文 | Youngshell
审 | bindingdai
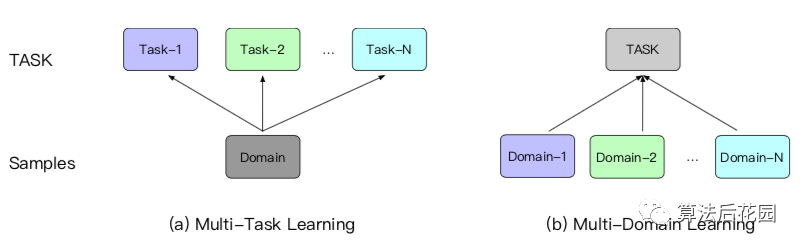
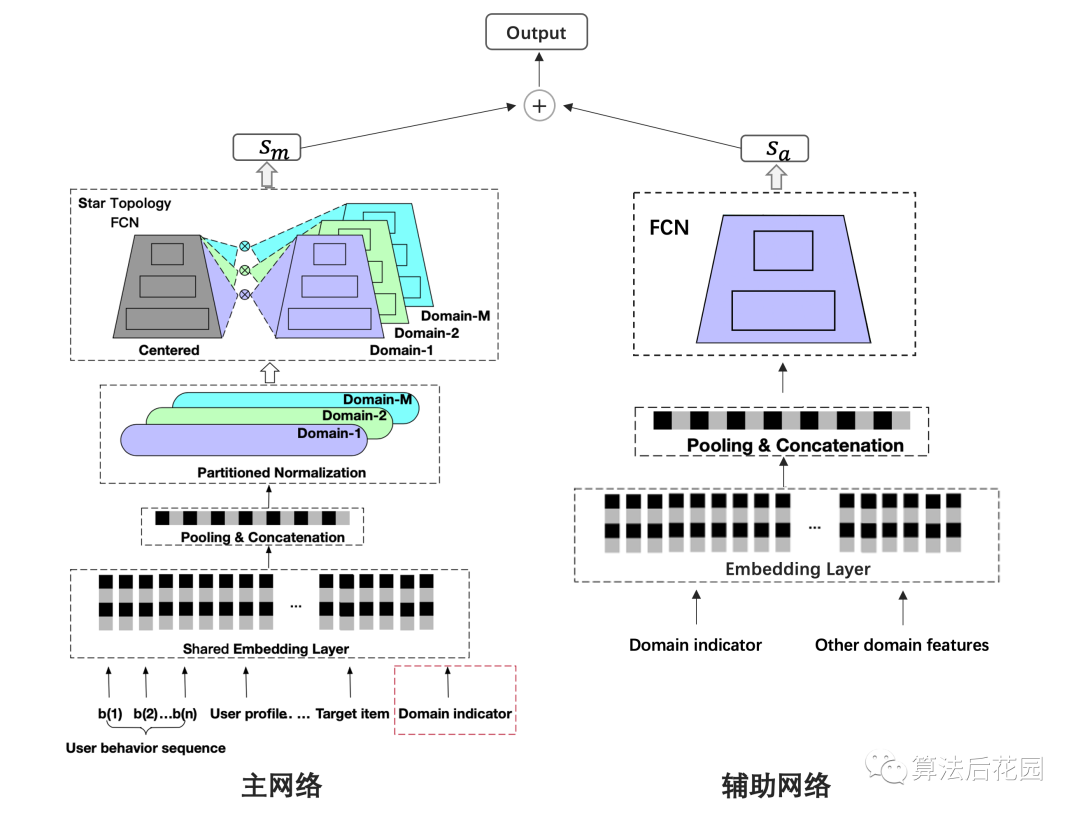
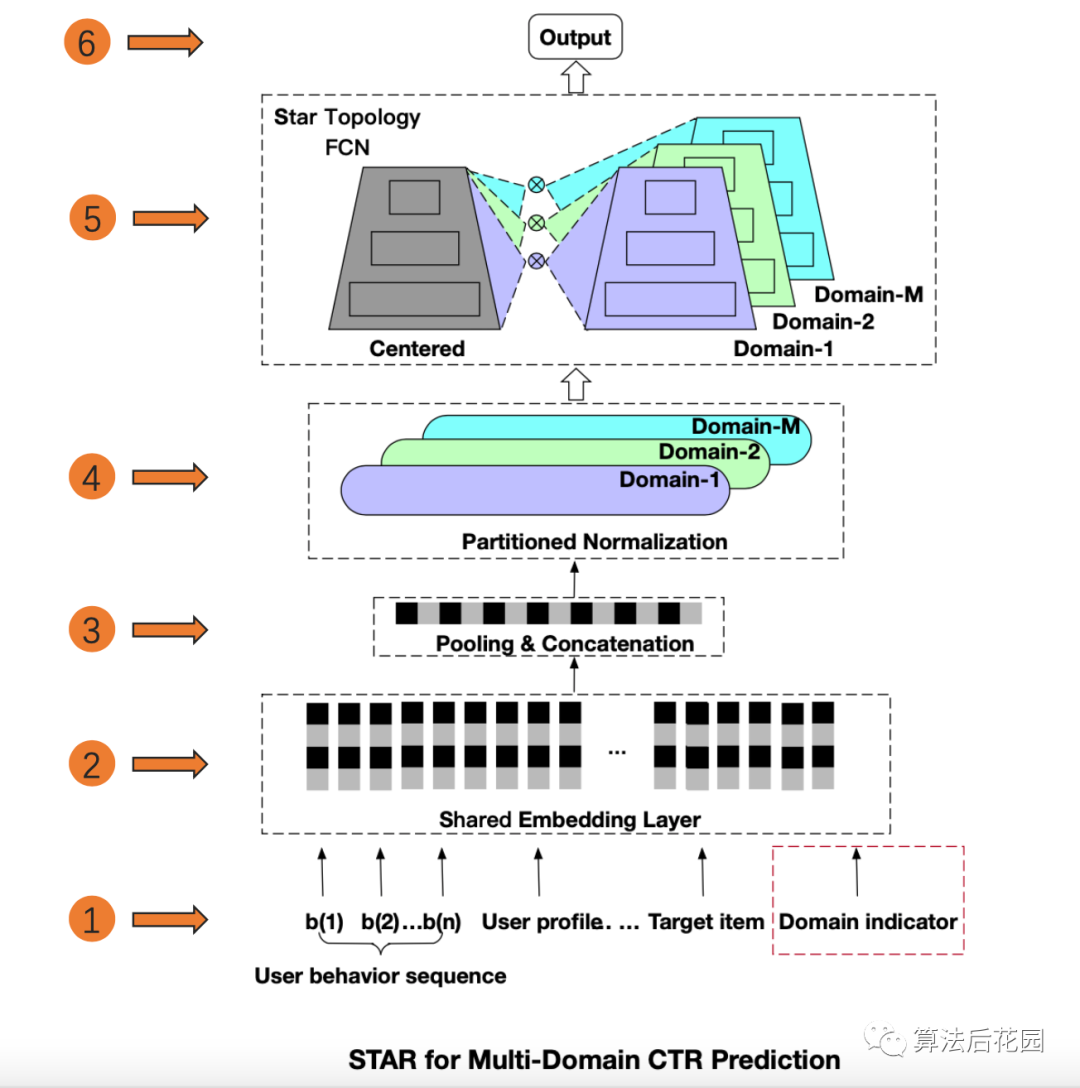
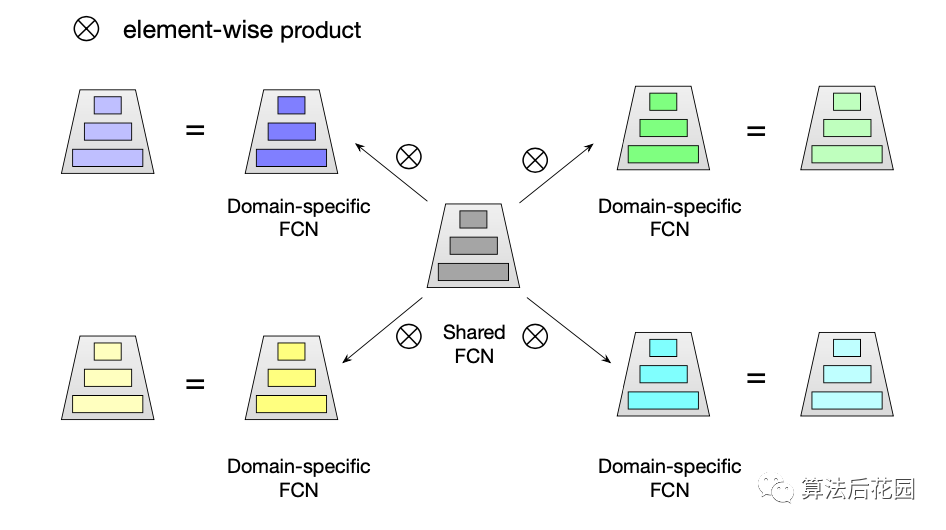
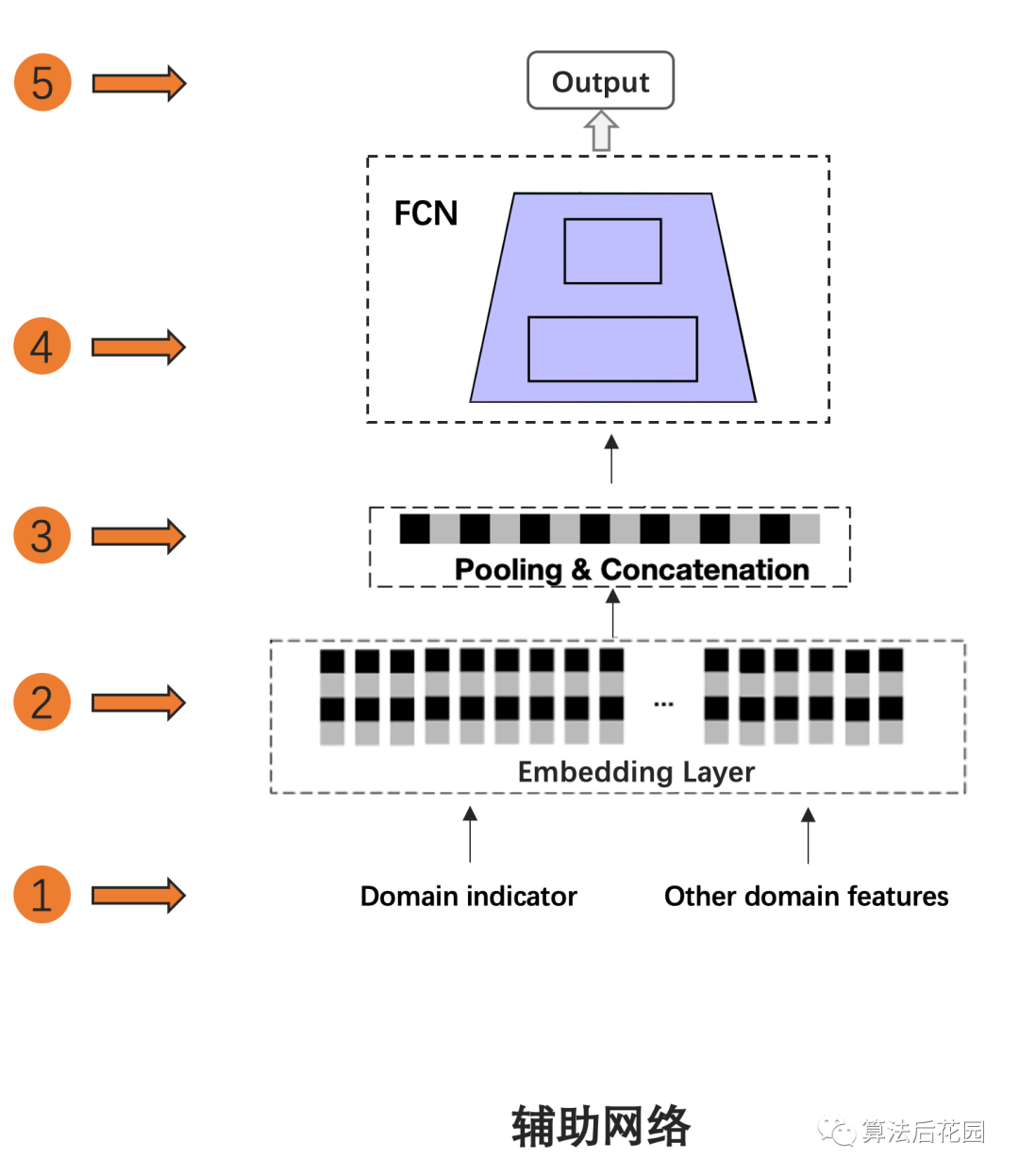
多场景建模是推荐系统CTR预估领域比较热门的一个研究方向,本次给大家分享的论文是: 《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》 这篇论文来自阿里妈妈定向广告技术团队,文章发表在CIKM,从推荐系统多场景建模的难点出发,提出了STAR模型,并在阿里妈妈千亿营收的广告系统上部署全量上线。 本质上,STAR提供的是一种“混合多分布下的差异化精准建模方案” ,也就是说,STAR不仅提供了一种多场景建模方案,如若你没有多场景建模的需求,但是你想对混合多分布的数据进行更精细化的建模,例如,分人群进行精细化建模,那么这篇论文可以帮你打开思路。此外,STAR的亮点之一是其应用的PN(Partitioned Normalization),PN是STAR对于多场景建模问题基于BN(Batch Normalization)做的优化,本文也会带大家复习一下BN的常规面试考点。 首先,我们需要理清楚一系列背景问题:(1)什么是多场景?(2)为什么需要多场景建模?(3)初看多场景建模总感觉跟多任务建模很像,但他们真的不一样,区别到底是什么?(4)多场景建模的难点是什么?传统方法有什么缺点?这些问题,下文会逐一解释。 我们常用的app中,很多都有多场景。比如你要买一件衣服,打开淘宝,接下来的操作流程可能是: 首页推荐Feed(“猜你喜欢”推荐场景)→宝贝详情页浏览,详情页下方推荐Feed(“看了又看”推荐场景,这里推荐的是该宝贝所属店铺的商品)→加入购物车,购物车页下方推荐Feed(“你可能还喜欢”推荐场景)→支付,支付页下方推荐Feed(购后推荐场景)。 上述,每个推荐页面都对应了一个场景(Domain),这里“场景”指的就是业务场景,淘宝中还有很多大大小小的推荐场景。上述的每个推荐场景都会解决一个问题,即CTR预估。 多场景建模指的是多场景联合建模,多场景建模是从效果和效率两方面来考虑的。 从效果上来看,一方面,不同的业务场景其用户和item有交集,因此各业务场景存在共性,不同场景的信息共享有助于场景间的知识迁移,对于模型的学习是有益的。另一方面,单个业务场景的数据量往往有限,尤其是小业务场景,单独建模会增加模型的训练难度。 从效率上来看,各场景单独建模会造成大量的资源消耗,且需要更多的人力成本。当业务场景的数量达到上百个的时候,这将造成过度的负担。 STAR提供了一种可以同时处理多个业务场景,且兼顾效率和效果的方案。 多场景学习是为不同的业务场景做预估,但解决的是同一个预估任务,例如STAR解决的是CTR预估任务,该任务是跨不同业务场景的。由于不同业务场景解决的是同一个任务,他们的label空间是一致的。不同业务场景的数据分布是不同的,即不同业务场景的用户行为不同,导致各场景的真实CTR是不同的。 多任务学习一般解决的是同一个业务场景的多个任务,多个任务的label空间可能不同,例如CTR和CVR联合预估。由于任务的异构性,现有的多任务学习方法侧重于在底层共享信息,在输出层保持每一个任务对应一个输出。 举例来说,在短视频推荐领域,多任务学习问题可以是为单个视频推荐场景同时预估CTR和观看时长,多场景CTR预估问题是为多个视频推荐场景来做CTR预估。 不同的业务场景其用户和item有交集,因此各业务场景存在共性。但不同的业务场景都有自己特有的用户群体和item,各场景的用户行为也是不同的,即使同一个用户在不同的业务场景中可能有不同的行为,这些差异会带来不同业务场景中数据分布的差异,从而导致各场景的真实CTR是不同的。 我们可以训练一个模型为所有业务场景进行serving,但是这很难捕捉到不同场景的差异性,很难做到同时对所有场景都预估精确。但若每个业务场景各训练一个模型,就没有充分使用其它场景的数据,没有学习到场景之间的共性。 对于多场景之间的共性和差异性,如何有效建模?这就是多场景建模的难点。 STAR从多场景建模的难点出发,既可 捕 捉到不同场景的共性, 也可捕捉到不同场景的差异,既可实现场景间的知识迁移,又可实现各场景差异化的精确预估。 STAR解决的是多场景CTR预估问题,我们将多场景CTR预估问题定义为:推荐系统需同时为 注意,多场景建模的特征分为两类,一类是各业务场景的通用特征,一类是各业务场景独有的特征,这两类特种都非常重要。上文只提到了第一类特征,即 针对多场景CTR预估问题,STAR既可以学习到不同业务场景之间的共性,也可以学习到其差异性,从而做到对不同的业务场景进行差异化精准预估。STAR包括主网络和辅助网络,总体结构图如下。 说明:论文中只给出了主网络结构图,辅助网络结构图是我根据论文原理自己补充画的,如有错误,欢迎指正。 下面从3.1到3.5分别介绍STAR主网络结构、主网络中的PN原理、主网络中的星型拓扑全连接网络(star topology FCN)、辅助网络结构、主网络与辅助网络的结合。其中,星型拓扑全连接网络(star topology FCN)、PN(partitioned normalization)和辅助网络是STAR的三大核心亮点。 上图中,将主网络的整体结构分为6层,对应6个编号,下面从1到6对结构图中每层的处理逐一梳理。 在训练阶段,首先采样一个业务场景标识 其中, 通过共享Embedding层(Shared Embedding Layer)将上述输入的特征转化为低维向量。STAR模型让所有业务场景的embedding层参数共享,即不同业务场景中同一个ID特征对应的embedding是相同的。跨业务场景共享embedding层可以大大降低计算和内存成本。 (3)Pooling & Concatenation层 将上述输出的低维embedding进行pooling和拼接,得到 (4)PN(partitioned normalization)层 这上述 (5)星型拓扑全连接网络(star topology FCN) 星型拓扑全连接网络由两部分组成,一部分是所有业务场景共享的全连接网络(Centered),另一部分是该业务场景独有的全连接网络(Domain-M),所以,每个业务场景最后的模型就是由这两部分结合而成。可以看出,这部分的网络结构就是常见的全连接网络,创新点就是如何基于多场景建模的问题将这两部分结合,具体细节会在3.3中说明。 星型拓扑全连接网络的输出会和下文中提到的辅助网络的输出进行相加,从而得到最终的预估结果。辅助网络的结构比星型拓扑FCN简单,目的是为了用直接且简单的方法让模型捕捉到业务场景之间的差异。辅助网络的细节会在3.4中详细介绍。 这部分重点介绍主网络结构中PN层的处理,即Partitioned Normalization。PN是STAR对多场景建模问题基于BN做的优化,这部分我们刨根问底:(1)BN(Batch Normalization)的作用及原理是什么?(2)STAR中为什么不直接用BN。(3)PN的原理和使用细节。 (1)BN(Batch Normalization)的作用及原理 深度神经网络的训练是非常复杂的,因为在训练过程中,隐层网络的输入分布会随着前一层的参数变化而变化,这种现象,我们称之为Internal Covariate Shift 。一方面,稳定的分布可以使网络中的参数不用过于频繁的调整更新来适应变化,可以加快训练。另一方面,深度网络隐层分布的变动,可能会使分布逐渐往非线性函数取值区间的上下限偏移,例如对于非线性函数是sigmoid,那么会导致反向传播的梯度消失问题,从而使得训练变慢。Internal Covariate Shift 问题的解决办法就是使用BN(Batch Normalization),BN操作层位于 我们将上文STAR结构图中第3层(Pooling & Concatenation层)输出的中间表征记作 其中, BN的预测与训练稍有区别,预测和训练时BN的公式是一样,只不过 BN假设所有的样本都是i.i.d (独立同分布假设),在这种假设下,训练数据和测试数据是满足相同分布的,所以,BN在预测时可以使用所有训练样本共享的统计量。 BN假设所有的样本都是i.i.d(独立同分布假设),但是在多场景建模问题中,不同场景的分布是不同的,不同业务场景的样本有不同标准化的均值和方差,样本只会假设在其所在的业务场景中是独立同分布的。假设在预测阶段,使用BN的方法,通过移动平均追踪全局样本统计得到均值和方差,这个均值和方差相比于每个业务场景真实的均值和方差是有偏的,这种方法无法对不同业务场景的差异性进行有效地学习。 为了更精确地学习每个业务场景之间的差异,STAR提出了PN(partitioned normalization)方法。 (3)PN(partitioned normalization)的原理 PN是基于各业务场景来统计标准化的均值、方差及相关参数。 在训练阶段 ,假设当前的mini-batch是从第 其中, 在预测阶段 ,除了优化缩放系数和偏差之外,PN通过移动平均方法追踪统计得到各业务场景自己的均值 从公式可以看出,PN使用基于该业务场景的均值 这部分重点介绍主网络结构中的星型拓扑全连接网络(star topology FCN)。 PN层标准化后的向量 星型拓扑全连接网络包含共享的FCN和各业务场景特有的FCN,因此FCN网络结构的总个数为M+1,业务场景 两个FCN的结合使用的是element-wise product,element-wise product的操作是将两个矩阵对应位置的元素相乘,STAR中将操作符号用 对于共享的FCN,我们定义 其中 记 在全连接网络的每一层都会将共享参数和该场景特有的参数通过element-wise product进行结合。 通过上述结合方式,共享参数会通过所有场景的所有样本进行更新,而某场景特有的参数只会通过该业务场景的样本进行更新,共享的FCN学习所有业务场景的共性,不同场景特有的FCN学习该业务场景特点,这种方法既可以实现场景间的知识迁移,也可以针对场景间的差异进行更精确的CTR预估。 在工业界的推荐模型中,大部分的参数来自于embedding层,STAR方法增加的M个FCN的参数量相对于整体是微不足道的。总体来说,使用STAR模型为多个业务场景进行serving,只增加了很少的计算和内存成本,但带来了更好的效果。 在多场景CTR预估中,用来刻画场景信息的特征是非常重要的,它有助于模型学习不同场景的差异。STAR中使用辅助网络,并以刻画场景信息的特征作为输入,从而学习到其语义embedding从而捕捉到不同业务场景的差异。辅助网络的结构图如下: 上图中,将辅助网络的整体结构分为5层,对应5个编号,下面从1到5对结构图中每层的处理逐一梳理。 刻画场景的特征包含场景标识特征和其它场景特有的特征,辅助网络直接将场景标识作为ID特征,并和其它场景相关的特征作为辅助网络的输入。 将输入层输入的场景标识特征映射成为一个embedding向量,其它场景相关的特征做相同处理。 (3)Pooling & Concatenation层 将上述的场景标识embedding和其它场景相关的特征embedding进行拼接,然后输入到FCN中。 该层对上述拼接后的embedding向量计算前向传播得到一维输出,该层中只有两层全连接网络,所以说辅助网络的FCN比主网络的FCN要简单很多,这个简单的结构可以使场景相关的特征直接对最终的预估产生影响。 辅助网络的输出与主网络的输出进行相加,得到最终的 记星型拓扑全连接网络的一维输出是 记 在STAR多场景建模中,场景划分的根本依据是数据分布的差异,本质上,STAR 提供的是一种混合多分布下的差异化精准建模方案。在推荐业务中,除了不同推荐场景其分布有差异之外,在同一推荐场景中,有很多特征其不同类别对应的分布也有很大差异。例如性别,男性和女性无论是在淘宝app中,还是在抖音app中,他们都会有不同的行为偏好,这就会带来不同的数据分布。我们可以将具有混合多分布特点的用户或item侧特征作为Domain Partition,以此来进行样本划分,参考STAR进行多分布精细化建模。 本文介绍了解决多场景CTR预估问题的STAR模型,其中,星型拓扑全连接网络(star topology FCN)、PN(partitioned normalization)和辅助网络是三大核心亮点。STAR可以学习到不同业务场景的共性和差异,既可实现场景间的知识迁移,又可实现各场景差异化的精确预估。另外,若你想对混合多分布的数据进行更精细化的建模,STAR也可作为参考。 最后,对于CTR预估这个话题,我们后期会有一个比较丰富完整的总结,相信会让大家对CTR预估有更深入的理解,欢迎继续关注。 [1] One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction.
[2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
[3] https://zhuanlan.zhihu.com/p/437246384
往期推荐