




基于规则的优化器(rbo,rule based optimizer) 在上古版本中的数据库较为常见,比如过去常听DBA说的SQL语句驱动表要放前面,被驱动表要放后面之类的云云,听的好像很深奥,究其本质为数据库引擎按照固定规则去优化执行计划;这样的规则往往较为简单比如是否有索引、驱动表是否在前等等。 举个例子,汽车导航中始发地到目的地之间有多种路线,rbo中就是按距离规则来计算,不考虑实际路况比较傻瓜化,现在基本都已经淘汰。
基于成本的优化器(cbo,cost based optimizer) 同样的汽车导航例子,cbo中还需要参考路况是否存在堵车,是否存在限速等等,通过对比各种行程的耗时从而选择最合适的路线。在数据库中就是通过对比各种不同计划(是采用hashjoin 还是nestloop,采用全表扫描还是索引扫描等等)的估算开销(cost), 从中选择开销(cost)最低的计划,相对RBO的呆板,CBO显得较为智能,目前主流数据库均采用CBO模式。
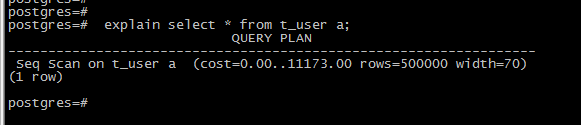
由于这个查询没有WHERE子句,它必须扫描表中的所有行,因此计划器只能选择使用一个简单的顺序扫描计划。被包含在圆括号中的数字是(从左至右):
0.00,估计的启动开销。在输出阶段可以开始之前消耗的时间。 11173.00,估计的总开销。这个估计值基于的假设是计划结点会被运行到完成,即所有可用的行都被检索。 rows=500000,这个计划结点输出行数的估计值。同样,也假定该结点能运行到完成。 width=70,预计这个计划结点输出的行平均宽度(以字节计算)。
这里涉及了postgresql几个参数:
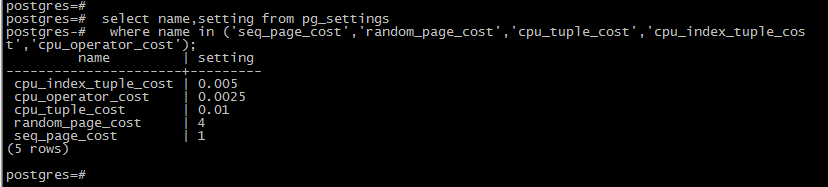
seq_page_cost:连续块扫描操作的单个块的cost. 例如全表扫描. random_page_cost:随机块扫描操作的单个块的cost. 例如索引扫描. cpu_tuple_cost:处理每条记录的CPU开销(tuple:关系中的一行记录). cpu_index_tuple_cost:扫描每个索引条目带来的CPU开销. cpu_operator_cost:操作符或函数带来的CPU开销.

1*6173+0.01*500000 =11173;与前文Cost值11173对应。

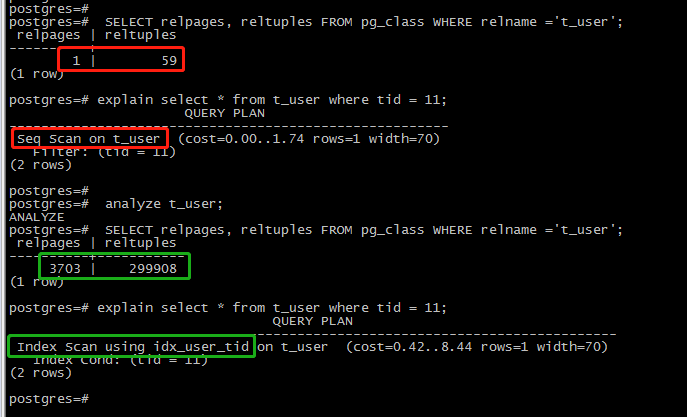
注:
Cost全表=1* 4+ 59*0.01 = 4.59,与图中估算值1.74存在些许差异.
Cost索引=2*4+0.01+0.25=8.26,与图中估算值8.44存在些许差异.
由于全表Cost比索引Cost低,则CBO优化器将选择全表扫描方式.
注:
Cost全表=3703*4 + 299908*0.01 =15111;大致估算值. Cost索引=2*4+0.01+0.25=8.26,与图中估算值8.44存在些许差异. 由于索引Cost比全表Cost低,则CBO优化器将选择索引扫描方式.
PostgreSQL的统计收集器是一个支持收集和报告服务器活动信息的子系统。目前这个收集器可以对表和索引的访问计数,计数可以按磁盘块和个体行来进行。它还跟踪每个表中的总行数、每个表的清理和分析动作的信息。它也统计调用用户定义函数的次数以及在每次调用中花费的总时间。因为统计信息的收集给系统增加了一些额外负荷,系统可以被配置为自动收集或部分收集或不收集信息。这由配置参数控制,如下:
track_activities允许监控当前被任意服务器进程执行的命令。 track_counts 控制是否收集关于表和索引访问的统计信息。 track_functions启用对用户定义函数使用的跟踪。 track_io_timing启用对块读写次数的监控。
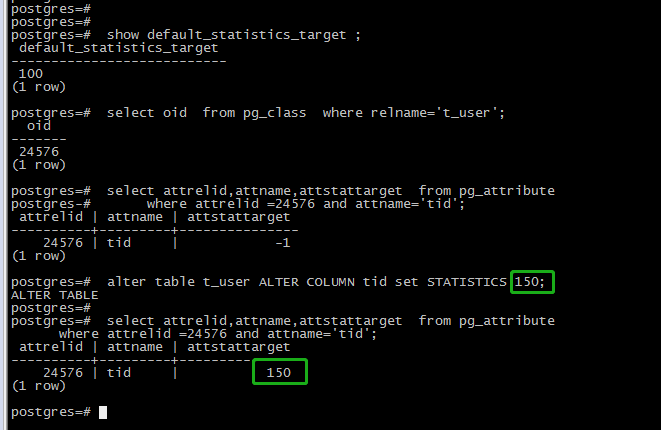
一旦指定列的statistics值后,PostgreSQL就不再参考默认的default_statistics_target值,它会先去系统表pg_attribute的对应表对应字段的attstattarget值:
如果是-1,表示的是该列的取样颗粒度是采用默认的值(default_statistics_target); 如果是大于0的,那么就表示是使用着自己手动定义的。
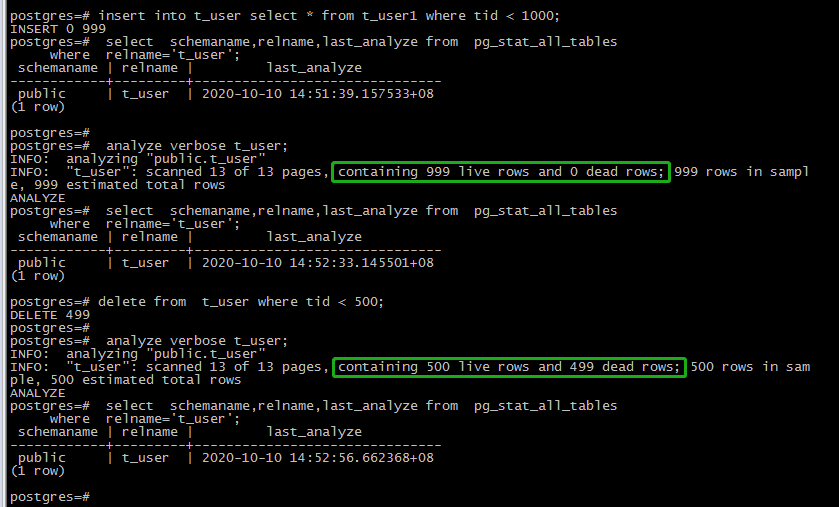
比如我们修改t_user.tid通过STATISTICS150,查看attstattarget值的变化:

本文作者:胡 杰(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
