





说明:记录下前段时间一次印象比较深的Oracle DBA面试经历,为什么印象比较深呢,因为全程都是被按在地上摩擦的,暴露出很多技术盲点,之前对很多技术细节不求甚解,解决掉一个问题后,没有去深究问题的根本原因,总想着以后有时间再去研究。
之前面试官已经看过简历了,没有自我介绍环节,直接开始第一个问题:

1 说下你处理过比较有难度的一次故障
这个问题实际上是想看下我擅长的领域、对问题的理解、知识的深度等。
我说了一个4,5年前处理的一个案例,确实是我印象最深的,一个OLAP类型的数据库宕机了,刚接手的数据库无备份,周五晚上出现宕机,历时两天时间,在周一早上我才将故障搞定。
故障大概是因为undo段头块损坏导致数据库宕机,因为数据库同时有5个以上的用户在执行impdp操作,大量的数据加载,undo一直处于繁忙状态。无备份情况下是可以通过_corrupted_rollback_segments跳过损坏段启动数据库的,但是数据库无法open,也就无法查看到具体的rollback_segment名称,告警日志和trace日志里也没有输出损坏的段名。问题似乎陷入了死循环,想open数据库的前提是知道rollback_segment,但是想知道rollback_segment的前提又是open数据库。实际上在不启动数据库的情况下也有很多方法可以知道rollback_segment名称的,比如通过操作系统strings命令查看system数据文件里的rollback_segment名称,命令如下:
strings system01.dbf | grep _SYSSMU | cut -d $ -f 1 | sort -u > listSMU
rollback_segment信息是记录在system表空间undo$表里的,我当时错误的认为rollback_segment信息是记录在undo表空间里的,所以执行strings undotbs01.dbf什么也没查到,这也是基础不牢的弊端,无奈只好考虑使用自己更不熟悉的bbed工具来查看rollback_segment,最终也是通过bbed工具,在数据库关闭的状态下,读取出了全部的rollback_segment,再将rollback_segment加入到_corrupted_rollback_segments解决了这个问题,具体问题可以看我的另一篇博客:
http://blog.itpub.net/29785807/viewspace-2128326/
在我讲述这个案例时突然意识到面试官会不会针对这个问题继续问我bbed的细节,比如数据块格式,偏移量等等,时间过去很久了,具体细节已经都忘得差不多了。
面试官可能也是为了避免一开始问的太深我答不上来显得尴尬,并没有继续问我更深的细节,而是问了下比较基础的坏块问题:

2 说下坏块的种类
我知道有物理坏块和逻辑坏块,物理坏块一般是块格式本身出现损坏,逻辑坏块一般是oracle BUG引起的。

3 物理坏块和逻辑坏块又可以细分哪几类?比如物理坏块的块断裂等?
不清楚物理坏块和逻辑坏块更细的分类了,之前也没有关注过,即使面试官给了提示也没回答上来。也是平时处理问题时没有注意细节和及时总结的后果,存在很多技术上的盲点。
下面这些是在网上查的关于坏块的描述。
Physical and Logical Block Corruptions. All you wanted to know about it. (Doc ID 840978.1)
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=80681922571215&id=840978.1&_afrWindowMode=0&_adf.ctrl-state=6q340rfff_80
Physical Block Corruptions
This kind of block corruptions are normally reported by Oracle with error ORA-1578 and the detailed corruption description is printed in the alert log. Corruption Examples are:
· Bad header - the beginning of the block (cache header) is corrupt with invalid values
· The block is Fractured/Incomplete - header and footer of the block do not match
· The block checksum is invalid
· The block is misplaced
· Zeroed out blocks Note 1545366.1
Physical Corrupted Blocks consisting of all Zeroes indicate a problem with OS, HW or Storage(Doc ID 1545366.1)
Logical Block Corruptions
Corruption Examples are:
· row locked by non-existent transaction - ORA-600 [4512], etc
· the amount of space used is not equal to block size
· avsp bad
· etc.
https://blogs.oracle.com/database4cn/oraclecorruption-
概述
-------------
数据库坏块(corruption) 的类型可以按照坏块所属对象的不同,分为用户数据坏块,数据字典坏块,Undo坏块,控制文件坏块,Redo坏块,Lob坏块,index坏块等等;也可以按照坏块产生的原因,分为物理坏块(physical corruption)和逻辑坏块(logical corruption )。
本文主要讨论用户数据发生物理坏块(physical corruption)分析和解决方法。
物理坏块
-------------
常见的物理坏块(Physical Block Corruptions)有块头和块尾信息不一致(Fractured/Incomplete),checksum值无效,数据块信息全部为0等情况,并且可能伴随错误ORA-1578和ORA-1110。
为了及时发现物理坏块和准确定位坏块产生的原因,oracle建议设置初始化参数DB_BLOCK_CHECKSUM=TYPICAL(默认值)。一般情况下,物理坏块是由于底层OS/disk系统错误/损坏,导致数据块被修改,数据块标志为坏块(corruption)
数据块的Checksum值无效是一种常见的物理坏块,当数据库初始化参数DB_BLOCK_CHECKSUM=TYPICAL(默认值)时,DBWR进程将数据块写入disk时会计算数据块的Checksum,并且将Checksum值记录在数据块的位置offset 16和17;当从disk读取该数据块时,oracle重新计算数据块的Checksum,并且与记录在数据块中的Checksum做异或运算(Xor),如果异或结果为非0,说明数据块被修改过,数据块为坏块(corruption)。
https://www.cnblogs.com/yhq1314/p/11190045.html
oracle bug可能导致逻辑坏块的产生. 特别是parallel dml. 例如:Bug 5621677 Logical corruption with PARALLEL updateBug 6994194 Logical corruption from UPDATE DMLBug 15980234 ORA-1400 logical corruption from direct path INSERT ALL(fail with ORA-1400, in direct path / PDML) 。
看下docs.oracle.com里对corrupt block的说明:
https://docs.oracle.com/en/database/oracle/oracle-database/20/bradv/glossary.html#GUID-44B5A820-D859-47F5-99CC-56A95AF4BB3E
corrupt block
An Oracle block that is not in a recognized Oracle format, or whose contents are not internally consistent. Typically, corruptions are caused by faulty hardware or operating system problems. Oracle identifies corrupt blocks as either logically corrupt (an Oracle internal error) or media corrupt (the block format is not correct).
You can repair a media corrupt block with block media recovery, or dropping the database object that contains the corrupt block so that its blocks are reused for another object. If media corruption is due to faulty hardware, then neither solution works until the hardware fault is corrected.

4 出现坏块后,如何判断是否是存储硬件问题呢?客户说他们存储硬件没问题,你能通过比如日志还是什么工具说明到底是不是存储硬件的问题?
这个也是我之前一直困扰的问题,之前处理过物理坏块的问题,也想过是不是因为存储硬件出现问题导致的坏块,因为客户曾不同时间多次出现过坏块问题,也让客户去检查存储问题了,但是后来没有继续深入研究过。
面试时回答的是先基于rman进行block级别的恢复,恢复坏块的影响,查看系统日志如messages等,然后观察,如果后续又常出现物理坏块问题,可能和硬件有关,物理坏块通常是由于底层OS/disk系统错误/损坏,导致数据块被修改,但是当时也不能肯定到底是通过哪个日志或者哪种工具能100%确定到底是不是硬件问题导致的物理坏块。

连续两个问题答的都不好,气氛难免有点尴尬,面试官不在继续问坏块相关的问题了,换个问题,缓解下气氛。
5 rac网络心跳出现故障,一个节点服务器自动重启后又恢复正常了,如何判断是否是网卡有问题,查看哪些日志。
当时记得是有个集群同步服务的,是css,错记成了ctss了,概念和原理没记清,当时也是答的一塌糊涂。
实际上是集群层通过CSSD进程来维护节点和节点之间关系的,在集群层做心跳,需要检查集群件的告警日志 alert<HOSTNAME>.log($GRID_HOME/log/$hostname)
和检查ocssd.log($GRID_HOME/log/<hostname>/cssd),对应的后台进程为cssd.bin。
但是这些日志只能查看到misstime,nodexxx left cluster等信息,并没有网卡故障信息。
还可以通过ethtool、 mii-too等工具查看网卡状态,查看messages里关于网卡的信息, 如果有监控平台,可以看对应网卡的历史监控信息,流量、连通性等。

6 说下rac有哪些进程分别什么用途。
Rac后台进程有LMON,LCK,LMD,LMS,DIAG等,服务有crs,css,ctss,evmd,ons等。当时想起了几个进程,LMON,LMS,LMD,但是却想不起来具体哪个进程做什么用的了,最后基本上什么也没答上来。

7 ASM磁盘组或磁盘故障,在替换和修复之前需要提前准备什么。
之前处理过OCR磁盘组误被格式化的问题,也没提前准备什么,直接用本地的ocr和votedisk的自动备份恢复了丢失的数据到新的磁盘组里。也不清楚是要提前备份现有文件比如磁盘头、物理全备等,还是其他什么意思,平时遇到的并不多,经验和理论都有欠缺,也没说出需要准备和注意的。

8 log file sync等待事件相关的oracle bug遇到过哪些?
说了下log file sync大概原理和可能的原因,但是具体哪些oracle bug一个也没记住。之前也整理过log file sync相关知识点,但是具体bug让我跳过了没有关注,MOS上查了下,BUG很多,只有真正处理过才会有印象吧。
http://support.oracle.com
WAITEVENT: "log file sync" Reference Note(Doc ID 34592.1)
The log file sync wait may be broken down into the following components:1. Wakeup LGWR if idle 2. LGWR gathers the redo to be written and issue the I/O3. Time for the log write I/O to complete4. LGWR I/O post processing5. LGWR posting the foreground/user session that the write has completed6. Foreground/user session wakeup
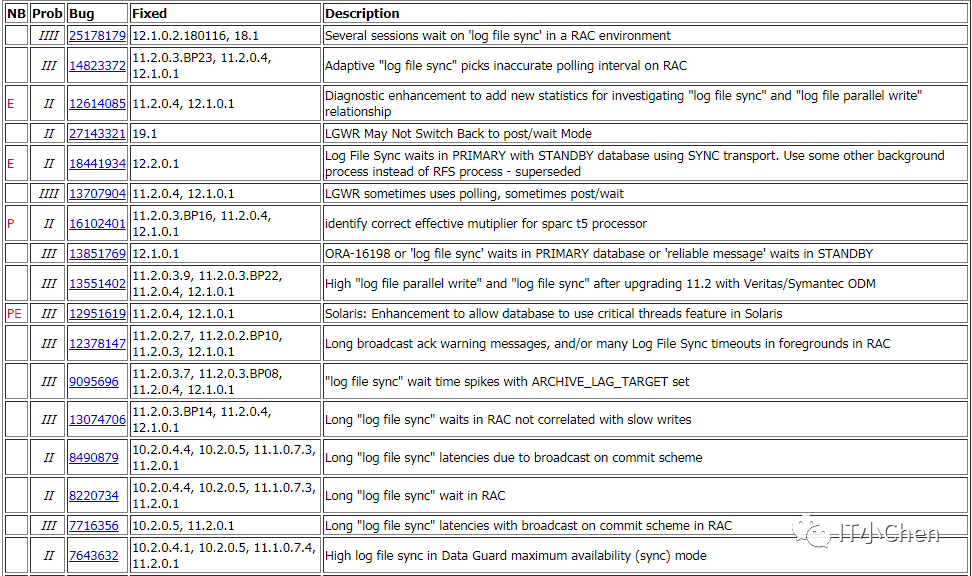
......

前面的问题回答的实在太水了,气氛极度尴尬,面试官又尝试出个送分题,缓和下气氛。
9 假如昨天下午15点到15点01数据库负载很大,今天如何去定位这1分钟内的问题:
分析昨天某个时间段1分钟内的数据库性能?我常用AWR去分析过去某个时间段的数据库性能问题,但是AWR默认1小时收集一次快照,跨度太大了,很显然不适合分析过去1分钟的性能问题,除了AWR以外还有ASH和ADDM,平时用的也不多,好像也不能分析,难道是用一些我不知道的动态性能视图分析的吗?我知道可能相关的视图有v$session,v$session_wait,v$session_wait_history,但是这些最多只能保留最近10次的等待,昨天的会话信息肯定都没有了。实际上我已经想的差不多了,顺着v$session_wait和v$session_wait_history视图再往下想应该就能想到v$active_session_history,然后想到ASH报告。ASH采用的策略是:保存处于等待状态的活动session的信息,每秒从v$session_wait中采样一次,并将采样信息保存在内存中。由于平时处理性能问题时很少使用ASH和ADDM,导致我直接把ASH跳过了,本来一道送分题的,硬生生让我答成送命题。
总结:也做过几年DBA了,有自己的一些野路子,但是在平时工作和学习的过程中,却忽略了一些最基础的概念和原理,导致存在很多盲点,知识体系存在断层,今后还要加强这块的学习。
珍惜当下,当你挑灯夜读学会了各种技能,掌握了各种本领,你会发现,还tm不如打几把排位了!!!

