




我之前写的几篇从 Excel 中 ETL 的文章
清洗 DataFrame 中的货币符号
df['Sales'] = df['Sales'].replace({'\$': '', ',': ''}, regex=True).astype(float)
这种方法使用 Pandas 的 Series.replace[1]。它看起来与字符串替换方法非常相似,但此代码实际上适当地处理了非字符串值。
自动补全缺失数据
主表、明细合并的时候,常见主表部分省略的情况,这个时候可以使用
df = df.fillna(method ='ffill')
或者
df = df.ffill()
使用 maya 简化日期处理
在 Python 中处理日期时间往往非常令人沮丧的事情,尤其是在处理不同系统上的不同语言环境时。这个库的存在是为了让简单的事情变得更容易,同时承认时间是一种幻觉(时区更是如此)。
日期时间应该通过为人类编写的 API 进行交互。
Maya 主要围绕解析来自网站的日期时间数据的难题和用例构建。
df1['date1'] = df1.Date.apply(lambda x: maya.parse(x).datetime())
抽取季节(Qualter)
df1['OrderPeriod'] = df1.date1.apply(lambda x: x.to_period(freq='Q').strftime('%Y-0%q'))
读取 xlsx 报错
import pandas as pd
df = pd.read_excel('aa.xlsx')
UserWarning: File contains an invalid specification for Sheet1. This will be removed
...
ValueError: Worksheet index 0 is invalid, 0 worksheets found
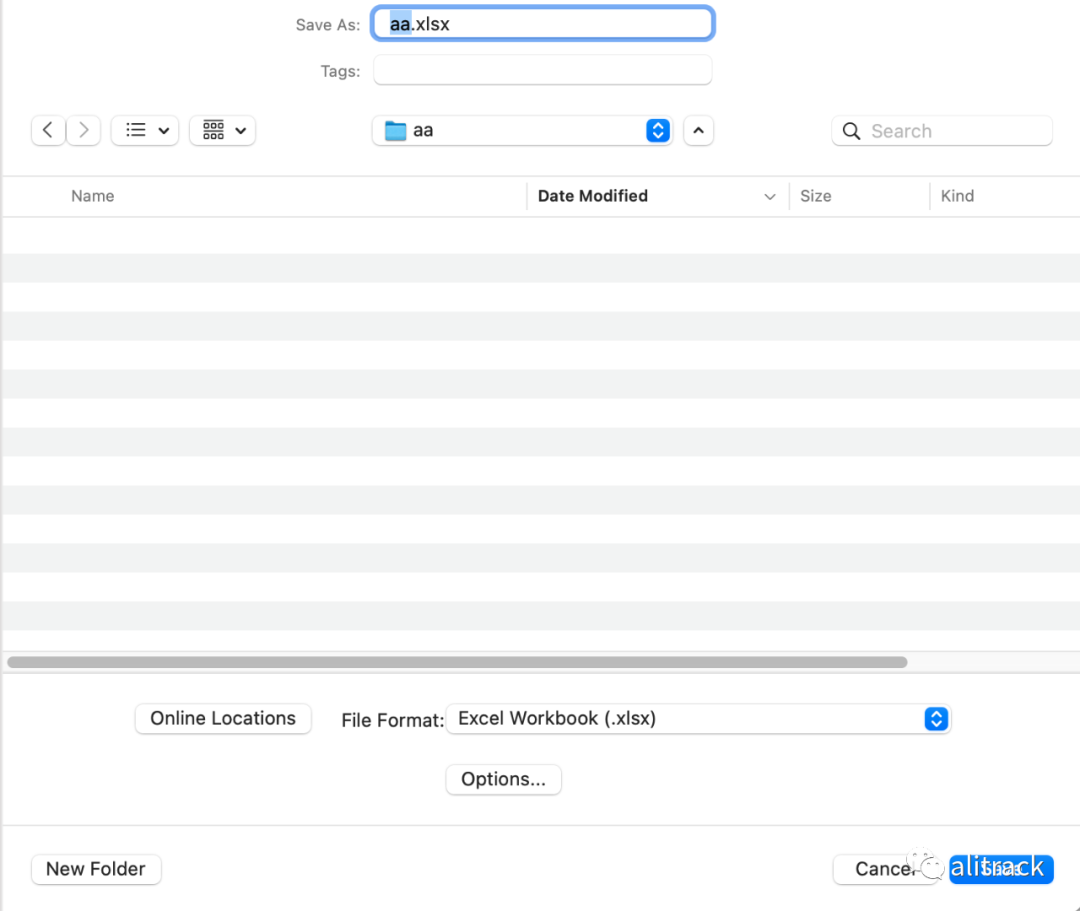
这种情况下多半是因为该 Excel 文档的存储格式为 Strict Open XML Spreadsheet (*.xlsx)
, 而 openpyxl
不能很好解析该格式(我使用的版本为 3.0.0),需要使用 Excel 打开并保存为一般的 Excel Workbook (*.xlsx)
即可

参考资料
Series.replace: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.replace.html
文章转载自alitrack,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
