




本章通过展示如何使用mysql客户端程序来创建和使用一个简单的数据库来提供MySQL的教程介绍。mysql(有时被称为“终端监视器”或“监视器”)是一种交互式程序,可以连接到MySQL服务器,运行查询和查看结果。mysql也可以在批处理模式下使用:事先将查询放在一个文件中,然后告诉mysql执行文件的内容。这里介绍了两种使用mysql的方法。
要查看由mysql提供的选项列表,请使用--help选项调用它:
shell> mysql --help
本章假定你的机器上安装了mysql,并且你可以连接一个MySQL服务器。如果不是这样,请联系您的MySQL管理员。
本章介绍设置和使用数据库的整个过程。如果您只想访问现有数据库,则可能需要跳过描述如何创建数据库及其包含的表的章节。
因为这一章本质上是教程,所以很多细节都被省略了。请参阅手册的相关章节以获取更多关于此处所述主题的信息。
3.1 连接和断开服务
要连接到服务器,通常需要在调用mysql时提供一个MySQL用户名,最有可能的是密码。如果服务器在非登录的计算机上运行,则还需要指定主机名。请联系您的管理员,了解您应该使用什么连接参数(即要使用的主机,用户名和密码)。一旦你知道了正确的参数,你应该可以像这样连接:
shell> mysql -h host -u user -p
Enter password: ********
主机和用户代表MySQL服务器运行的主机名和你的MySQL帐户的用户名。为您的设置替换适当的值。********表示您的密码;当mysql显示Enter password:提示时输入。
如果您正在运行MySQL的同一台计算机上登录,则可以省略主机,只需使用以下命令:
shell> mysql -u user -p
如果尝试登录时收到错误消息,如ERROR 2002(HY000):无法通过套接字“/tmp/mysql.sock”(2)连接到本地MySQL服务器,这意味着MySQL服务器 守护进程(Unix)或服务(Windows)未运行。请咨询管理员或参阅适用于您的操作系统的第2章“安装和升级MySQL”一节。
一些MySQL安装允许用户作为匿名(未命名)用户连接到在本地主机上运行的服务器。如果你的机器上是这种情况,你应该可以通过调用mysql来连接到那个服务器,而不需要任何选项:
shell> mysql
连接成功后,可以通过在mysql>提示符下键入QUIT(或\ q)来断开连接:
mysql> QUIT
在unix环境 Control+D,也可以断开
3.2 执行查询
下面的例子是查询版本和当前时间:
SELECT VERSION(), CURRENT_DATE;
这个查询说明了有关mysql的几件事情:
1.一个命令通常由一个SQL语句和一个分号组成。(有些例外可以省略分号,前面提到的QUIT就是其中之一,以后我们会讨论的)。
2.当你发出一个命令时,mysql将它发送到服务器执行并显示结果,然后打印另一个mysql>提示符以表明它已准备好执行另一个命令。
3.mysql以表格形式(行和列)显示查询输出。第一行包含列的标签。随后的行是查询结果。通常,列标签是从数据库表中获取的列的名称。如果您正在检索表达式的值而不是表列(如上例所示),mysql会使用表达式本身来标记列。
4.mysql会显示返回的行数和查询执行的时间,这会让您大致了解服务器的性能。这些值是不精确的,因为它们代表挂钟时间(不是CPU或机器时间),并且因为它们受到诸如服务器负载和网络延迟等因素的影响。(为简便起见,本章其余示例中有时不会显示“set in”行)。
关键字是以任何小写被输入。以下查询是等效的:
mysql> SELECT VERSION(), CURRENT_DATE;
mysql> select version(), current_date;
mysql> SeLeCt vErSiOn(), current_DATE;
这是另一个查询。它演示了你可以使用mysql作为一个简单的计算器:
mysql> SELECT SIN(PI()/4), (4+1)*5;
+------------------+---------+
| SIN(PI()/4) | (4+1)*5 |
+------------------+---------+
| 0.70710678118655 | 25 |
+------------------+---------+
1 row in set (0.02 sec)
迄今为止显示的查询是相对较短的单行报表。您甚至可以在一行中输入多个语句。只要用分号结尾:
mysql> SELECT VERSION(); SELECT NOW();
+--------------+
| VERSION() |
+--------------+
| 5.6.1-m4-log |
+--------------+
1 row in set (0.00 sec)
+---------------------+
| NOW() |
+---------------------+
| 2010-08-06 12:17:13 |
+---------------------+
1 row in set (0.00 sec)
一个命令不需要全部放在一行中,所以需要多行的冗长命令不成问题。mysql通过查找终止分号来确定语句的结束位置,而不是通过查找输入行的结尾。(换句话说,mysql接受自由格式的输入:它收集输入行,但直到看到分号才执行它们。
下面是一个多行语句:
mysql> SELECT
-> USER()
-> ,
-> CURRENT_DATE;
+---------------+--------------+
| USER() | CURRENT_DATE |
+---------------+--------------+
| jon@localhost | 2010-08-06 |
+---------------+--------------+
在这个例子中,注意在输入多行查询的第一行之后,提示符是如何从mysql>到 - >更改的。这就是mysql如何表示它还没有看到一个完整的声明,正在等待其余的。提示是你的朋友,因为它提供了有价值的反馈。如果你使用这个反馈,你可以随时了解mysql正在等待什么。
如果您决定不想执行正在输入的命令,请通过键入\ c来取消它:
mysql> SELECT
-> USER()
-> \c
mysql>
这里也注意提示。在你输入\ c之后,它会切换回mysql>,提供反馈以表明mysql准备好了一个新的命令。
下表显示了您可能会看到的每个提示,并总结了它们对于mysql所处的状态的含义。
mysql> 准备一个新命令.
-> 等待多行命令的下一行
'> 等待下一行,等待一个单引号来结束字符串
"> 等待下一行,等待一个双引号来结束字符串
`> 等待下一行,等待一个`来结束标识符
/*> 等待下一行 等待结束 开始于 *的注释
多行语句通常会在您打算在一行中发出命令时意外发生,但忘记了终止分号。在这种情况下,mysql等待更多的输入:
mysql> SELECT USER()
->
如果这发生在你身上(你认为你已经输入了一个声明,但唯一的回应是一个 - >提示符),很可能mysql正在等待分号。如果你没有注意到提示信息是什么,你可能会在那里呆一会儿,然后才意识到你需要做什么。输入一个分号来完成语句,然后mysql执行它:
mysql> SELECT USER()
-> ;
+---------------+
| USER() |
+---------------+
| jon@localhost |
+---------------+
在字符串收集过程中会出现'>和>>提示符(另一种说法是MySQL正在等待字符串的完成)。在MySQL中,可以编写由'或"字符组成的字符串(例如'hello'或"goodbye"),而mysql允许你输入多行的字符串。当您看到">或'>提示符时,意味着您输入的行中包含以'或"引号字符开头的字符串,但尚未输入用于终止字符串的匹配引号。这往往表明你无意中遗漏了一个引号字符。例如:
mysql> SELECT * FROM my_table WHERE name = 'Smith AND age < 30;
'>
在这一点上,你做什么?最简单的是取消命令。但是,在这种情况下,不能只输入\ c,因为mysql会将其解释为正在收集的字符串的一部分。相反,输入结束引号字符(所以MySQL知道你已经完成了字符串),然后键入\ c:
mysql> SELECT * FROM my_table WHERE name = 'Smith AND age < 30;
'> '\c
mysql>
提示符回到mysql>,表示mysql准备好了一个新的命令。
`>提示符与'>和">提示符类似,但是表示您已经开始但没有完成反引号标识符。
3.3 创建和使用数据库
假设你家里有几只宠物(你的动物),你想跟踪各种类型的信息。您可以通过创建表来保存您的数据并加载所需的信息。然后,您可以通过从表格中检索数据来回答关于动物的各种问题。本节介绍如何执行以下操作:
1.创建一个数据库
2.创建一张表
3.将数据加载到表中
4.从之前的表中检索数据
5.使用多个表
使用show 语句来查看当前存在的数据库:
mysql> SHOW DATABASES;
+----------+
| Database |
+----------+
| mysql |
| test |
| tmp |
+----------+
mysql数据库描述了用户访问权限。测试数据库通常作为工作空间供用户尝试。
如果test数据库存在,尝试访问它:
mysql> USE test
Database changed
USE 和 QUIT一样,不需要分号。(如果你喜欢,你可以用分号来终止这样的语句;这没有害处。)USE声明在另一个方面也是特殊的:它必须在一行中给出。
假设你想执行下列命令:
mysql> GRANT ALL ON menagerie.* TO 'your_mysql_name'@'your_client_host';
其中your_mysql_name是分配给您的MySQL用户名,而your_client_host是从中连接到服务器的主机。
3.3.1 创建和选择一个数据库
如果管理员在设置权限时为您创建数据库,则可以开始使用它。否则,你需要自己创建它:
mysql> CREATE DATABASE menagerie;
在Unix下,数据库名称区分大小写(与SQL关键字不同),因此您必须始终将您的数据库引用为menagerie,而不是Menagerie,MENAGERIE或其他变体。表名也是如此。(在Windows下,这个限制不适用,尽管你必须在给定的查询中使用相同的字母表来引用数据库和表。但是由于各种原因,推荐的最佳做法总是使用与 该数据库已创建的相同大小邪恶。)
注意:
如果在尝试创建数据库时遇到错误(例如错误1044(42000):访问被拒绝用户monty'@'localhost'访问数据库'menagerie',这意味着您的用户帐户没有必要的权限来执行 。
创建数据库不会选择使用; 你必须明确地做到这一点。要使menagerie
成为当前的数据库,请使用以下命令:
mysql> USE menagerie
Database changed
你的数据库只需要创建一次,但是每次开始mysql会话时都必须选择它。您可以通过发出USE语句来执行此操作,如示例中所示。或者,您可以在调用mysql时在命令行上选择数据库。只需在您可能需要提供的任何连接参数之后指定其名称即可。例如:
shell> mysql -h host -u user -p menagerie
Enter password: ********
重要:
在刚刚显示的命令中的menagerie不是你的密码。如果要在-p选项之后在命令行上提供密码,则必须在不插入空格的情况下执行此操作(例如,作为-pmypassword而不是-p mypassword)。但是,将密码放在命令行上是 不建议这样做,因为这样做会让其他用户在您的计算机上登录。
注意:
您可以随时使用SELECT DATABASE()查看选择的是哪个数据库。
创建一张表:
创建数据库是很简单的部分,但是在此时它是空的,因为SHOW TABLES告诉你:
mysql> SHOW TABLES;
Empty set (0.00 sec)
更难的部分是决定你的数据库的结构应该是什么:你需要什么表和每个列中应该包含哪些列。
CREATE TABLE 语句创建 pet 表
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
-> species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
此时show table 就会出现刚刚新建的表
mysql> SHOW TABLES;
+---------------------+
| Tables in menagerie |
+---------------------+
| pet |
+---------------------+
要验证您的表是否按照您的预期创建,请使用DESCRIBE语句:
mysql> DESCRIBE pet;
3.3.3 加载数据到表
可以使用 LOAD DATA 和INSERT 语句
例如,构建一个 pet.txt,每行内容如下,\N表示Null值,值与表列一一对应:
Whistler Gwen bird \N 1997-12-09 \N
然后使用语句,加载pet.txt到pet 表:
mysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet;
(这个感觉和sqlldr类似)
如果是windows上编辑器的文本,那么使用 \r\n 作为行终止符,可以使用下列语句替代:
mysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet
-> LINES TERMINATED BY '\r\n';
(如果是 apple OS X,是 LINES TERMINATED BY '\r'.)
也可以指定字段值分隔符,默认是tab和换行
新增一行的话,也可以使用insert 语句:
mysql> INSERT INTO pet
-> VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
在insert 语句中,可以直接使用NULL,而不用像LOAD DATA中使用 \N
检索特定语句,支持 OR 和AND 的逻辑操作符:
mysql> SELECT * FROM pet WHERE (species = 'cat' AND sex = 'm')
-> OR (species = 'dog' AND sex = 'f');
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
这意味着对于除了大小写之外相同的列,排序是未定义的。您可以像使用BINARY一样强制对列进行区分大小写排序:ORDER BY BINARY col_name。
默认是升序排列,也可以使用desc 关键字来进行降序排列
日期计算:
计算当前宠物年龄,可以使用 TIMESTAMPDIFF() 函数
它的论据是你想要表达结果的单位,以及两个取得差异的日期。下面的查询显示了每个宠物的出生日期,当前日期和年龄。别名(年龄)用于使最终输出列标签更有意义。
mysql> SELECT name, birth, CURDATE(),
-> TIMESTAMPDIFF(YEAR,birth,CURDATE()) AS age
-> FROM pet;
+----------+------------+------------+------+
| name | birth | CURDATE() | age |
+----------+------------+------------+------+
| Fluffy | 1993-02-04 | 2003-08-19 | 10 |
| Claws | 1994-03-17 | 2003-08-19 | 9 |
| Buffy | 1989-05-13 | 2003-08-19 | 14 |
| Fang | 1990-08-27 | 2003-08-19 | 12 |
还有一些时间函数
YEAR(), MONTH(), and DAYOFMONTH()用来格式化日期,例如:
mysql> SELECT name, birth, MONTH(birth) FROM pet;
+----------+------------+--------------+
| name | birth | MONTH(birth) |
+----------+------------+--------------+
| Fluffy | 1993-02-04 | 2 |
| Claws | 1994-03-17 | 3 |
| Buffy | 1989-05-13 | 5 |
| Fang | 1990-08-27 | 8 |
| Bowser | 1989-08-31 | 8 |
+----------+------------+--------------+
SELECT name, birth FROM pet WHERE MONTH(birth) = 5;
+-------+------------+
| name | birth |
+-------+------------+
| Buffy | 1989-05-13 |
+-------+------------+
两种方式可以查询当前月份下一个月的值:
一种是使用 DATE_ADD
mysql> SELECT name, birth FROM pet
-> WHERE MONTH(birth) = MONTH(DATE_ADD(CURDATE(),INTERVAL 1 MONTH));
--不会返回13月,因为没有这个月分
还一种是使用MOD
mysql> SELECT name, birth FROM pet
-> WHERE MONTH(birth) = MOD(MONTH(CURDATE()), 12) + 1;
MONTH() 返回 1到12的数目。MOD(something,12)返回0-11,当当前月是12月时,返回0,那么下一个月+1就是1月。
3.3.4.6 空值的处理
要测试 NULL ,使用 IS NULL 和 IS NOT NULL 操作,例如:
mysql> SELECT 1 IS NULL, 1 IS NOT NULL;
+-----------+---------------+
| 1 IS NULL | 1 IS NOT NULL |
+-----------+---------------+
| 0 | 1 |
+-----------+---------------+
--此处1为真,0为假。shell 里面是非0为假
你不能使用比较操作符例如=,<或者<>来测试NULL:
mysql> SELECT 1 = NULL, 1 <> NULL, 1 < NULL, 1 > NULL;
+----------+-----------+----------+----------+
| 1 = NULL | 1 <> NULL | 1 < NULL | 1 > NULL |
+----------+-----------+----------+----------+
| NULL | NULL | NULL | NULL |
+----------+-----------+----------+----------+
由于任何与NULL的算术比较的结果也是NULL,所以不能从这种比较中获得任何有意义的结果。
在MYSQL 中,0或者NULL 意味着false,其他的以为是true。默认布尔真的值是1.
在GROUP BY中,两个NULL值被认为是等价的。
在ORDER BY 中,如果是使用asc排序 ,NULL 值会在最前面显示,如果是DESC,会在最后显示。
使用NULL时的一个常见错误是假定不能将零或空字符串插入定义为NOT NULL的列中,但情况并非如此。这些实际上是值,而NULL意味着“没有值”。您可以通过使用IS [NOT] NULL来轻松测试,如下所示:
mysql> SELECT 0 IS NULL, 0 IS NOT NULL, '' IS NULL, '' IS NOT NULL;
+-----------+---------------+------------+----------------+
| 0 IS NULL | 0 IS NOT NULL | '' IS NULL | '' IS NOT NULL |
+-----------+---------------+------------+----------------+
| 0 | 1 | 0 | 1 |
+-----------+---------------+------------+----------------+
因此,将一个零或空字符串插入一个NOT NULL列是完全可能的,因为这些实际上不是NULL。
3.3.4.7 模式匹配
MySQL提供了标准的SQL模式匹配,以及基于扩展正则表达式的模式匹配形式,类似于Unix工具(如vi,grep和sed)所使用的正则表达式。
SQL模式匹配使您可以使用“_”来匹配任何单个字符和“%”以匹配任意数量的字符(包括零字符)。在MySQL中,默认情况下,SQL模式不区分大小写。下面显示了一些示例。当您使用SQL模式时,不要使用=或<>; 改用LIKE或NOT LIKE比较运算符。
例如:
以b开头
SELECT * FROM pet WHERE name LIKE 'b%';
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
以 fy结束:
mysql> SELECT * FROM pet WHERE name LIKE '%fy';
+--------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+-------+
| Fluffy | Harold | cat | f | 1993-02-04 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+--------+--------+---------+------+------------+-------+
名称包含w的:
mysql> SELECT * FROM pet WHERE name LIKE '%w%';
+----------+-------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+------------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
| Whistler | Gwen | bird | NULL | 1997-12-09 | NULL |
+----------+-------+---------+------+------------+------------+
要查找包含5个字符的名称,请使用“_”模式字符的五个实例:
mysql> SELECT * FROM pet WHERE name LIKE '_____';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
MySQL提供的其他类型的模式匹配使用扩展正则表达式。当你测试这种模式的匹配时,使用REGEXP和NOT REGEXP运算符(或RLIKE和NOT RLIKE,它们是同义词)。
以下列表描述了扩展正则表达式的一些特征:
•“.”匹配任何单个字符。
•字符类“[...]”与括号内的任何字符匹配。例如,“[abc]”匹配
“a”,“b”或“c”。要命名一系列字符,请使用短划线。“[a-z]”匹配任何字母,而“[0-9]”匹配任何数字。
•“*”匹配前面的事物的零个或多个实例。例如,“x *”匹配任何数量的
“x”字符,“[0-9] *”可以匹配任意数量的数字,“.*”可以匹配任何数量的任何字符。
• 如在被测试值的任何地方成功,则REGEXP模式匹配成功。(这个不同于LIKE模式匹配,只有当模式匹配整个值时才能成功。)
•要锚定一个模式,以便它必须匹配被测试值的开始,请使用“^”,在模式结束时使用“$”。
为了演示如何扩展正则表达式的工作,先前显示的LIKE查询被重写
这里使用REGEXP。
mysql> SELECT * FROM pet WHERE name REGEXP '^b';
+--------+--------+---------+------+------------+------------+
| name | owner | species | sex | birth | death |
+--------+--------+---------+------+------------+------------+
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
| Bowser | Diane | dog | m | 1989-08-31 | 1995-07-29 |
+--------+--------+---------+------+------------+------------+
这里是忽略大小写的,如果要强制大小写,使用BINARY,下面的查询只匹配小写b:
mysql> SELECT * FROM pet WHERE name REGEXP BINARY '^b';
要查找包含5个字符的名称,请使用“^”和“$”来匹配名称的开始和结尾,以及两个“。”之间的五个实例:
mysql> SELECT * FROM pet WHERE name REGEXP '^.....$';
+-------+--------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+-------+--------+---------+------+------------+-------+
| Claws | Gwen | cat | m | 1994-03-17 | NULL |
| Buffy | Harold | dog | f | 1989-05-13 | NULL |
+-------+--------+---------+------+------------+-------+
您也可以使用{n}(“repeat-n-times”)运算符来编写以前的查询:
--下列查询和上面的一个是等价的
mysql> SELECT * FROM pet WHERE name REGEXP '^.{5}$';
3.3.4.7 统计行数
使用count(*) 来统计行数:
mysql> SELECT owner, COUNT(*) FROM pet GROUP BY owner;
+--------+----------+
| owner | COUNT(*) |
+--------+----------+
| Benny | 2 |
| Diane | 2 |
| Gwen | 3 |
| Harold | 2 |
+--------+----------+
如果除了COUNT()值以外还要其他要选择的列,则应该存在一个GROUP BY子句来命名这些相同的列。否则,会发生以下情况:
1.如果 ONLY_FULL_GROUP_BY SQL 模式被启用,一个错误将发生:
mysql> SET sql_mode = 'ONLY_FULL_GROUP_BY';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT owner, COUNT(*) FROM pet;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression
#1 of SELECT list contains nonaggregated column 'menagerie.pet.owner';
this is incompatible with sql_mode=only_full_group_by
2.如果 ONLY_FULL_GROUP_BY 没被启用,
通过将所有行视为单个组来处理查询,但为每个命名列选择的值是不确定的。服务器可以自由选择任何行的值:
mysql> SET sql_mode = '';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT owner, COUNT(*) FROM pet;
+--------+----------+
| owner | COUNT(*) |
+--------+----------+
| Harold | 8 |
+--------+----------+
1 row in set (0.00 sec)
3.3.4.9 多表连接
创建另一个event 表
mysql> CREATE TABLE event (name VARCHAR(20), date DATE,
-> type VARCHAR(15), remark VARCHAR(255));
关联查询
mysql> SELECT pet.name,
-> (YEAR(date)-YEAR(birth)) - (RIGHT(date,5)<RIGHT(birth,5)) AS age,
-> remark
-> FROM pet INNER JOIN event
-> ON pet.name = event.name
-> WHERE event.type = 'litter';
这个查询中需要注意下列事情:
1.FROM子句连接两个表,因为查询需要从这两个表中提取信息。
2.在合并(加入)来自多个表格的信息时,您需要指定一个表格中的记录如何与另一个表格中的记录进行匹配。这很容易,因为他们都有name 字段。查询使用ON子句根据name值匹配两个表中的记录。
查询使用INNER JOIN来组合表。当且仅当两个表都满足ON子句中指定的条件时,INNER JOIN才允许任一表中的行出现在结果中。在这
例如,ON子句指定pet表中的名称列必须与事件表中的名称列匹配。如果一个名称出现在一个表中,而另一个不出现,则该行不会出现在结果中,因为ON子句中的条件失败。
--等值连接
3.因为name 列出现在两个表中,所以在引用列时必须具体说明您所指的是哪个表。这是通过将表名添加到列名来完成的(表里面特有的列可以不用表别名特别定义,但是使用了之后更清晰)。
3.5 以Batch模式使用mysql
在前面的章节中,您以交互方式使用mysql来输入查询并查看结果。你也可以在批处理模式下运行mysql。要做到这一点,把你想要运行的命令放在一个文件中,然后告诉mysql从文件中读取它的输入:
shell> mysql < batch-file
如果你在Windows下运行mysql,并在文件中有一些导致问题的特殊字符,你可以这样做:
C:\> mysql -e "source batch-file"
如果您需要在命令行中指定连接参数,则该命令可能如下所示:
shell> mysql -h host -u user -p < batch-file
Enter password: ********
当你以这种方式使用mysql时,你是创建一个脚本文件,然后执行脚本。
如果您希望脚本继续运行,即使其中的某些语句产生错误,可以使用--force命令行选项。
为什么使用脚本,这里有下列原因:
1.如果您反复运行查询(例如,每天或每周),将其作为脚本可以避免每次执行时重新输入查询。
2.您可以通过复制和编辑脚本文件,从现有的查询生成新的查询。
3.批处理模式在开发查询时也很有用,特别是对于多行命令或多语句序列的命令。如果你犯了一个错误,你不必重新键入所有的东西。只需编辑脚本来纠正错误,然后告诉mysql再次执行它。...
4.如果您的查询产生大量输出,则可以通过传页面运行输出,而不是通过滚动屏幕的顶部来滚动输出:
shell> mysql < batch-file | more
5.也可以重定向到文件中
shell> mysql < batch-file > mysql.out
6.您可以将脚本分发给其他人,以便他们也可以运行这些命令。
7.有些情况下不允许交互式使用,例如,当您从cron作业运行查询时。在这种情况下,您必须使用批处理模式。
8.在批处理模式下运行mysql时,默认的输出格式是不同的(更简洁),而不是交互式使用它。例如,当交互式运行mysql时,SELECT DISTINCT种类FROM pet的输出如下所示:
+---------+
| species |
+---------+
| bird |
| cat |
| dog |
| hamster |
| snake |
+---------+
当批处理模式时,输出会像如下:
species
bird
cat
dog
hamster
snake
如果要以批处理模式获取交互输出格式,请使用mysql -t。要向输出回显执行的命令,请使用mysql -v。
你可以在mysql 提示行中使用 source命令或\.命令来调用脚本:
mysql> source filename;
mysql> \. filename
3.6.5 使用用户定义的变量
例如,要查找价格最高和最低的商品,可以这样做:
mysql> SELECT @min_price:=MIN(price),@max_price:=MAX(price) FROM shop;
mysql> SELECT * FROM shop WHERE price=@min_price OR price=@max_price;
+---------+--------+-------+
| article | dealer | price |
+---------+--------+-------+
| 0003 | D | 1.25 |
| 0004 | D | 19.95 |
+---------+--------+-------+
也可以将数据库对象(如表或列)的名称存储在用户变量中,然后在SQL语句中使用此变量; 但是,这需要使用准备好的声明。
3.6.6 使用外键
在Mysql 中,InnoDB 支持检查外键约束。
在仅仅只连接2个表时,并不需要外键。对于除InnoDB之外的存储引擎,定义一个列以使用REFERENCES tbl_name(col_name)子句是没有实际效果的,并且只作为备忘录或注释给您,您当前定义的列 引用另一个表中的列。当使用这种语法时,意识到这一点非常重要:
1.MySQL不执行任何形式的CHECK来确保col_name实际上存在于tbl_name中(或者甚至是tbl_name本身存在)。
2.MySQL不会对tbl_name执行任何操作,例如删除行以响应您正在定义的表中的行所采取的操作; 换句话说,这个语法不会导致ON DELETE或ON UPDATE行为。(尽管您可以将ON DELETE或ON UPDATE子句作为REFERENCES子句的一部分写入,但也会被忽略。)
3.这个语法创建一个列; 它不会创建任何类型的索引或键。
您可以使用如此创建的列作为连接列,如下所示:
drop table person;
drop table shirt;
CREATE TABLE person (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
name CHAR(60) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE shirt (
id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
style ENUM('t-shirt', 'polo', 'dress') NOT NULL,
color ENUM('red', 'blue', 'orange', 'white', 'black') NOT NULL,
owner SMALLINT UNSIGNED NOT NULL REFERENCES person(id),
PRIMARY KEY (id)
);
INSERT INTO person VALUES (NULL, 'Antonio Paz');
SELECT @last := LAST_INSERT_ID() ;
INSERT INTO shirt VALUES
(NULL, 'polo', 'blue', @last),
(NULL, 'dress', 'white', @last),
(NULL, 't-shirt', 'blue', @last);
INSERT INTO person VALUES (NULL, 'Lilliana Angelovska');
SELECT @last := LAST_INSERT_ID();
INSERT INTO shirt VALUES
(NULL, 'polo', 'blue', @last),
(NULL, 'dress', 'white', @last),
(NULL, 't-shirt', 'blue', @last);
INSERT INTO person VALUES (NULL, 'Lilliana Angelovska');
SELECT @last := LAST_INSERT_ID();
INSERT INTO shirt VALUES
(NULL, 'dress', 'orange', @last),
(NULL, 'polo', 'red', @last),
(NULL, 'dress', 'blue', @last),
(NULL, 't-shirt', 'white', @last);
SELECT s.* FROM person p INNER JOIN shirt s
ON s.owner = p.id
WHERE p.name LIKE 'Lilliana%'
AND s.color <> 'white';
--LAST_INSERT_ID() 是自增字段 AUTO_INCREMENT 的执行insert 语句的次数。和一次insert多少行无关,只与执行多少次insert 语句有关。生命周期在会话内。
--SELECT @@innodb_autoinc_lock_mode; 默认值为1,可以使用IGNORE 关键字忽略 AUTO_INCREMENT增长的行,此时,LAST_INSERT_ID() 不会增加。
INSERT IGNORE INTO t (val) VALUES (1),(2);
--要使得表自增字段从非1开始,使用下列语句:
ALTER TABLE tbl AUTO_INCREMENT = 100;
-- 如果该列被声明为NOT NULL,那么也可以将NULL分配给该列以生成序列号。如果给定了其他值,那么序列将被重置,这样下一个自动生成的值会着insert的值增加。
例如:插入了12,那么下一个值就是13,中间的序列值会被跳过
此时使用 SHOW CREATE TABLE 或DESCRIBE 来检查,会发现REFERENCES
相关的语句不会显示
CREATE TABLE `shirt` (
`id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`style` enum('t-shirt','polo','dress') NOT NULL,
`color` enum('red','blue','orange','white','black') NOT NULL,
`owner` smallint(5) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
这种方式使用REFERENCES作为注释或列定义中的“提醒”与MyISAM表一起使用。
--实际在innodb中测试,仅仅是用REFERENCES的建表语法,最后好像也是被忽略。
对于InnoDB表,如果在一系列INSERT语句的中间修改包含自增值的列,请小心。例如,如果使用UPDATE语句在自动增量列中放置一个新的较大的值,则随后的INSERT可能会遇到“重复项”错误。
对于MyISAM表,您可以在多列索引中的辅助列上指定AUTO_INCREMENT。在这种情况下,AUTO_INCREMENT列的生成值计算为MAX(auto_increment_column)+ 1 WHERE prefix = given-prefix。当你想把数据放入有序组时,这很有用。
CREATE TABLE animals (
grp ENUM('fish','mammal','bird') NOT NULL,
id MEDIUMINT NOT NULL AUTO_INCREMENT,
name CHAR(30) NOT NULL,
PRIMARY KEY (grp,id)
) ENGINE=MyISAM;
INSERT INTO animals (grp,name) VALUES
('mammal','dog'),('mammal','cat'),
('bird','penguin'),('fish','lax'),('mammal','whale'),
('bird','ostrich');
SELECT * FROM animals ORDER BY grp,id;
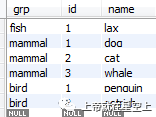
--ENUM 此处是枚举类型,可以使用枚举索引查询,例如:
select * from animals where grp=3 等价于:
select * from animals where grp='bird'
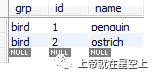
1.在这种情况下(当AUTO_INCREMENT列是多列索引的一部分时),如果删除任何组中具有最大AUTO_INCREMENT值的行,则会重新使用AUTO_INCREMENT值。即使对于其中AUTO_INCREMENT值通常不被重用的MyISAM表,也会发生这种情况。
--也就是说,当把id=2 的行删除,那么再插入的时候,还是会从2开始,自增序列重置为最大值,保持连续。
2.如果AUTO_INCREMENT列是多个索引的一部分,则MySQL使用以AUTO_INCREMENT列开头的索引(如果有的话)生成序列值。例如,如果动物表包含索引PRIMARY KEY(grp,id)和INDEX(id),则MySQL将忽略用于生成序列值的PRIMARY KEY。结果,该表将包含一个单一的序列,而不是每个grp值的序列。
例如:
truncate table animals;
create index test_idx1 on animals(id);
INSERT INTO animals (grp,name) VALUES
('mammal','dog'),('mammal','cat'),
('bird','penguin'),('fish','lax'),('mammal','whale'),
('bird','ostrich');
SELECT * FROM animals ORDER BY grp,id;
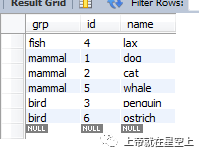
--创建了以自增列为左前导列后,发展自增字段为单一列。
3.7 将apache 加载到 Mysql 表中
你可以变更 apache 日志格式,让Mysql更容易的加载:
LogFormat \
"\"%h\",%{%Y%m%d%H%M%S}t,%>s,\"%b\",\"%{Content-Type}o\", \
\"%U\",\"%{Referer}i\",\"%{User-Agent}i\""
可以使用类似下面的语句进行加载:
LOAD DATA INFILE '/local/access_log' INTO TABLE tbl_name
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\'
命名表应创建为具有与LogFormat行写入日志文件的列相对应的列。
