




OceanBase 数据库的 Cache 设计与 Oracle、MySQL 相比有很大的不同。由于 OceanBase 数据库的存储引擎是基于 LSM-tree 架构的,所有的修改只会写入 MemTable,而 SSTable 是只读的,这就意味着 OceanBase 数据库的 Cache 是一个只读 Cache,没有刷脏页的相关逻辑,这相对于传统数据库来说会简单一些;但同时我们对存储在 SSTable 内的数据会进行数据编码和压缩,这意味着我们需要存储的数据是变长而非定长的,和传统数据库相比 Cache 的内存管理又要复杂很多。除此之外,OceanBase 数据库还是一个面向多租户的分布式数据库系统,除了和传统数据库一样要处理 Cache 的内存淘汰之外,在 Cache 内部还需要进行多租户的内存隔离。
和 Oracle 与 MySQL 类似,在 OceanBase 数据库内部,也会有很多种不同类型的 Cache,除了用于缓存 SSTable 数据的 Block Cache(类似于 Oracle 和 MySQL 的 buffer cache)之外,还有 row cache(用于缓存数据行)、log cache(用于缓存 redo log)、location cache(用于缓存数据副本所在的位置)、schema cache(用于缓存表的 Schema 信息)、bloom filter cache(用于缓存静态数据的 bloomfilter,快速过滤空查)等等。OceanBase 数据库设计了一套统一的 Cache 框架,所有不同租户的不同类型的 Cache 都由框架统一管理。对于不同类型的 Cache,会配置不同的优先级,不同类型的 Cache 会根据各自的优先级以及数据访问热度做相互挤占;对于不同租户,会配置对应租户内存使用的上限和下限,不同租户的 Cache 会根据各自租户的内存上下限以及 Server 整体的内存上限做相互挤占。
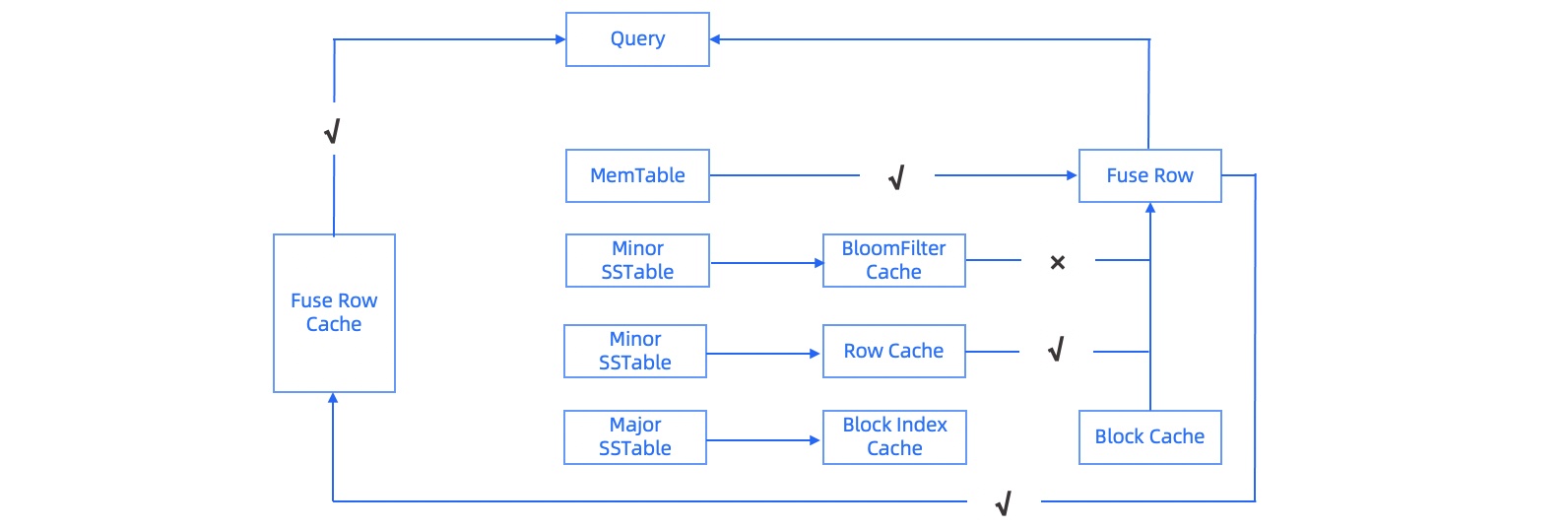
上图以一个典型的 table get 示例了 OceanBase 数据库中目前服务于查询流程的各种 cache。
BloomFilter Cache
OceanBase 数据库的 BloomFilter 是构建在宏块上的,根据用户实际空查率按需自动构建,当一个宏块上的空查次数超过某个阈值时,就会自动构建 BloomFilter,并将 BloomFilter 放入 Cache。
Row Cache
针对每个 SSTable 缓存具体的数据行,在进行 Get/MultiGet 查询时,可以将对应查到的数据行放入 Row Cache,这样在下次走到对应行查询时就可以避免多次二分定位对行的查找。
Block Index Cache
缓存微块的索引,因为每个 SSTable 虽然以宏块组织,但是 2M 的粒度对于用户查询来说往往粒度太大,因此需要根据用户查询的范围在宏块中定位实际需要的微块,微块索引就是描述对每个宏块中所有的微块的范围,当需要访问某个宏块的微块时,需要提前装载这个宏块的微块索引,因为进行了前缀压缩,因此大小通常较小,并且在 OceanBase 数据库内部给予其较高优先级,因此一般命中率较高。
Block Cache
类似于 Oracle 的 Buffer Cache,缓存具体的数据微块,每个微块都会解压后装载到 Block Cache 中, 因此每个 cache 大小都是变长的。
Fuse Row Cache
在 LSM-Tree 架构中, 同一行的修改可能存在于不同的 SSTable 中,OceanBase 数据库为了进一步优化存储占用,每次用户的更新都只会存储增量数据,因此在查询时需要对各个 SSTable 查询的结果进行熔合,当用户不再触发新的更新时,这个熔合结果对查询都是一直有效的,因此 OceanBase 数据库也提供了对于熔合结果缓存的 Fuse Row Cache,更大幅度支持部分用户的热点行查询。
OceanBase 数据库除了以上用户查询相关的多级缓存之外, 还支持多种更多不同类型的 cache,例如:
Partition Location Cache:用于缓存 Partition 的位置信息,帮助对一个查询进行路由。
Schema Cache:缓存数据表的元信息,用于执行计划的生成以及后续的查询。
Clog Cache:缓存 clog 数据,用于加速某些情况下 Paxos 日志的拉取。
......
为了能够更加通用的支持这么多种类的 Cache,需要处理变长数据的问题,OceanBase 数据库的底层 Cache 框架将内存划分为多个 2MB 大小的内存块,对内存的申请和释放都以 2MB 为单位进行。变长数据被简单 pack 在 2MB 大小的内存块内。为了支持对数据的快速定位,在 Hashmap 中存储了指向对应数据的指针,整体结构如下图所示。
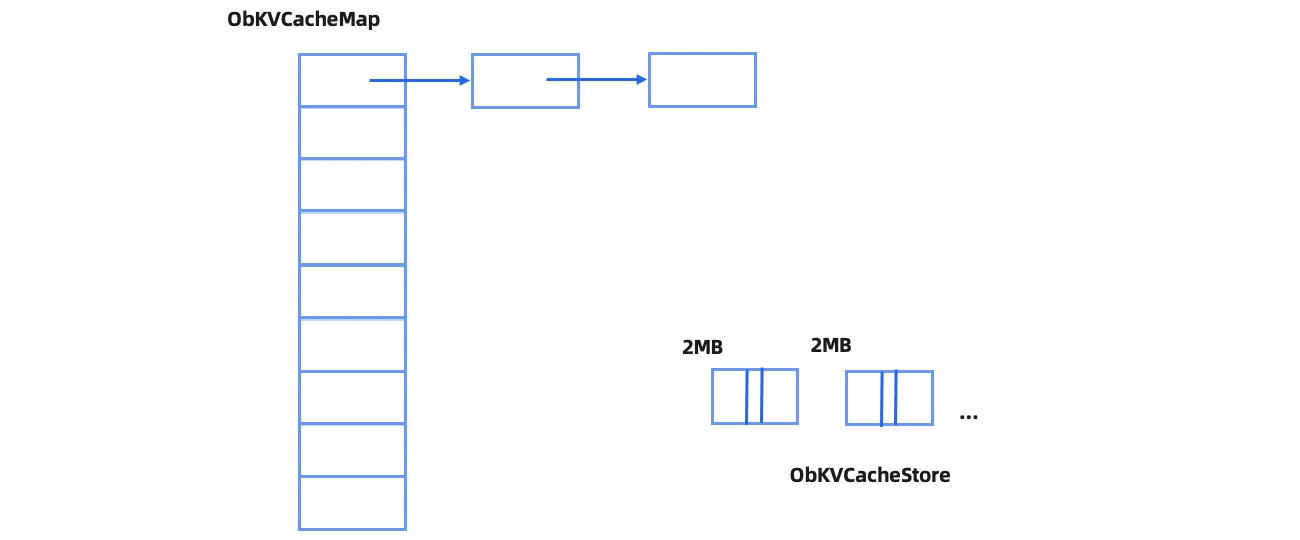
Cache 内存是以 2MB 为单位整体淘汰的,OceanBase 数据库会根据每个 2MB 内存块上各个元素的访问热度为其计算一个分值,访问越频繁的内存块的分值越高,同时有一个后台线程来定期对所有 2M 内存块的分值做排序,淘汰掉分值较低的内存块。对于一个整体分值不高但是内部存在热点数据的 2MB 内存块,OceanBase 数据库会将其热点数据从它所在的"冷块"移动到"热块"中,避免热点数据被淘汰。在数据结构上并没有维持类似于 Oracle 和 MySQL 的 LRU 链表,因此对于数据读取,OceanBase 数据库的 Cache 访问几乎是无锁的(除了 HashMap 上的 Bucket 锁之外),对于热点数据的高并发访问更加友好。在淘汰时,我们会考虑租户的内存上限及下限,控制各个租户中 Cache 内存的用量。
