




线程
首先讲一下python中的全局解释器
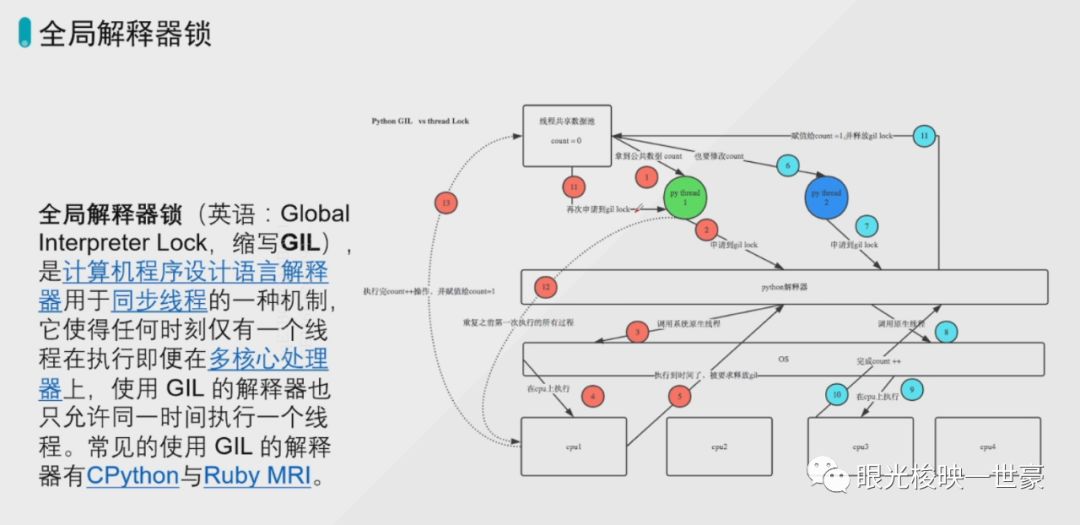
step1:create一个线程
step2:去JPython解析器中申请一个GRL锁,只有一把锁,只有申请到了才能去执行。(如同你在等我表白,我也在等你表白一样,如果不交出钥匙,是不会有故事的。)
step3:OS(申请原生线程)
step4:线程在cup里面执行,如果外面还有别的线程要进来,只能在外面等待,因为只有一把锁。
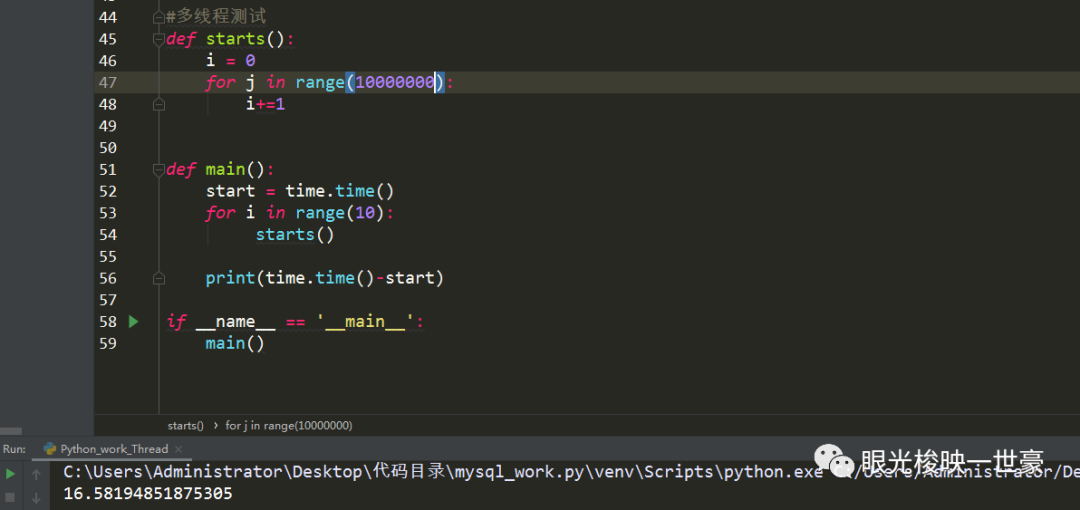
现在测试一下CPU密集型
以下这个为单线程裸跑:
10个线程,你会发现并没有任何优势
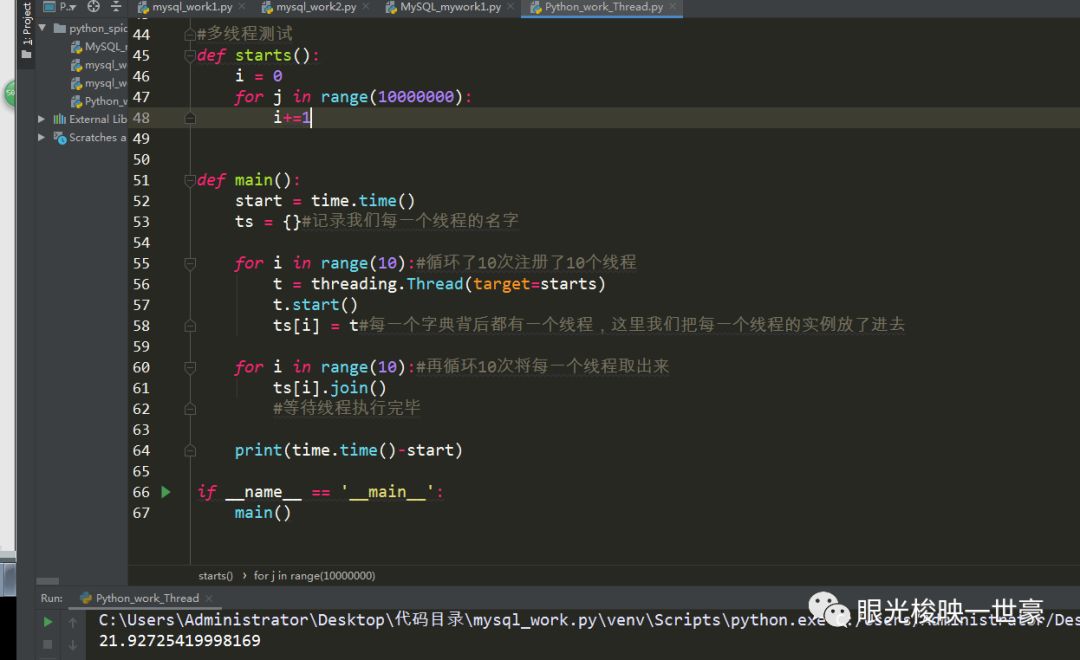
通过计算机原理来解释的话,我们计算机都是通过CPU来进行加减乘除的操作,这个时候由于Python的GIL的存在,的的确确只有一个线程,所以即使开了10个进程,也没有什么作用。这就是计算密集型了。
计算密集型和IO密集型
第一种任务的类型是计算密集型任务,其特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
原文链接:
https://blog.csdn.net/m0_37338590/article/details/83897869
原创:Jonny工作室
那么我们应该如何避免GIL呢?

每个进程都是独立的,就像谷歌浏览器和有道云笔记这两个运用是不会有什么关联的。
接下来讲解一下多线程和非守护线程
运行开始:
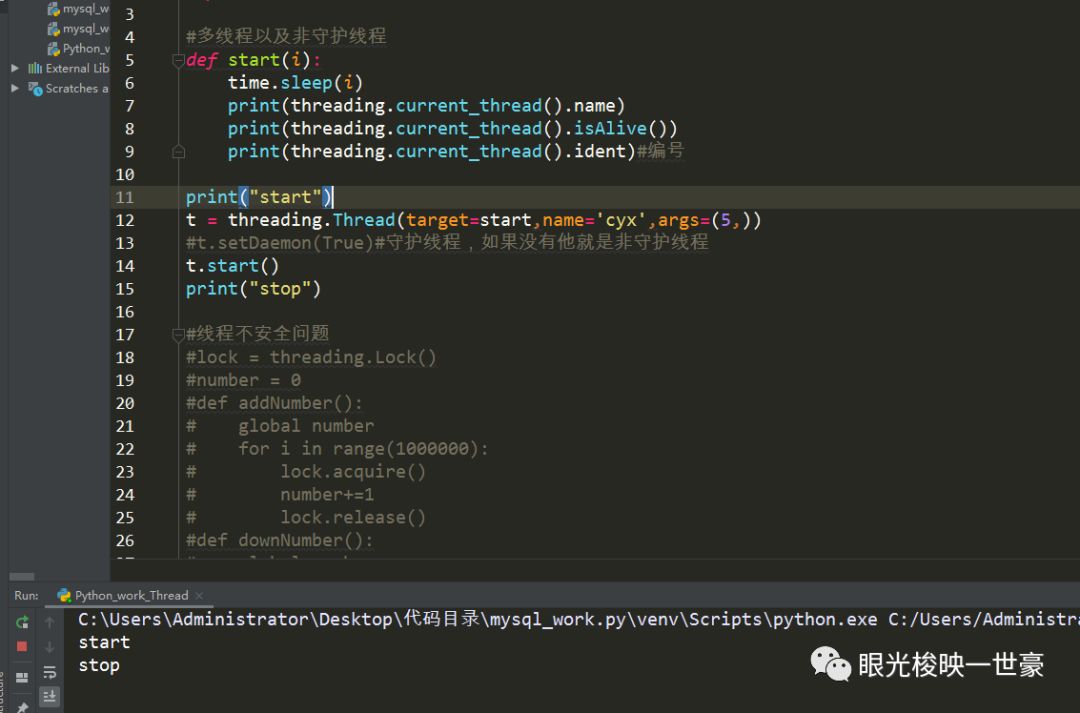
主线程先执行完毕,这种不会随着主线程的结束而销毁的线程叫做非守护线程,你看:
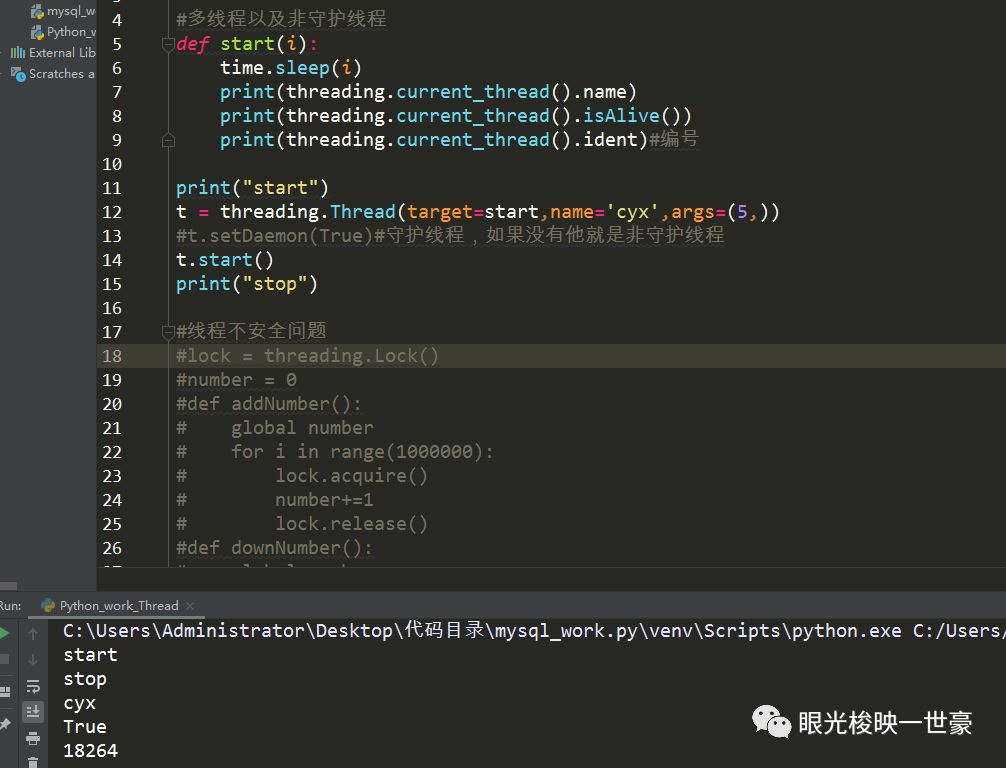
程序运行完了~!
守护线程(一般不用)就是会随着主线的结束而结束,代码就是加一行:
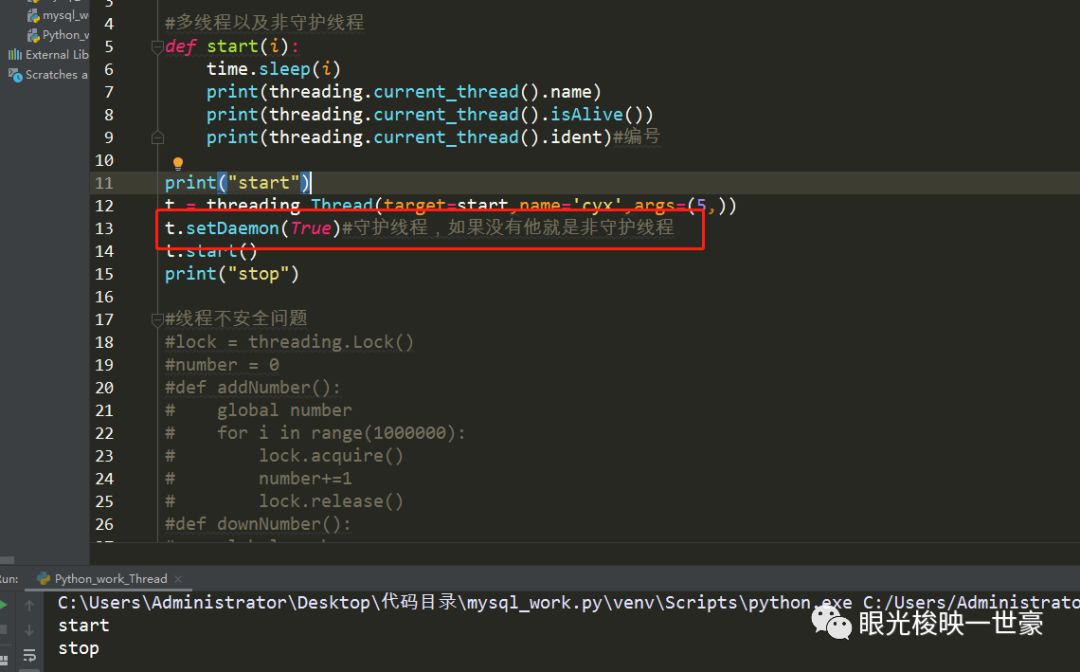
没错,主线程执行完毕后,线程内的内容是不会变的。
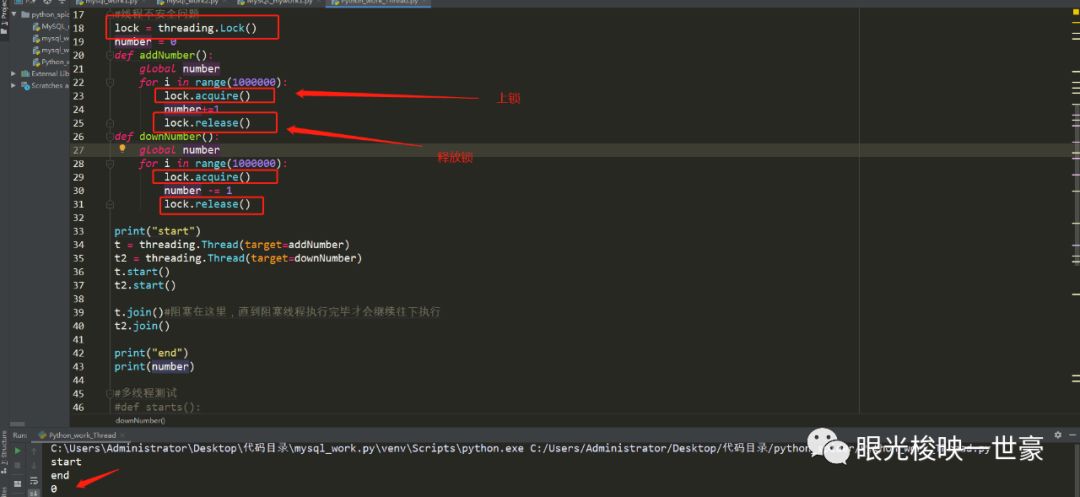
线程不安全问题
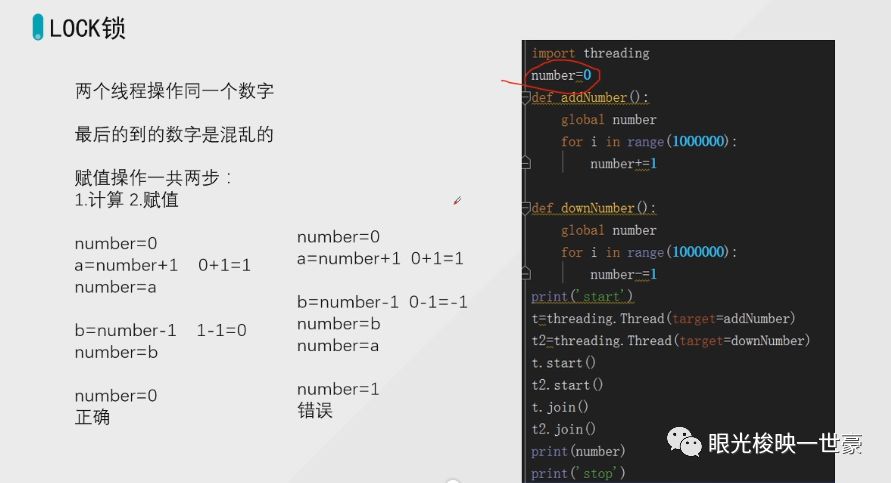
按照逻辑来说,加一百万次减一百万次应该是为0才对,可是得出的是一个随机的数字,这是为什么呢?
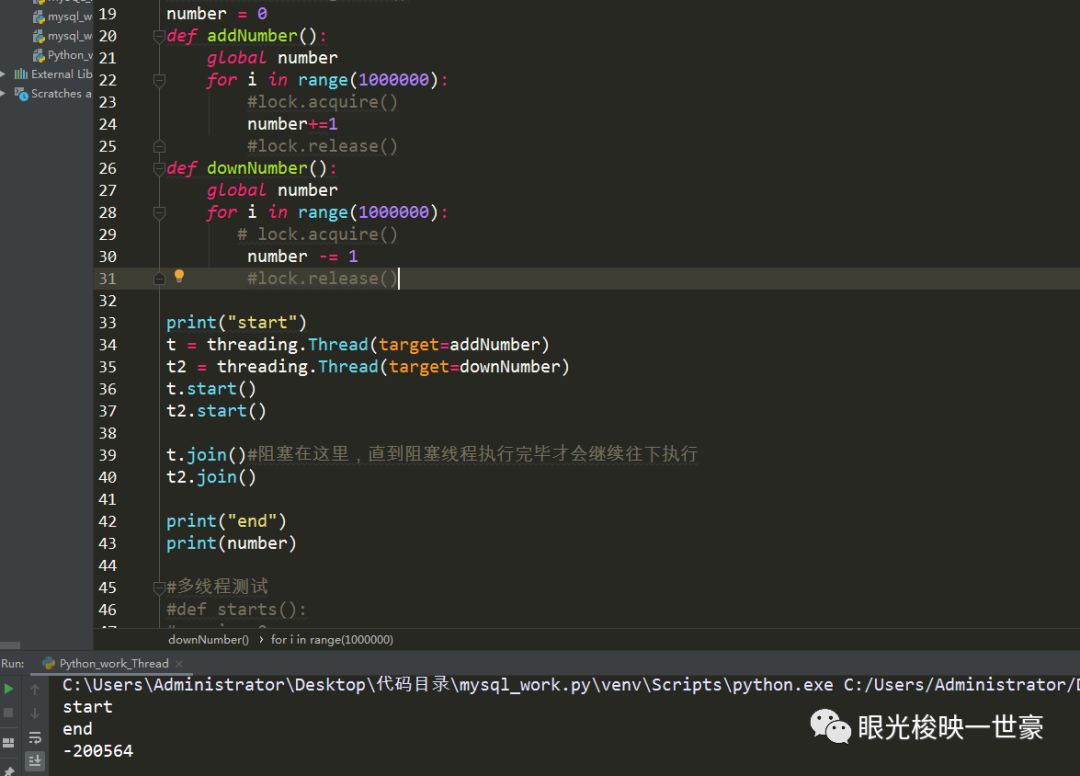
这就是线程不安全问题,赋值和计算是分两步进行的,为了避免这样的错误,我们可以创建一个锁,把加减赋值操作锁起来,加的加完,减的减完,这样就不会出现错误了。
当然,还有一个更低精度的递归锁,锁里面套着锁,这样在大工程,在那种几万行的代码内才有可能会用到这种递归锁,这里就先不讲解了。
多线程呢就是我们的io密集型,在我们运行爬虫的时候是很有帮助的,在机器学习里面就很少看见多线程的东西了
多进程
一般我们的爬虫策略就是多进程加多线程,这样的效果是最好的。
上文已经讲过了,进程之间是不会有相互联系的,所以,我们需要自己借助其他的数据结构来他们之间创建一定的联系。
运行之后:
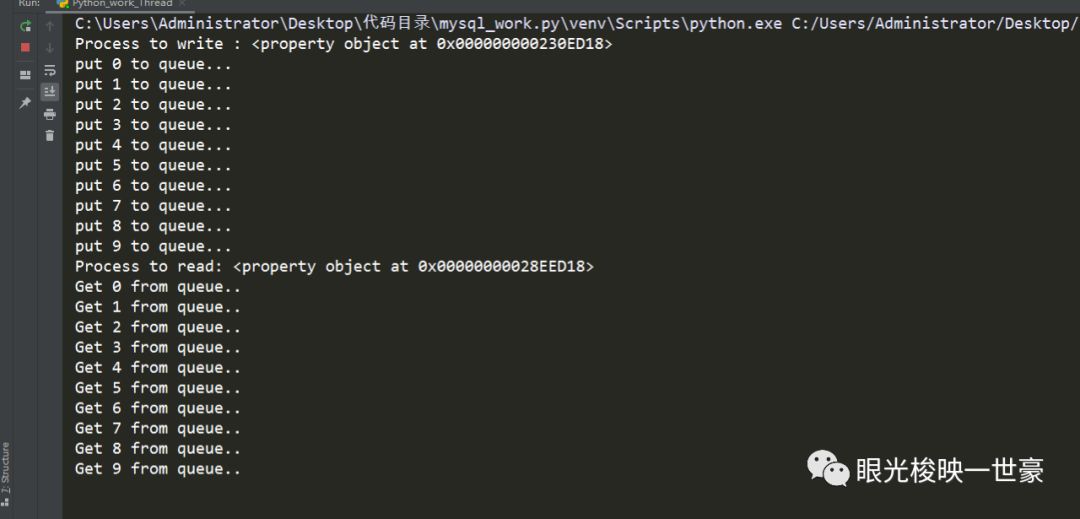
可以第一个进程解析url 第二个就是request.get这些url这样的效率是非常高的
进程池
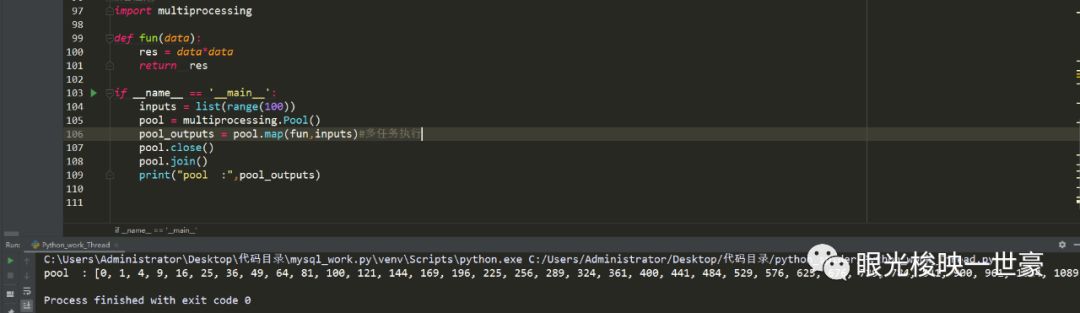
线程池
是个线程,如果是单线程 执行这个代码需要30秒。但是我开了10个线程,一起爬虫,大约就是3秒钟,这样大大的增加了爬虫的效率。
今日代码分享:
import threading import time #多线程以及非守护线程 #ef start(i): # time.sleep(i) # print(threading.current_thread().name) # print(threading.current_thread().isAlive()) # print(threading.current_thread().ident)#编号 #rint("start") # = threading.Thread(target=start,name='cyx',args=(5,)) #.setDaemon(True)#守护线程,如果没有他就是非守护线程 #.start() #rint("stop") #线程不安全问题 #lock = threading.Lock() #number = 0 #def addNumber(): # global number # for i in range(1000000): # lock.acquire() # number+=1 # lock.release() #def downNumber(): # global number # for i in range(1000000): # lock.acquire() # number -= 1 # lock.release() # #print("start") #t = threading.Thread(target=addNumber) #t2 = threading.Thread(target=downNumber) #t.start() #t2.start() # #t.join()#阻塞在这里,直到阻塞线程执行完毕才会继续往下执行 #t2.join() # #print("end") #print(number) #多线程测试 #def starts(): # i = 0 # for j in range(10000000): # i+=1 # # #def main(): # start = time.time() # ts = {}#记录我们每一个线程的名字 # # for i in range(10):#循环了10次注册了10个线程 # t = threading.Thread(target=starts) # t.start() # ts[i] = t#每一个字典背后都有一个线程,这里我们把每一个线程的实例放了进去 # # for i in range(10):#再循环10次将每一个线程取出来 # ts[i].join() # #等待线程执行完毕 # # print(time.time()-start) # #if __name__ == '__main__': # main() #进程之间的通信 from multiprocessing import Process,Queue#进入进程 import time #def write(q): # print("Process to write : %s" %Process.pid) # for i in range(10): # print("put %d to queue..." %i) # q.put(i) # #def read(q): # print("Process to read: %s" % Process.pid) # while True: # value = q.get() # print("Get %d from queue.." % value) # #if __name__ == '__main__': # q = Queue() # pw = Process(target = write,args=(q,)) # pr = Process(target = read,args=(q,)) # # pw.start() # pr.start() # # pw.join() #进程池 #import multiprocessing # #def fun(data): # res = data*data # return res # #if __name__ == '__main__': # inputs = list(range(100)) # pool = multiprocessing.Pool() # pool_outputs = pool.map(fun,inputs)#多任务执行 # pool.close() # pool.join() # print("pool :",pool_outputs) #线程池(当你执行比较耗时的操作时,需要开启多线程 import threadpool def get_html(url): time.sleep(3) print(url) urls = [i for i in range(10)] print(urls) pool = threadpool.ThreadPool(10)#建立线程池 #提交任务给线程池 requests = threadpool.makeRequests(get_html,urls) #开始执行任务 for req in requests: pool.putRequest(req) pool.wait()#等待执行完毕
今日鸡汤:
出自:2019-2020时间的朋友”罗振宇跨年演讲将全球直播
链接:https://www.hula8.net/article/39980.html
预测未来的最好办法,就是创造未来!
