




MySQL在8.0版中引入了窗口函数。许多开发人员已经需要此功能一段时间了。在本文中,我将展示其优点以及如何在MySQL 8.0上使用窗口函数。
加载一些公共数据
我正在运行一台适用于MySQL 8.0的Percona服务器,并且我获得了一些关于COVID-19感染,住院治疗和其他信息的意大利公共数据。数据按天和按区域提供,请点击以下链接:
https://github.com/pcm-dpc/COVID-19/tree/master/dati-regioni。
我只加载了2021年和2022年几个月的数据。原始数据用意大利语标记,因此我创建了一个类似的简化表,只是为了满足本文的需要。
下面是一个数据示例:
mysql> DESC covid;
+----------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+----------------+
| id | int unsigned | NO | PRI | NULL | auto_increment |
| day | date | YES | | NULL | |
| region | varchar(50) | YES | | NULL | |
| total_cases | int unsigned | YES | | NULL | |
| deceased | int unsigned | YES | | NULL | |
| hospitalized | int unsigned | YES | | NULL | |
| intensive_care | int unsigned | YES | | NULL | |
| home_isolation | int unsigned | YES | | NULL | |
+----------------+--------------+------+-----+---------+----------------+
mysql> SELECT * FROM covid LIMIT 5;
+----+------------+----------------+-------------+----------+--------------+----------------+----------------+
| id | day | region | total_cases | deceased | hospitalized | intensive_care | home_isolation |
+----+------------+----------------+-------------+----------+--------------+----------------+----------------+
| 1 | 2021-10-01 | Abruzzo | 81281 | 2545 | 56 | 4 | 1677 |
| 2 | 2021-10-01 | Basilicata | 30175 | 614 | 38 | 2 | 1214 |
| 3 | 2021-10-01 | Calabria | 83918 | 1408 | 156 | 15 | 3359 |
| 4 | 2021-10-01 | Campania | 456695 | 7944 | 233 | 21 | 6578 |
| 5 | 2021-10-01 | Emilia-Romagna | 424089 | 13477 | 416 | 46 | 13882 |
+----+------------+----------------+-------------+----------+--------------+----------------+----------------+
什么是窗口函数
窗口函数允许跨排序行运行窗口,从而在窗口的每个步骤上生成计算。因此,将为查询返回的每一行提供窗口函数的结果。
Window Functions 的主要优点是,您可以以更有效、更优雅的方式动态运行聚合,而无需创建临时表或视图以用于进一步的查询。
典型的用例是计算滚动平均值、相关分数或累积总计。
两个新子句用于定义和使用窗口函数:结束和窗口。第二个不是强制性的。我们将看到一些示例来演示如何使用它们。
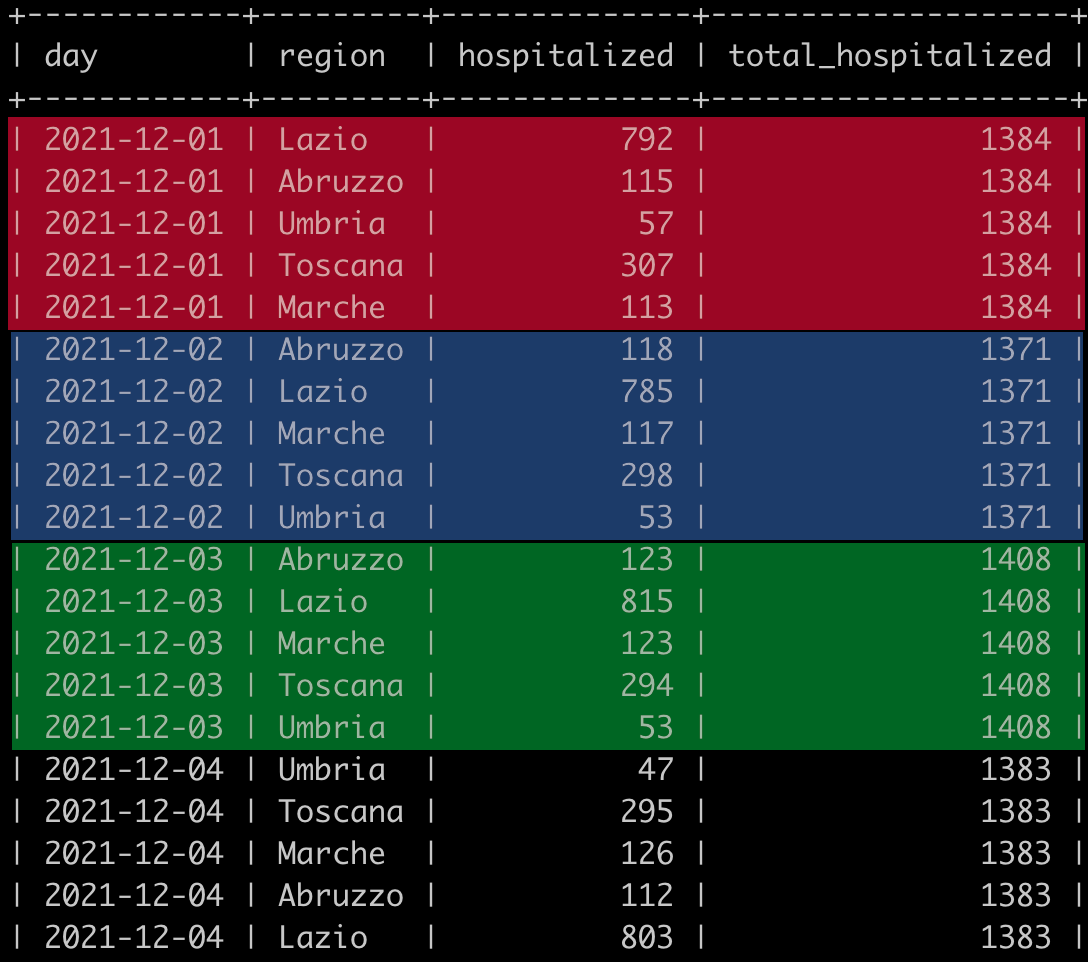
第一个例子:意大利中部地区的住院治疗
让我们将注意力集中在“意大利中部”的特定区域,其中包括以下五个地区:托斯卡纳,翁布里亚,马尔凯,拉齐奥和阿布鲁佐。
我们想了解每个地区每天的住院人数,并计算特定时期(2021年12月的第一周)整个地区的住院总数。
mysql> SELECT day, region, hospitalized,
-> SUM(hospitalized) OVER(PARTITION BY day) AS 'total_hospitalized'
-> FROM covid
-> WHERE region IN ('Toscana','Umbria','Lazio','Marche','Abruzzo')
-> AND day BETWEEN '2021-12-01' AND '2021-12-06';
+------------+---------+--------------+--------------------+
| day | region | hospitalized | total_hospitalized |
+------------+---------+--------------+--------------------+
| 2021-12-01 | Lazio | 792 | 1384 |
| 2021-12-01 | Abruzzo | 115 | 1384 |
| 2021-12-01 | Umbria | 57 | 1384 |
| 2021-12-01 | Toscana | 307 | 1384 |
| 2021-12-01 | Marche | 113 | 1384 |
| 2021-12-02 | Abruzzo | 118 | 1371 |
| 2021-12-02 | Lazio | 785 | 1371 |
| 2021-12-02 | Marche | 117 | 1371 |
| 2021-12-02 | Toscana | 298 | 1371 |
| 2021-12-02 | Umbria | 53 | 1371 |
| 2021-12-03 | Abruzzo | 123 | 1408 |
| 2021-12-03 | Lazio | 815 | 1408 |
| 2021-12-03 | Marche | 123 | 1408 |
| 2021-12-03 | Toscana | 294 | 1408 |
| 2021-12-03 | Umbria | 53 | 1408 |
| 2021-12-04 | Umbria | 47 | 1383 |
| 2021-12-04 | Toscana | 295 | 1383 |
| 2021-12-04 | Marche | 126 | 1383 |
| 2021-12-04 | Abruzzo | 112 | 1383 |
| 2021-12-04 | Lazio | 803 | 1383 |
| 2021-12-05 | Abruzzo | 122 | 1408 |
| 2021-12-05 | Lazio | 811 | 1408 |
| 2021-12-05 | Marche | 126 | 1408 |
| 2021-12-05 | Toscana | 299 | 1408 |
| 2021-12-05 | Umbria | 50 | 1408 |
| 2021-12-06 | Lazio | 864 | 1472 |
| 2021-12-06 | Umbria | 50 | 1472 |
| 2021-12-06 | Toscana | 300 | 1472 |
| 2021-12-06 | Marche | 130 | 1472 |
| 2021-12-06 | Abruzzo | 128 | 1472 |
+------------+---------+--------------+--------------------+
30 rows in set (0.00 sec)
在此示例中,SUM() 函数用作窗口函数,对由 OVER 子句内容定义的一组行进行操作。您经常与 GROUP BY 一起使用的许多其他聚合函数都可以通过这种方式用作窗口函数。OVER 子句通过定义窗口的行集来发挥魔力。在这里,PARTITION BY day 告诉MySQL将所有具有相同日期列值的行视为窗口,然后仅计算这些行上的SUM()。将聚合函数与 GROUP BY 结合使用或用作窗口函数之间的主要区别在于,在第一种情况下,为每个组返回一行,在第二种情况下,将返回所有行,并为每行返回聚合值。
下图以不同的颜色显示了如何考虑此查询的窗口:
第二个例子:一个查询中的多个窗口函数
下面是另一个示例,用于演示可以在查询中创建多个窗口。每个都必须有自己的 OVER 子句来定义分区。
在下面的查询中,我们希望返回 2022 年 1 月整个国家的平均死亡人数。此外,我们希望返回该期间每个地区的最大死者人数。
mysql> SELECT day, region, deceased,
-> AVG(deceased) OVER() AS 'country average deceased'
-> MAX(deceased) OVER(PARTITION BY region) AS 'max daily deceased in the period'
-> FROM covid
-> WHERE day BETWEEN '2022-01-01' AND '2022-01-31'
-> ORDER BY day, region;
+------------+-----------------------+----------+--------------------------+----------------------------------+
| day | region | deceased | country average deceased | max daily deceased in the period |
+------------+-----------------------+----------+--------------------------+----------------------------------+
| 2022-01-01 | Abruzzo | 2640 | 6737.0000 | 2811 |
| 2022-01-01 | Basilicata | 635 | 6737.0000 | 681 |
| 2022-01-01 | Calabria | 1625 | 6737.0000 | 1887 |
| 2022-01-01 | Campania | 8471 | 6737.0000 | 9139 |
| 2022-01-01 | Emilia-Romagna | 14231 | 6737.0000 | 15088 |
| 2022-01-01 | Friuli Venezia Giulia | 4225 | 6737.0000 | 4487 |
| 2022-01-01 | Lazio | 9275 | 6737.0000 | 9823 |
| 2022-01-01 | Liguria | 4587 | 6737.0000 | 4873 |
| 2022-01-01 | Lombardia | 35095 | 6737.0000 | 37184 |
| 2022-01-01 | Marche | 3249 | 6737.0000 | 3418 |
| 2022-01-01 | Molise | 512 | 6737.0000 | 528 |
| 2022-01-01 | P.A. Bolzano | 1307 | 6737.0000 | 1357 |
| 2022-01-01 | P.A. Trento | 1423 | 6737.0000 | 1473 |
| 2022-01-01 | Piemonte | 12059 | 6737.0000 | 12601 |
| 2022-01-01 | Puglia | 6987 | 6737.0000 | 7215 |
| 2022-01-01 | Sardegna | 1729 | 6737.0000 | 1844 |
| 2022-01-01 | Sicilia | 7514 | 6737.0000 | 8527 |
| 2022-01-01 | Toscana | 7562 | 6737.0000 | 8263 |
| 2022-01-01 | Umbria | 1504 | 6737.0000 | 1623 |
| 2022-01-01 | Valle d'Aosta | 488 | 6737.0000 | 507 |
| 2022-01-01 | Veneto | 12395 | 6737.0000 | 13169 |
| 2022-01-02 | Abruzzo | 2642 | 6737.0000 | 2811 |
| 2022-01-02 | Basilicata | 635 | 6737.0000 | 681 |
| 2022-01-02 | Calabria | 1630 | 6737.0000 | 1887 |
| 2022-01-02 | Campania | 8474 | 6737.0000 | 9139 |
| 2022-01-02 | Emilia-Romagna | 14239 | 6737.0000 | 15088 |
| 2022-01-02 | Friuli Venezia Giulia | 4228 | 6737.0000 | 4487 |
| 2022-01-02 | Lazio | 9290 | 6737.0000 | 9823 |
| 2022-01-02 | Liguria | 4591 | 6737.0000 | 4873 |
| 2022-01-02 | Lombardia | 35140 | 6737.0000 | 37184 |
| 2022-01-02 | Marche | 3252 | 6737.0000 | 3418 |
| 2022-01-02 | Molise | 512 | 6737.0000 | 528 |
| 2022-01-02 | P.A. Bolzano | 1308 | 6737.0000 | 1357 |
| 2022-01-02 | P.A. Trento | 1423 | 6737.0000 | 1473 |
| 2022-01-02 | Piemonte | 12065 | 6737.0000 | 12601 |
| 2022-01-02 | Puglia | 6987 | 6737.0000 | 7215 |
| 2022-01-02 | Sardegna | 1731 | 6737.0000 | 1844 |
| 2022-01-02 | Sicilia | 7527 | 6737.0000 | 8527 |
| 2022-01-02 | Toscana | 7568 | 6737.0000 | 8263 |
| 2022-01-02 | Umbria | 1508 | 6737.0000 | 1623 |
| 2022-01-02 | Valle d'Aosta | 488 | 6737.0000 | 507 |
| 2022-01-02 | Veneto | 12408 | 6737.0000 | 13169 |
...
too many lines. Truncated!
如您所见,我们定义了两个窗口函数。OVER() 的特殊情况,没有任何参数,意味着整个结果集被视为应用聚合函数。第二个 OVER 子句基于区域字段定义分区。
计算每日新案例,非聚合函数
由于表中只有病例总数,因此我们希望每天计算新病例数。通过这种方式,我们可以了解大流行的状况是恶化还是正在改善。
我们需要定义一个窗口函数来跨越前一天的行,并计算今天的总事例数和昨天的总事例数之间的差异。
您可以使用以下查询,其中使用了新的特殊“非聚合”函数。
mysql> SELECT region, day, total_cases,
-> total_cases - LAG(total_cases) OVER(PARTITION BY region ORDER BY day ASC) AS 'new_cases'
-> FROM covid
-> WHERE day BETWEEN '2022-02-01' AND '2022-02-09';
+-----------------------+------------+-------------+-----------+
| region | day | total_cases | new_cases |
+-----------------------+------------+-------------+-----------+
| Abruzzo | 2022-02-01 | 219045 | NULL |
| Abruzzo | 2022-02-02 | 221638 | 2593 |
| Abruzzo | 2022-02-03 | 224389 | 2751 |
| Abruzzo | 2022-02-04 | 226689 | 2300 |
| Abruzzo | 2022-02-05 | 228922 | 2233 |
| Abruzzo | 2022-02-06 | 231001 | 2079 |
| Abruzzo | 2022-02-07 | 232079 | 1078 |
| Abruzzo | 2022-02-08 | 235013 | 2934 |
| Abruzzo | 2022-02-09 | 237059 | 2046 |
| Basilicata | 2022-02-01 | 65200 | NULL |
| Basilicata | 2022-02-02 | 66235 | 1035 |
| Basilicata | 2022-02-03 | 67252 | 1017 |
| Basilicata | 2022-02-04 | 68168 | 916 |
| Basilicata | 2022-02-05 | 69209 | 1041 |
| Basilicata | 2022-02-06 | 70007 | 798 |
| Basilicata | 2022-02-07 | 70435 | 428 |
| Basilicata | 2022-02-08 | 71610 | 1175 |
| Basilicata | 2022-02-09 | 72521 | 911 |
| Calabria | 2022-02-01 | 171780 | NULL |
| Calabria | 2022-02-02 | 173814 | 2034 |
| Calabria | 2022-02-03 | 176029 | 2215 |
| Calabria | 2022-02-04 | 177441 | 1412 |
| Calabria | 2022-02-05 | 178709 | 1268 |
| Calabria | 2022-02-06 | 180565 | 1856 |
| Calabria | 2022-02-07 | 181634 | 1069 |
| Calabria | 2022-02-08 | 184087 | 2453 |
| Calabria | 2022-02-09 | 185666 | 1579 |
…
too many lines. Truncated
LAG 函数是为窗口函数使用引入的“非聚合”函数。LAG 函数从分区中滞后当前行的行返回参数的值。如果未将任何内容指定为参数,则考虑前一行。所以,这是我们的情况,因为我们需要昨天的总案例来计算差异。
LAG 函数也可以按如下方式使用:
LAG(total_cases, 3)
在这种情况下,它将从滞后(比当前行早于)当前行的行中返回 total_cases 值,该行在其分区内滞后(位于当前行之前)。
非聚合函数
我们引入了 LAG() 函数作为非聚合函数。它不是唯一可用的。这些函数对查询中的每一行执行,使用与该行相关的行进行计算。
下表来自官方文档。有所有可用的非聚合函数可以与窗口函数一起使用。
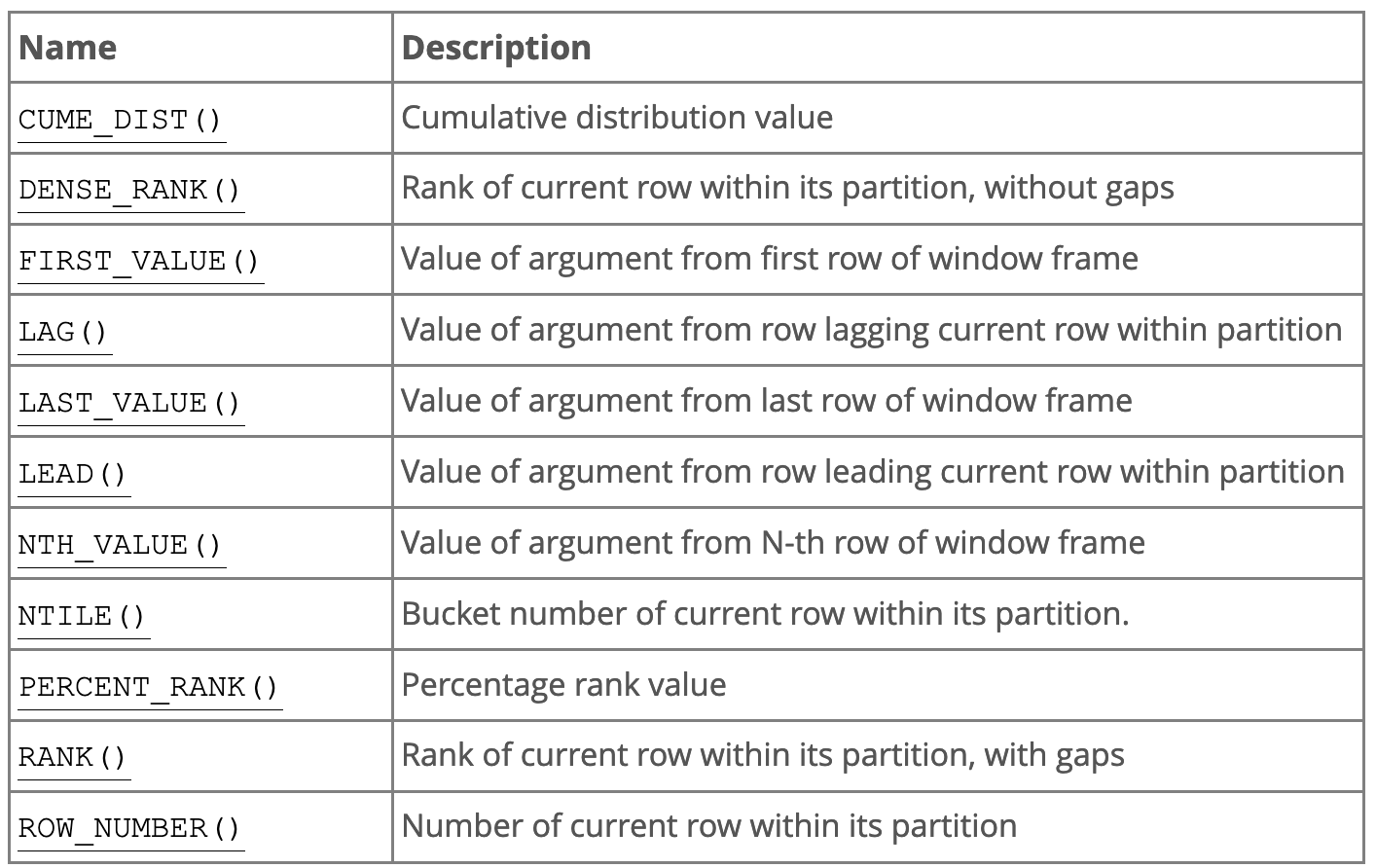
下面是一些非聚合函数用法的另一个示例:
mysql> SELECT ROW_NUMBER() OVER(PARTITION BY region ORDER BY day ROWS UNBOUNDED PRECEDING) AS 'row number',
-> region, day,
-> FIRST_VALUE(home_isolation) OVER(PARTITION BY region ORDER BY day ROWS UNBOUNDED PRECEDING) AS 'first',
-> LAST_VALUE(home_isolation) OVER(PARTITION BY region ORDER BY day ROWS UNBOUNDED PRECEDING) AS 'last'
-> FROM covid
-> WHERE day BETWEEN '2021-10-10' AND '2021-10-15';
+------------+-----------------------+------------+-------+-------+
| row number | region | day | first | last |
+------------+-----------------------+------------+-------+-------+
| 1 | Abruzzo | 2021-10-10 | 1439 | 1439 |
| 2 | Abruzzo | 2021-10-11 | 1439 | 1360 |
| 3 | Abruzzo | 2021-10-12 | 1439 | 1342 |
| 4 | Abruzzo | 2021-10-13 | 1439 | 1332 |
| 5 | Abruzzo | 2021-10-14 | 1439 | 1343 |
| 6 | Abruzzo | 2021-10-15 | 1439 | 1374 |
| 1 | Basilicata | 2021-10-10 | 1135 | 1135 |
| 2 | Basilicata | 2021-10-11 | 1135 | 1117 |
| 3 | Basilicata | 2021-10-12 | 1135 | 1104 |
| 4 | Basilicata | 2021-10-13 | 1135 | 1102 |
| 5 | Basilicata | 2021-10-14 | 1135 | 1055 |
| 6 | Basilicata | 2021-10-15 | 1135 | 1028 |
| 1 | Calabria | 2021-10-10 | 2818 | 2818 |
| 2 | Calabria | 2021-10-11 | 2818 | 2752 |
| 3 | Calabria | 2021-10-12 | 2818 | 2734 |
| 4 | Calabria | 2021-10-13 | 2818 | 2707 |
| 5 | Calabria | 2021-10-14 | 2818 | 2707 |
| 6 | Calabria | 2021-10-15 | 2818 | 2738 |
| 1 | Campania | 2021-10-10 | 6206 | 6206 |
| 2 | Campania | 2021-10-11 | 6206 | 6024 |
| 3 | Campania | 2021-10-12 | 6206 | 5843 |
| 4 | Campania | 2021-10-13 | 6206 | 5797 |
| 5 | Campania | 2021-10-14 | 6206 | 5881 |
| 6 | Campania | 2021-10-15 | 6206 | 5900 |
…
too many lines. Truncated
有关非聚合函数的更多详细信息,请参阅官方文档:https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html
命名窗口
查看上次执行的查询。我们已经使用了多个非聚合函数,并且我们已经多次定义了同一个窗口。我们可以通过仅定义一次提供特定名称的窗口来简化查询。然后,我们可以使用该名称来处理窗口,而无需重复定义。
然后可以按如下方式重写前面的查询:
mysql> SELECT ROW_NUMBER() OVER wf AS 'row_number',
-> region, day,
-> FIRST_VALUE(home_isolation) OVER wf AS 'first',
-> LAST_VALUE(home_isolation) OVER wf AS 'last'
-> FROM covid
-> WHERE day BETWEEN '2021-10-10' AND '2021-10-15'
-> WINDOW wf AS (PARTITION BY region ORDER BY day ROWS UNBOUNDED PRECEDING);
+------------+-----------------------+------------+-------+-------+
| row_number | region | day | first | last |
+------------+-----------------------+------------+-------+-------+
| 1 | Abruzzo | 2021-10-10 | 1439 | 1439 |
| 2 | Abruzzo | 2021-10-11 | 1439 | 1360 |
| 3 | Abruzzo | 2021-10-12 | 1439 | 1342 |
| 4 | Abruzzo | 2021-10-13 | 1439 | 1332 |
| 5 | Abruzzo | 2021-10-14 | 1439 | 1343 |
| 6 | Abruzzo | 2021-10-15 | 1439 | 1374 |
| 1 | Basilicata | 2021-10-10 | 1135 | 1135 |
| 2 | Basilicata | 2021-10-11 | 1135 | 1117 |
| 3 | Basilicata | 2021-10-12 | 1135 | 1104 |
| 4 | Basilicata | 2021-10-13 | 1135 | 1102 |
| 5 | Basilicata | 2021-10-14 | 1135 | 1055 |
| 6 | Basilicata | 2021-10-15 | 1135 | 1028 |
…
too many lines. Truncated
您可以使用查询末尾的 WINDOW 子句创建命名窗口。您提供一个名称和分区定义,然后只需在 OVER 子句中按名称引用该窗口。
可以在同一查询中创建和命名多个窗口函数,如以下示例所示:
mysql> SELECT region, day,
-> FIRST_VALUE(home_isolation) OVER wf_full AS 'first_full',
-> FIRST_VALUE(home_isolation) OVER wf_last4days AS 'first_last4days'
-> FROM covid
-> WHERE day BETWEEN '2021-12-01' AND '2021-12-10'
-> WINDOW wf_full AS (PARTITION BY region ORDER BY day ROWS UNBOUNDED PRECEDING),
-> wf_last4days AS (PARTITION BY region ORDER BY day ROWS BETWEEN 4 PRECEDING AND 0 FOLLOWING);
+-----------------------+------------+------------+-----------------+
| region | day | first_full | first_last4days |
+-----------------------+------------+------------+-----------------+
| Abruzzo | 2021-12-01 | 4116 | 4116 |
| Abruzzo | 2021-12-02 | 4116 | 4116 |
| Abruzzo | 2021-12-03 | 4116 | 4116 |
| Abruzzo | 2021-12-04 | 4116 | 4116 |
| Abruzzo | 2021-12-05 | 4116 | 4116 |
| Abruzzo | 2021-12-06 | 4116 | 4376 |
| Abruzzo | 2021-12-07 | 4116 | 4593 |
| Abruzzo | 2021-12-08 | 4116 | 4776 |
| Abruzzo | 2021-12-09 | 4116 | 4958 |
| Abruzzo | 2021-12-10 | 4116 | 4920 |
| Basilicata | 2021-12-01 | 1046 | 1046 |
| Basilicata | 2021-12-02 | 1046 | 1046 |
| Basilicata | 2021-12-03 | 1046 | 1046 |
| Basilicata | 2021-12-04 | 1046 | 1046 |
| Basilicata | 2021-12-05 | 1046 | 1046 |
| Basilicata | 2021-12-06 | 1046 | 1050 |
| Basilicata | 2021-12-07 | 1046 | 1094 |
| Basilicata | 2021-12-08 | 1046 | 1101 |
| Basilicata | 2021-12-09 | 1046 | 1125 |
| Basilicata | 2021-12-10 | 1046 | 1120 |
| Calabria | 2021-12-01 | 4374 | 4374 |
| Calabria | 2021-12-02 | 4374 | 4374 |
| Calabria | 2021-12-03 | 4374 | 4374 |
| Calabria | 2021-12-04 | 4374 | 4374 |
| Calabria | 2021-12-05 | 4374 | 4374 |
| Calabria | 2021-12-06 | 4374 | 4537 |
| Calabria | 2021-12-07 | 4374 | 4701 |
| Calabria | 2021-12-08 | 4374 | 5050 |
| Calabria | 2021-12-09 | 4374 | 5152 |
| Calabria | 2021-12-10 | 4374 | 5233 |
…
too many lines. Truncated
帧的分区
正如我们到目前为止测试的查询中已经显示的那样,我们可以在定义 Window 函数时提供一个 frame 子句。帧是当前分区的子集,帧子句指定如何定义子集。
帧是相对于当前行确定的,这使得帧能够根据当前行在其分区中的位置在分区内移动。
mysql> SELECT region, day,
-> SUM(intensive_care) OVER(PARTITION BY region ORDER BY day ROWS UNBOUNDED PRECEDING) AS 'running_total',
-> AVG(intensive_care) OVER(PARTITION BY region ORDER BY day ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS 'running_average'
-> FROM covid
-> WHERE day BETWEEN '2022-01-01' AND '2022-01-10';
+-----------------------+------------+---------------+-----------------+
| region | day | running_total | running_average |
+-----------------------+------------+---------------+-----------------+
| Abruzzo | 2022-01-01 | 21 | 21.5000 |
| Abruzzo | 2022-01-02 | 43 | 21.6667 |
| Abruzzo | 2022-01-03 | 65 | 22.3333 |
| Abruzzo | 2022-01-04 | 88 | 23.0000 |
| Abruzzo | 2022-01-05 | 112 | 23.6667 |
| Abruzzo | 2022-01-06 | 136 | 24.3333 |
| Abruzzo | 2022-01-07 | 161 | 25.3333 |
| Abruzzo | 2022-01-08 | 188 | 26.3333 |
| Abruzzo | 2022-01-09 | 215 | 26.3333 |
| Abruzzo | 2022-01-10 | 240 | 26.0000 |
| Basilicata | 2022-01-01 | 1 | 1.5000 |
| Basilicata | 2022-01-02 | 3 | 1.6667 |
| Basilicata | 2022-01-03 | 5 | 2.3333 |
| Basilicata | 2022-01-04 | 8 | 2.6667 |
| Basilicata | 2022-01-05 | 11 | 2.6667 |
| Basilicata | 2022-01-06 | 13 | 2.3333 |
| Basilicata | 2022-01-07 | 15 | 2.0000 |
| Basilicata | 2022-01-08 | 17 | 2.0000 |
| Basilicata | 2022-01-09 | 19 | 2.0000 |
| Basilicata | 2022-01-10 | 21 | 2.0000 |
| Calabria | 2022-01-01 | 28 | 28.0000 |
| Calabria | 2022-01-02 | 56 | 28.3333 |
| Calabria | 2022-01-03 | 85 | 28.6667 |
| Calabria | 2022-01-04 | 114 | 29.0000 |
| Calabria | 2022-01-05 | 143 | 29.3333 |
| Calabria | 2022-01-06 | 173 | 30.3333 |
| Calabria | 2022-01-07 | 205 | 31.3333 |
| Calabria | 2022-01-08 | 237 | 32.6667 |
| Calabria | 2022-01-09 | 271 | 33.3333 |
| Calabria | 2022-01-10 | 305 | 34.0000 |
…
too many lines. Truncated
Frame 分区的边界可以包括:
- UNBOUNDED PRECEDING:帧从分区的第一行开始。
- N PRECEDING:当前第一行之前的物理 N 行。N 可以是文字数字,也可以是计算结果为数字的表达式。
- CURRENT ROW:当前计算的行
- UNBOUNDED FOLLOWING:帧在分区中的最后一行结束。
- N FOLLOWING:当前行之后的物理行 N。
结论
窗口函数是MySQL 8.0中引入的一项新的惊人功能。此功能允许我们执行更少,更高效的查询来解决特定问题。如果没有 Window Functions,您可能会被迫创建临时表或无效视图,以便通过运行多个查询来获得相同的结果。
有关更多详细信息,您可以查看官方文档:
https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
在Percona Server for MySQL 8.0测试窗口函数。
原文标题:Window Functions in MySQL 8.0
原文作者:Corrado Pandiani
原文地址:https://www.percona.com/blog/window-functions-in-mysql-8-0/
