




本篇文章将介绍合并算法和排序。我还将演示这三种连接方法如何相互比较。
合并加入
合并连接算法采用两个按合并键排序的数据集并返回有序输出。输入数据集可以通过索引扫描进行预排序或显式排序。
合并排序集
下面是合并连接的示例。请注意计划中的 Merge Join 节点。
EXPLAIN (costs off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (t.ticket_no = tf.ticket_no)
−> Index Scan using tickets_pkey on tickets t
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(4 rows)
在这里,优化器选择了这种连接方法,因为它返回按ORDER BY子句下指定的键排序的输出。选择计划时,优化器会考虑输入的顺序,并尽可能避免完全排序。除此之外,只要顺序保持不变,生成的输出就可以用作另一个合并连接的输入:
EXPLAIN (costs off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON t.ticket_no = tf.ticket_no
JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no
AND bp.flight_id = tf.flight_id
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (tf.ticket_no = t.ticket_no)
−> Merge Join
Merge Cond: ((tf.ticket_no = bp.ticket_no) AND (tf.flight_...
−> Index Scan using ticket_flights_pkey on ticket_flights tf
−> Index Scan using boarding_passes_pkey on boarding_passe...
−> Index Scan using tickets_pkey on tickets t
(7 rows)
ticket_flights和boarding_passes表首先合并。这些表有一个复合主键 ( ticket_no, flight_id),因此输出按这两列排序。tickets然后将生成的行集与按排序的表合并ticket_no。
合并在两个数据集上一次完成,不需要任何额外的内存。该算法使用两个指针,它们指向两个集合的当前(或最初,第一)行。
如果当前行的键不匹配,则其中一个指针(指向具有较低键的行的指针)向前移动一步。重复此过程,直到找到匹配项。匹配的行返回到父节点,内部集合指针向前移动一步。该算法重复直到到达任一组的末尾。
这种特定的算法可以处理内部集合中的重复键,但不能处理外部集合中的重复键。引入了一个额外的步骤来解决这个问题:每当外部指针移动但键保持不变时,内部指针就会返回到与键匹配的第一行。这样,每个外部集合行都将与所有具有相同键的内部集合行匹配。
该算法还有另一种变体可以执行外连接,但它基于相同的原理。
合并连接旨在与权益运算符一起使用,因此它仅支持等值连接(但也努力支持其他比较运算符)。
参考之前的例子:
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join (cost=0.99..822358.66 rows=8391852 width=136)
Merge Cond: (t.ticket_no = tf.ticket_no)
−> Index Scan using tickets_pkey on tickets t
(cost=0.43..139110.29 rows=2949857 width=104)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..570975.58 rows=8391852 width=32)
(6 rows)
最初,启动成本至少包括子节点的启动成本。
除此之外,您通常必须在找到第一个匹配项之前扫描两个数据集的至少一部分。要估计这个分数,您可以使用直方图来比较两组中的最小连接键。但是,在这种情况下,两个表中的票号范围是相同的。
节点的总成本是从其子节点检索数据的成本和数据处理成本的总和。
因为算法在到达两个集合中的任何一个的末尾时停止(当然,执行外连接时除外),所以第二个集合的一小部分可能保持未扫描状态。您可以通过比较两组的最大键来估计该部分的大小。在这种情况下,我们的两个集合都将被完全扫描,因此我们将子节点的全部总成本包含在父节点的总成本中。
此外,重复键可能会导致某些内部集合行被多次扫描。重复扫描的次数与连接结果和内部集基数之间的差异成正比。
在这里,这些基数是相同的,这意味着没有重复。
数据处理成本包括关键比较和结果输出。比较的次数可以通过将两组的基数和重复的外部组行扫描的次数相加来估计。一次比较的成本估计为cpu_operator_cost,行输出成本估计为cpu_tuple_cost。
现在我们可以计算示例的连接成本:
SELECT 0.43 + 0.56 AS startup,
round((
139110.29 + 570975.58 +
current_setting('cpu_tuple_cost')::real * 8391852 +
current_setting('cpu_operator_cost')::real * (2949857 + 8391852)
)::numeric, 2) AS total;
startup | total
−−−−−−−−−+−−−−−−−−−−−
0.99 | 822358.66
(1 row)
并联模式
合并连接算法可用于并行计划。
工作人员可以并行扫描外部集合,但每个工作人员单独扫描内部集合。
下面是一个带有合并连接的并行计划示例:
SET enable_hashjoin = off;
EXPLAIN (costs off)
SELECT count(*), sum(tf.amount)
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate
−> Gather
Workers Planned: 2
−> Partial Aggregate
−> Merge Join
Merge Cond: (tf.ticket_no = t.ticket_no)
−> Parallel Index Scan using ticket_flights_pkey o...
−> Index Only Scan using tickets_pkey on tickets t
(8 rows)
此模式不支持全外连接和右外连接。
修改
合并联接支持所有逻辑联接类型。唯一的限制是,对于完全和右外连接,连接条件必须是合并操作的有效表达式(outer column equals inner column或column equals constant)。对于其他逻辑连接类型,在合并完成后,任何不可合并的条件都将应用于输出,但对于完全和右外连接是不可能的。
下面是一个完全合并连接的例子:
EXPLAIN (costs off) SELECT *
FROM tickets t
FULL JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort
Sort Key: t.ticket_no
−> Merge Full Join
Merge Cond: (t.ticket_no = tf.ticket_no)
−> Index Scan using tickets_pkey on tickets t
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(6 rows)
内部和左外部合并连接保留顺序。全外连接和右外连接不会,因为数据中可能出现的 NULL 值会破坏排序。这是 Sort 节点用于重新排序输出的地方。它增加了成本,使散列连接成为更有吸引力的替代方案,因此我们必须明确禁用它以进行演示。
但是,在下一个示例中,无论如何都选择了散列连接,因为不能以任何其他方式完成具有不可合并条件的完全连接。
EXPLAIN (costs off) SELECT *
FROM tickets t
FULL JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
AND tf.amount > 0
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort
Sort Key: t.ticket_no
−> Hash Full Join
Hash Cond: (tf.ticket_no = t.ticket_no)
Join Filter: (tf.amount > '0'::numeric)
−> Seq Scan on ticket_flights tf
−> Hash
−> Seq Scan on tickets t
(8 rows)
RESET enable_hashjoin;
排序
如果任一集合(或两者)没有按连接键排序,则必须在合并之前对其进行排序。这种必要的排序是在计划中的排序节点下完成的。
EXPLAIN (costs off)
SELECT *
FROM flights f
JOIN airports_data dep ON f.departure_airport = dep.airport_code
ORDER BY dep.airport_code;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (f.departure_airport = dep.airport_code)
−> Sort
Sort Key: f.departure_airport
−> Seq Scan on flights f
−> Sort
Sort Key: dep.airport_code
−> Seq Scan on airports_data dep
(8 rows)
排序算法本身是通用的。它可以由ORDER BY子句本身或在窗口函数中调用:
EXPLAIN (costs off)
SELECT flight_id,
row_number() OVER (PARTITION BY flight_no ORDER BY flight_id)
FROM flights f;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
WindowAgg
−> Sort
Sort Key: flight_no, flight_id
−> Seq Scan on flights f
(4 rows)
在这里,WindowAgg 节点计算由 Sort 节点预先排序的数据集的窗口函数。
规划器有多种排序模式可供选择。上面的例子展示了其中的两个(排序方法)。与往常一样,您可以通过以下方式深入了解更多详细信息EXPLAIN ANALYZE:
EXPLAIN (analyze,costs off,timing off,summary off)
SELECT *
FROM flights f
JOIN airports_data dep ON f.departure_airport = dep.airport_code
ORDER BY dep.airport_code;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join (actual rows=214867 loops=1)
Merge Cond: (f.departure_airport = dep.airport_code)
−> Sort (actual rows=214867 loops=1)
Sort Key: f.departure_airport
Sort Method: external merge Disk: 17136kB
−> Seq Scan on flights f (actual rows=214867 loops=1)
−> Sort (actual rows=104 loops=1)
Sort Key: dep.airport_code
Sort Method: quicksort Memory: 52kB
−> Seq Scan on airports_data dep (actual rows=104 loops=1)
(10 rows)
快速排序
如果要排序的数据完全适合允许的内存 ( work_mem ),则使用良好的旧快速排序算法。你可以在任何计算机科学教科书的第一页找到它的描述,所以我不会在这里重复。
对于实现,排序由特定组件完成,该组件为任务选择最合适的算法。
让我们看一下算法是如何对一个小表进行排序的:
EXPLAIN SELECT *
FROM airports_data
ORDER BY airport_code;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=7.52..7.78 rows=104 width=145)
Sort Key: airport_code
−> Seq Scan on airports_data (cost=0.00..4.04 rows=104 width=...
(3 rows)
对 n 个值进行排序的复杂度为 O( n log 2 n )。一个比较操作的成本是cpu_operator_cost值的两倍。您需要对整个集合进行扫描和排序才能得到结果,因此启动排序成本将包括比较操作成本和子节点的总成本。
除此之外,总排序成本将包括排序节点输出的每一行的处理成本,估计为每行的cpu_operator_cost(而不是默认的cpu_tuple_cost,因为它很便宜)。
因此,上面示例的排序成本将计算如下:
WITH costs(startup) AS (
SELECT 4.04 + round((
current_setting('cpu_operator_cost')::real 2
104 * log(2, 104)
)::numeric, 2)
)
SELECT startup,
startup + round((
current_setting('cpu_operator_cost')::real * 104
)::numeric, 2) AS total
FROM costs;
startup | total
−−−−−−−−−+−−−−−−−
7.52 | 7.78
(1 row)
前 N 堆排序
前N 堆排序是当您只希望对集合的一部分进行排序(直到某个LIMIT)而不是整个集合时执行的操作。LIMIT更准确地说,当将过滤掉至少一半的输入行,或者当输入不适合内存但输出适合时,使用此算法。
EXPLAIN (analyze, timing off, summary off) SELECT *
FROM seats
ORDER BY seat_no
LIMIT 100;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Limit (cost=72.57..72.82 rows=100 width=15)
(actual rows=100 loops=1)
−> Sort (cost=72.57..75.91 rows=1339 width=15)
(actual rows=100 loops=1)
Sort Key: seat_no
Sort Method: top−N heapsort Memory: 33kB
−> Seq Scan on seats (cost=0.00..21.39 rows=1339 width=15)
(actual rows=1339 loops=1)
(8 rows)
为了找到n中的k个最高(最低)值,该算法首先创建一个称为堆的数据结构并将k前行添加到其中。然后它继续将行一一添加到堆中,但在每一行之后,它从堆中驱逐一个最低(最高)的值。当它用完要添加的新行时,堆会留下k个最高或最低值。
这里的术语堆是指一种特定的数据结构,不应与数据库表混淆,后者通常具有相同的名称。
算法复杂度为O( n log 2 k ),但是每次操作的成本都比Quicksort高,所以成本计算公式以n log 2 2 k作为估计。
WITH costs(startup) AS (
SELECT 21.39 + round((
current_setting('cpu_operator_cost')::real 2
1339 log(2, 2 100)
)::numeric, 2)
)
SELECT startup,
startup + round((
current_setting('cpu_operator_cost')::real * 100
)::numeric, 2) AS total
FROM costs;
startup | total
−−−−−−−−−+−−−−−−−
72.57 | 72.82
(1 row)
外部排序
每当执行器发现它正在读取的数据集太需要在内存中排序时,排序节点就会切换到外部合并排序模式。
到目前为止扫描的行由 Quicksort 排序并转储到临时文件中。
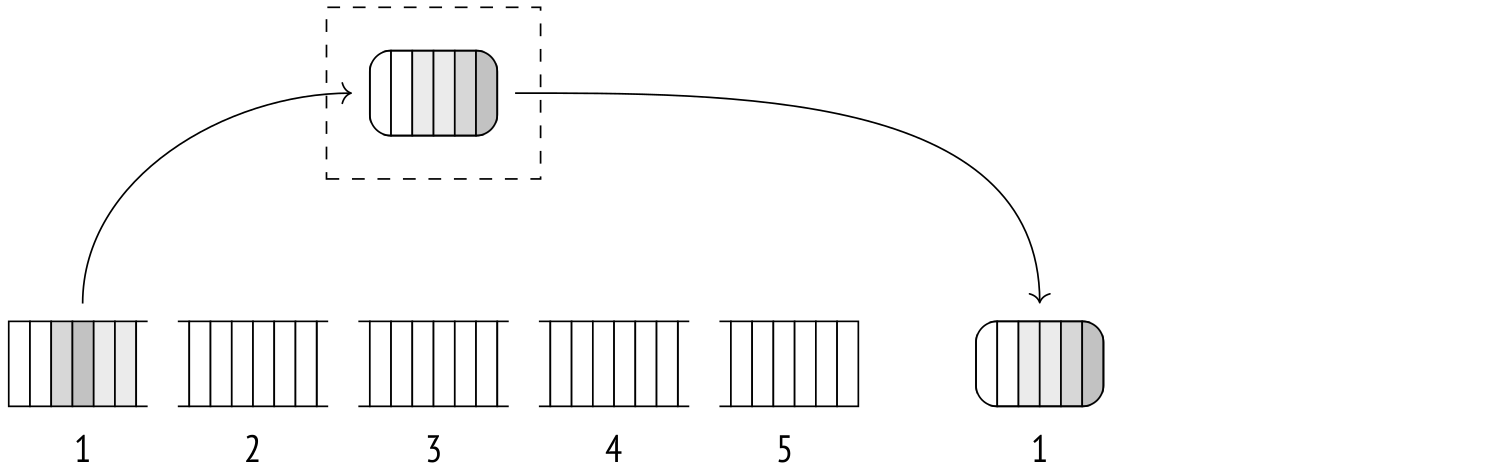
然后另一批行被扫描、排序和转储,等等。重复此过程,直到所有数据都存储在磁盘上的一堆排序文件中。
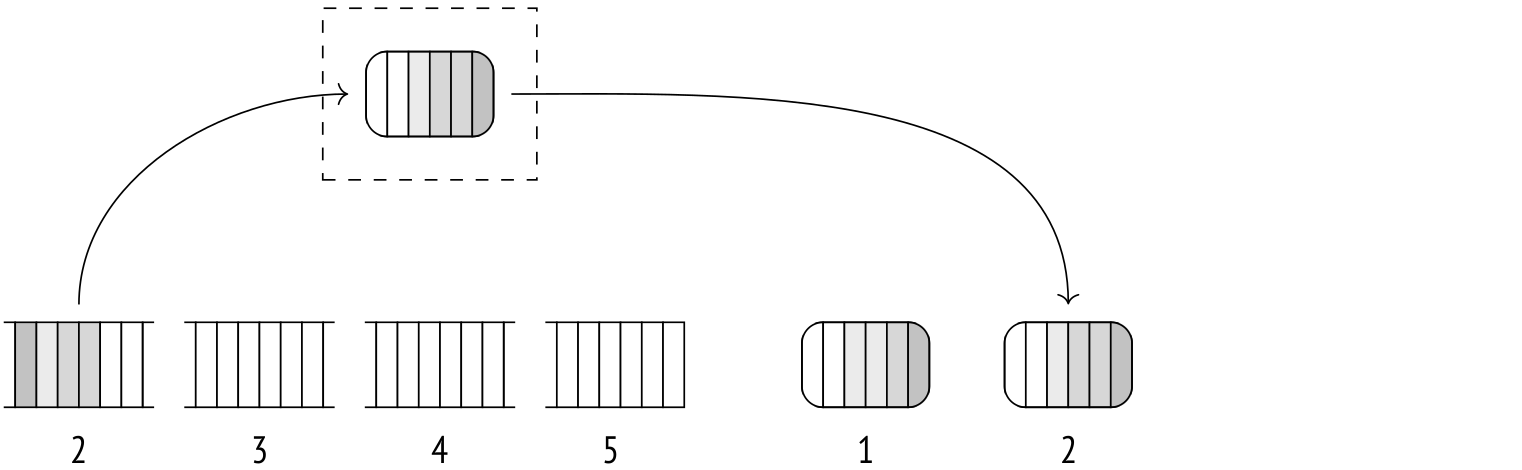
然后,算法开始合并文件。该过程与合并连接非常相似,尽管这里可以一次合并两个以上的文件。
合并不会占用大量内存。从本质上讲,每个文件的单行大小就足够了。该算法扫描每个文件的第一行并存储它们。然后,它在存储的值中选择最低(或最高)值并将其作为输出返回。之后,它需要另一行并将其放入存储返回行的内存中。
在实践中,不是逐一扫描行,而是分批扫描每行 32 页,以节省 I/O 成本。一次合并的文件数由可用内存量决定,但绝不会少于六个。它也永远不会超过 500,因为算法效率会在大量并发合并文件时受到影响。
如果无法在一次迭代中合并所有临时文件,则第一次合并的结果将转储到其自己的临时文件中。每次迭代都会增加从磁盘读取和写入磁盘的数据量,从而减慢该过程,因此拥有尽可能多的内存以使外部合并排序有效运行是有益的。
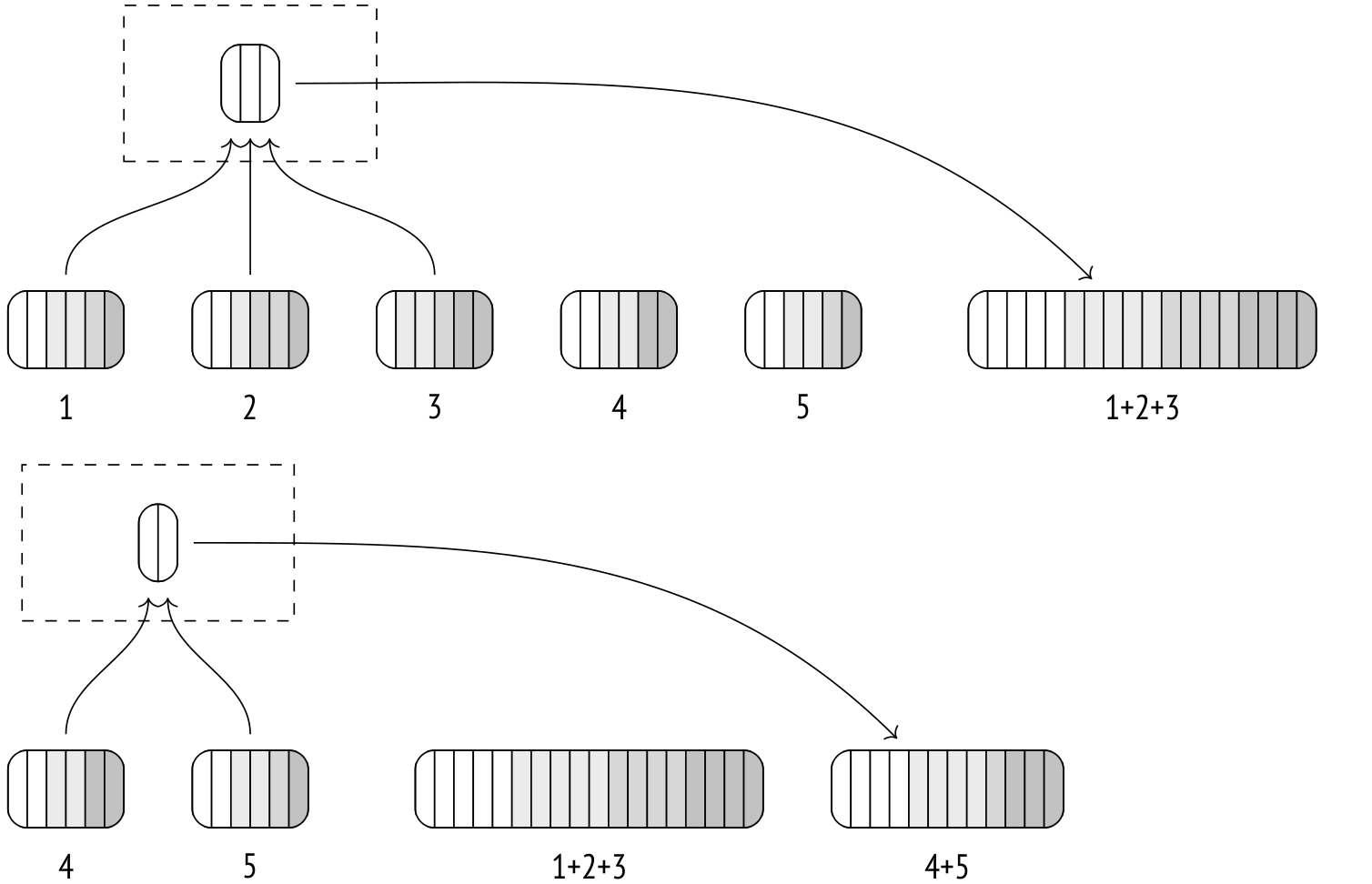
第二次迭代获取第一次迭代产生的临时文件并重复该过程。
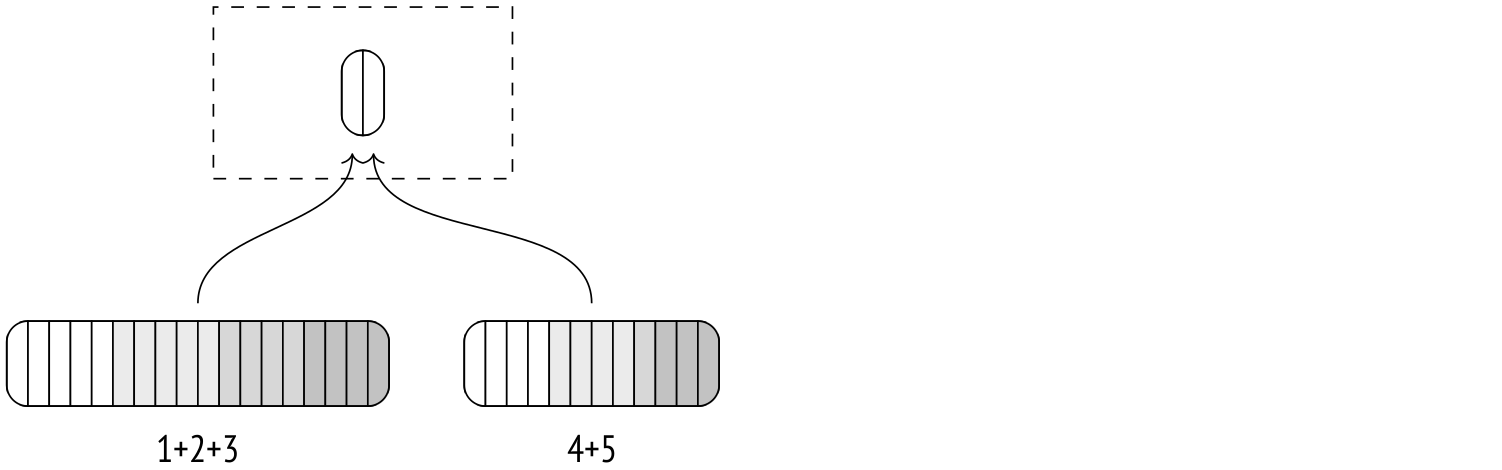
最终的合并通常会被推迟,并且仅在父节点拉取数据时执行。
让我们EXPLAIN ANALYZE来看看排序用了多少磁盘空间。buffers您还可以使用该选项检查临时文件(临时读取和写入)的缓冲区使用统计信息。读取和写入的缓冲区数量大致相同,并且转换为 KB 后,将与计划中的 Disk 值匹配。
EXPLAIN (analyze, buffers, costs off, timing off, summary off)
SELECT *
FROM flights
ORDER BY scheduled_departure;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (actual rows=214867 loops=1)
Sort Key: scheduled_departure
Sort Method: external merge Disk: 17136kB
Buffers: shared hit=610 read=2017, temp read=2142 written=2150
−> Seq Scan on flights (actual rows=214867 loops=1)
Buffers: shared hit=607 read=2017
(6 rows)
在服务器日志中有更多关于临时文件的统计信息(使用参数log_temp_buffers on)。
我们再看一下外部归并排序方案:
EXPLAIN SELECT *
FROM flights
ORDER BY scheduled_departure;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=31883.96..32421.12 rows=214867 width=63)
Sort Key: scheduled_departure
−> Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63)
(3 rows)
在这里,基本的比较成本与快速排序中的相同,但还增加了 I/O 成本。所有输入数据首先转储到磁盘,然后从磁盘读取以进行合并(多次,如果有太多单独的文件需要一次合并)。
写入磁盘的数据量取决于输入数据集中的行数和大小。在此示例中,查询从表中提取所有列flights,因此数据大小将接近表大小,除了它不包含任何元组标题和页面元数据(2309 个页面与 2624 个页面)。在这里,一次迭代就足以对数据进行排序。
I/O 操作(读取和写入)估计是顺序的 3/4 时间和随机的 1/4 时间。
所以最后,排序成本会这样计算:
WITH costs(startup) AS (
SELECT 4772.67 + round((
current_setting('cpu_operator_cost')::real 2
214867 * log(2, 214867) +
(current_setting('seq_page_cost')::real * 0.75 +
current_setting('random_page_cost')::real 0.25)
2 2309 1 -- one iteration
)::numeric, 2)
)
SELECT startup,
startup + round(( current_setting('cpu_operator_cost')::real * 214867
)::numeric, 2) AS total
FROM costs;
startup | total
−−−−−−−−−−+−−−−−−−−−−
31883.96 | 32421.13
(1 row)
增量排序
假设您想通过键K 1 ... K m ... K n对集合进行排序,并且已知该集合已经通过某些前键K 1 ... K m排序。然后,您可以通过不对整个集合进行排序来节省时间。相反,您可以将集合分成组,每个组仅包含具有相同K 1 ... K m值(连续排列)的行,然后按剩余键K m+1 ... K n对每个组进行排序。这种方法称为增量排序,它在 PostgreSQL 13 及更高版本中可用。
增量排序通过将集合分成多个较小的组来减少内存需求,并且还可以开始逐组输入输出,而无需等待整个集合被处理。
实际实现采用了额外的优化:虽然它将较大的行块分成组以单独排序,但较小的子集被放入一个组并一起排序。与准系统算法相比,这降低了排序启动开销成本。
计划中的增量排序节点是进行排序的地方:
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM bookings
ORDER BY total_amount, book_date;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Incremental Sort (actual rows=2111110 loops=1)
Sort Key: total_amount, book_date
Presorted Key: total_amount
Full−sort Groups: 2823 Sort Method: quicksort Average
Memory: 30kB Peak Memory: 30kB
Pre−sorted Groups: 2624 Sort Method: quicksort Average
Memory: 3152kB Peak Memory: 3259kB
−> Index Scan using bookings_total_amount_idx on bookings (ac...
(8 rows)
从计划中可以明显看出,该集合按 预排序total_amount,是针对该列的索引扫描的输出(预排序键)。该EXPLAIN ANALYZE命令还向我们展示了处理数据所花费的时间。Full-sort Groups 值显示聚集在一起并定期排序的行数,Pre-sorted Groups 显示按book_date列递增排序的大组数。在这两种情况下都使用了内存中快速排序。团体规模的变化是由于预订成本的分布不均匀造成的。
在 PostgreSQL 14 及更高版本中,增量排序也适用于窗口函数:
EXPLAIN (costs off)
SELECT row_number() OVER (ORDER BY total_amount, book_date)
FROM bookings;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
WindowAgg
−> Incremental Sort
Sort Key: total_amount, book_date
Presorted Key: total_amount
−> Index Scan using bookings_total_amount_idx on bookings
(5 rows)
增量排序成本取决于估计的组数和对平均组进行排序的估计成本(我们之前已经介绍过)。
启动成本显示了对一个(第一个)组进行排序的成本,因为这足以让节点开始输出。总成本包括对所有组进行排序的成本。
EXPLAIN SELECT *
FROM bookings
ORDER BY total_amount, book_date;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Incremental Sort (cost=45.10..282293.40 rows=2111110 width=21)
Sort Key: total_amount, book_date
Presorted Key: total_amount
−> Index Scan using bookings_total_amount_idx on bookings (co...
(4 rows)
我将在此处跳过计算的详细信息。
并联模式
排序可以并行执行。也就是说,虽然工作人员返回排序后的输出,但 Gather 节点不会以任何方式对它们进行排序,只会按照输入的任何顺序附加输入。为了保持行排序,使用了另一个节点:Gather Merge。
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM flights
ORDER BY scheduled_departure
LIMIT 10;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Limit (actual rows=10 loops=1)
−> Gather Merge (actual rows=10 loops=1)
Workers Planned: 1
Workers Launched: 1
−> Sort (actual rows=8 loops=2)
Sort Key: scheduled_departure
Sort Method: top−N heapsort Memory: 27kB
Worker 0: Sort Method: top−N heapsort Memory: 27kB
−> Parallel Seq Scan on flights (actual rows=107434 lo...
(9 rows)
Gather Merge 节点使用二叉堆对来自工作人员的行进行排序。本质上,它只是合并了几组行,很像外部合并排序,但在底层存在一些差异,其中之一是 Gather Merge 节点针对处理少量固定数量的数据源和用于逐行接收,无需块 I/O。
Gather Merge 启动成本取决于子节点启动成本。与 Gather 节点一样,还有工作进程启动成本,估计为parallel_setup_cost参数值。
除此之外,还有二进制堆构建成本,其中包括对n 个项目进行排序,其中n是并行工作器的数量,即n log 2 n。比较操作成本估计为cpu_operator_cost乘以 2。由此产生的成本通常是微不足道的,因为工人的数量从来没有那么高。
然后,总成本加上子节点(由多个工作人员执行)的数据检索成本和工作人员的数据输出成本。考虑到可能的延迟,检索和输出成本估计为每行的parallel_tuple_cost加上 5%。
最后是二叉堆更新,它需要 log 2 n比较操作加上辅助操作。它的成本估计为 log N (2 cpu_operator_cost ) + cpu_operator_cost每个输入行。
这是另一个带有 Gather Merge 的计划:
EXPLAIN SELECT amount, count(*)
FROM ticket_flights
GROUP BY amount;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize GroupAggregate (cost=123399.62..123485.00 rows=337 wid...
Group Key: amount
−> Gather Merge (cost=123399.62..123478.26 rows=674 width=14)
Workers Planned: 2
−> Sort (cost=122399.59..122400.44 rows=337 width=14)
Sort Key: amount
−> Partial HashAggregate (cost=122382.07..122385.44 r...
Group Key: amount
−> Parallel Seq Scan on ticket_flights (cost=0.00...
(9 rows)
请注意,这里的工作人员在将结果传递给排序节点之前执行部分哈希聚合。这是有效的,因为聚合减少了行数。然后,Sort 节点将输出传递给领导进程,由 Gather Merge 节点组装。最终聚合使用排序的值列表而不是散列。
在本例中,有 3 个并行进程(包括领导者),因此 Gather Merge 成本计算如下:
WITH costs(startup, run) AS (
SELECT round((
-- starting up the processes
current_setting('parallel_setup_cost')::real +
-- building the heap
current_setting('cpu_operator_cost')::real 2 3 * log(2, 3)
)::numeric, 2),
round((
-- transmitting the rows
current_setting('parallel_tuple_cost')::real 1.05 674 +
-- updating the heap
current_setting('cpu_operator_cost')::real 2 674 * log(2, 3) +
current_setting('cpu_operator_cost')::real * 674
)::numeric, 2)
)
SELECT 122399.59 + startup AS startup,
122400.44 + startup + run AS total
FROM costs;
startup | total
−−−−−−−−−−−+−−−−−−−−−−−
123399.61 | 123478.26
(1 row)
分组和不同的值
前面的示例表明,聚合值的分组(和删除重复值)既可以通过散列也可以通过排序来完成。在排序列表中,可以在一次遍历中找到一组重复值。
一个名为 Unique 的简单节点执行从给定列表中选择不同值的任务:
EXPLAIN (costs off) SELECT DISTINCT book_ref
FROM bookings
ORDER BY book_ref;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Result
−> Unique
−> Index Only Scan using bookings_pkey on bookings
(3 rows)
聚合本身在 GroupAggregate 节点下执行。
EXPLAIN (costs off) SELECT book_ref, count(*)
FROM bookings
GROUP BY book_ref
ORDER BY book_ref;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
GroupAggregate
Group Key: book_ref
−> Index Only Scan using bookings_pkey on bookings
(3 rows)
在并行计划中,此节点将被 Partial GroupAggregate 替换,聚合将在 Finalize GroupAggregate 下完成。
GROUPING SETS在 PostgreSQL 10 及更高版本中,当对多个集合(下、、CUBE和ROLLUP子句)执行分组时,同一节点可以使用散列和排序。该算法的细节过于复杂,无法在本文的范围内涵盖,但我们可以看一个示例。在这个计划中,分组是在三个不同的列上执行的,并且内存是有限的。
SET work_mem = '64kB';
EXPLAIN (costs off)
SELECT count(*)
FROM flights
GROUP BY GROUPING SETS (aircraft_code, flight_no, departure_airport);
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
MixedAggregate
Hash Key: departure_airport
Group Key: aircraft_code
Sort Key: flight_no
Group Key: flight_no
−> Sort
Sort Key: aircraft_code
−> Seq Scan on flights
(8 rows)
聚合节点 MixedAggregate 接收一组按飞机代码预先排序的行。
首先,扫描集合,将行按aircraft_code(Group Key)分组。在扫描行时,它们由flight_no重新排序(通过内存中的快速排序(如果足够)或通过磁盘上的外部排序,就像排序节点一样)。同时,这些行被记录到一个散列表中,键为“department_airport”(内存中或磁盘上的临时文件,就像 HashAggregate 一样)。
接下来,对刚刚按flight_no排序的集合进行扫描,并按相同的键(Sort Key 和嵌套的 Group Key)进行分组。如果需要按另一列分组,则在此阶段将相应地重新排序行。
最后,扫描第一步的哈希表,并将值按离开机场(哈希键)分组。
连接方法比较
可以使用三种方法连接两个数据集,每种方法都有自己的优点和缺点。
嵌套循环连接需要零设置时间,并且可以立即开始返回结果行。这是唯一不需要扫描整个集合的方法,前提是索引访问可用。这些属性使嵌套循环连接(与索引一起)成为 OLTP 系统的完美选择,它有大量的短查询一次只返回几行。
当数据量增加时,该算法的缺点变得明显。对于笛卡尔积计算,算法的复杂性是二次的:成本与两个数据集大小的乘积成正比。在实践中,纯笛卡尔积计算并不经常出现。通常,每个外部集合行的内部集合索引扫描中都有一定数量的行,并且该数量与内部集合中的总行数无关(例如,每次预订的平均票数不t 取决于预订总数或预订的门票总数)。因此,复杂度的增加通常是线性的,而不是二次的,尽管线性系数很高。
嵌套循环连接的另一个重要特性是它的多功能性。虽然其他连接方法仅支持等连接,但此算法可以在任何连接条件下运行。这使得该算法几乎适用于任何类型的查询和条件(完全连接除外,它不能在嵌套循环中完成)。但是请记住,大型数据集的非等连接本质上是低效的。
散列连接是您想要用于大型数据集的方法。有了足够的内存,散列连接可以一次连接两个数据集。换句话说,它的复杂性是线性的。哈希联接与顺序扫描一起使用,最常见于处理大量数据的 OLAP 查询环境中。
该算法不适合延迟比吞吐量更重要的用例,因为它在整个哈希表完成之前无法开始返回数据。
除此之外,散列连接仅限于等值连接。最后,您使用的数据类型必须是可散列的(但这很少是问题)。
在 PostgreSQL 14 及更高版本中,嵌套循环连接有时会与哈希连接竞争,这要归功于 Memorize 节点(也基于哈希表)缓存内部集合行的能力。嵌套循环连接可以在某些条件下提前,因为它不必像散列连接那样扫描整个内部集。
合并连接适用于短 OLTP 查询和长 OLAP 查询。它具有线性复杂性(两组只需扫描一次),需要很少的内存并且可以立即开始输出。唯一需要注意的是数据集必须预先排序。理想的情况是输入来自索引扫描。这也是小型行集的自然选择。对于大量数据,索引访问只有在几乎没有表访问时才保持高效。
如果没有适当的索引,就必须对数据集进行排序,并且排序具有高于线性的复杂度:O( n log 2 n )。因此,合并连接通常落后于散列连接,除了输出也必须排序的情况。
合并连接不区分内部集和外部集,这是一个不错的好处。如果计划器错误地分配内部和外部集,嵌套循环连接和哈希连接的效率都会下降,而对于合并连接,这不是问题。
与散列连接一样,合并连接只能与等值连接一起使用。此外,数据类型必须具有 B-Tree 运算符类。
下图说明了在不同连接选择性值下不同连接方法的近似成本。
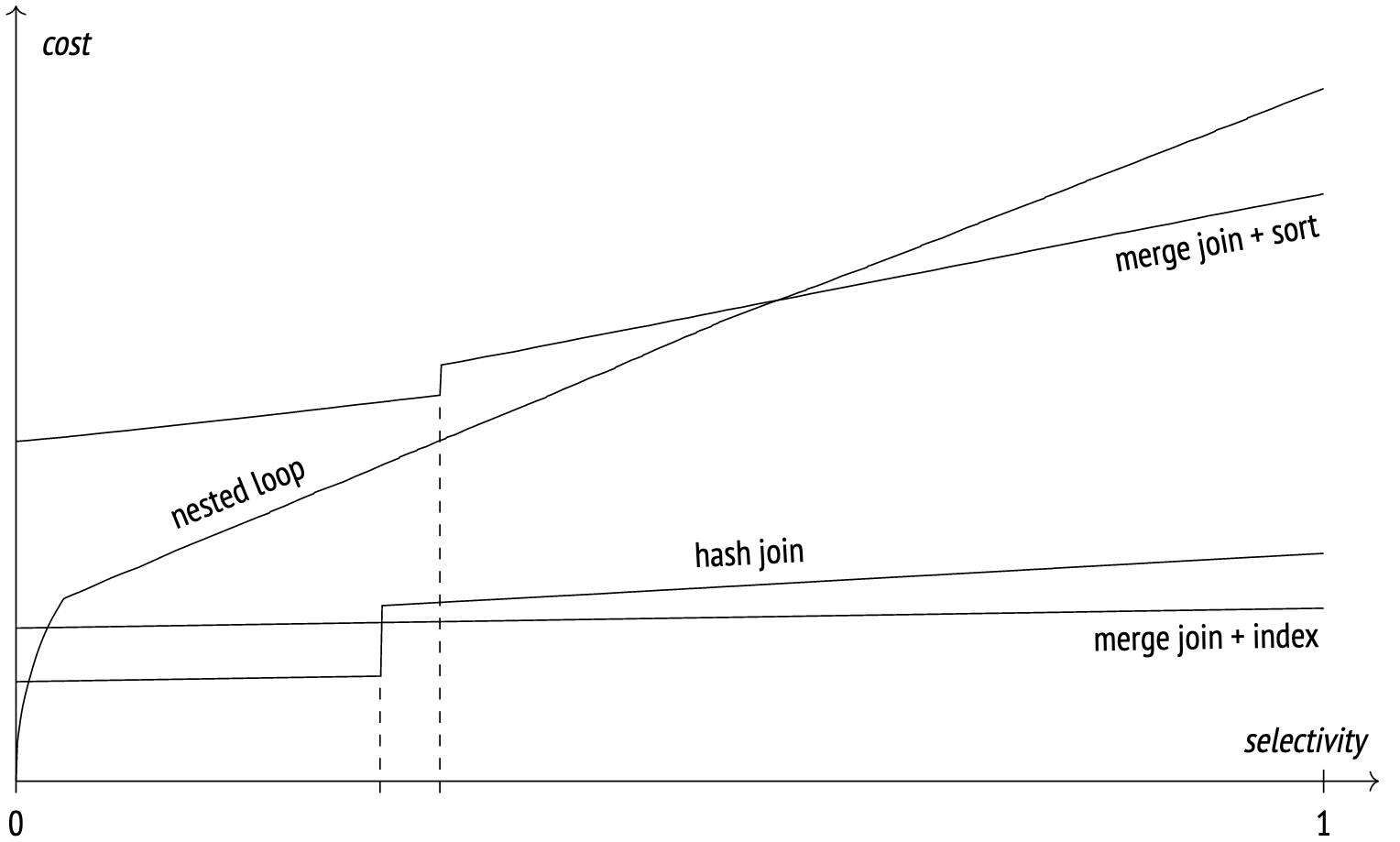
When selectivity is high, the nested loop join scans both tables by index, but at high selectivity it switches to full scan and the graph becomes linear.
在此示例中,散列连接对两个表都使用全扫描。图上的“步骤”表示哈希表不再适合内存并且数据开始溢出到磁盘的时刻。
随着选择性的增加,带有索引扫描的合并连接显示成本略有增加。有了足够的work_mem,散列连接优于合并连接,但是当涉及到临时文件时,合并连接会领先。
合并连接和排序图显示了当索引扫描不可用且需要进行预排序时成本如何增加。与散列连接一样,“步骤”表示算法耗尽内存并开始将数据溢出到临时文件中的时刻。
这只是一个示例,图表会因情况而异。
原文标题:Queries in PostgreSQL: Sort and merge
原文作者:Egor Rogov
原文链接:https://postgrespro.com/blog/pgsql/5969770
