher = index.query(queryConditional);
List<Order> orders = Flowable.fromPublisher(publisher)
.flatMapIterable(Page::items)
.toList()
.blockingGet();
System.out.printf(" >> Category: [%s], date prefix: [%s], orders list size: %d%n",
category, orderDate, orders.size());
return orders;
}
下面是一个简单的代码片段,它将所有子查询合并到一个结果中,类似于我对常规并行流和AWS SDK for Java v1所做的操作:
Public List<Order> getOrdersByCategoryAndDateUsingReactiveStream(final String category) {
List<String> yearMonthsList = FastOrderQuery.generate48YearMonthDatePrefixes(2020);
List<Order> orders = yearMonthsList.stream()
.map(x -> getOrdersListByCategoryAndOrderDate(category, x))
.flatMap(Collection::stream) // flatten results into a single stream of Orders
.unordered() // do not insist to preserve input order (might be faster)
.collect(Collectors.toCollection(() ->
Collections.synchronizedList(new ArrayList<>())));
return orders;
}
反应式编程,结合我在本文中讨论的其他主题,是一个令人兴奋的探索领域。反应式方法允许我们在事件到达时处理事件,通过不等待所有数据可用来加快处理速度。最重要的是,它隐藏了并行进程之间线程、阻塞和同步的底层复杂性。
结论
这篇文章强调了并行的力量。我讨论了DynamoDB查询系统以及将查询拆分为可以独立并行运行的多个子查询的方法。除了解决DynamoDB查询解决方案之外,我还向您展示了使用并行流和公共ForkJoin池的Java代码,以及如何使用具有定义的线程池大小的CompletableFuture。相比之下,我向您展示了一种使用AWSSDKforJavav2的方法和一种反应式编程方法来处理异步和提供数据的发布者使用的推送模型。
结果表明,将单个大型查询拆分为多个子查询可以显著提高性能。在决定实现步骤之前,最好使用数据、计算环境和查询模式进行测试。虽然我讨论了两种方法(使用日期和查询槽),但有几种方法可以实现类似的查询模式,如按不同国家、州、邮政编码、产品类别等进行查询。任何具有有限基数的对象都是子查询拆分的好选择,因为您需要在运行查询之前确定线程池大小。
最后,在较小的块中检索数据可以立即进行处理,而无需等待返回所有数据。
您可以在GitHub上找到本文中提到的代码。请随意测试。项目包含README.md,涵盖成功运行代码所需的所有细节和要求。
关于作者

Zoran Ivanovic是加拿大AWS专业服务公司的大数据首席顾问。在领导Amazon最大的大数据团队之一5年后,他来到AWS,与有兴趣利用AWS服务在云中构建关键任务系统的大型企业客户分享他的经验。
原文标题:Use parallelism to optimize querying large amounts of data in Amazon DynamoDB
原文作者:Zoran Ivanovic
原文链接:https://aws.amazon.com/blogs/database/use-parallelism-to-optimize-querying-large-amounts-of-data-in-amazon-dynamodb/
