




概述
知识图谱是描述客观世界存在的概念或实体以及它们之间的关系,本质上是一种基于图模型的关联网络知识表达,将实体抽象为顶点,将实体之间的关系抽象为边,通过结构化的形式对知识进行建模和描述,并将知识可视化。由于极强的表达能力和可解释性,当前已大量应用在搜索引擎、故障诊断、辅助检修、智能问答、推荐等多个领域。(详细了解知识图谱请参考本公众号之前的科普文章:https://mp.weixin.qq.com/s/fVAvgJxKhfTcIrMi-nbVEA)。
图数据库是知识图谱的底层存储计算引擎,是一种以图结构进行存储和查询的数据库。图数据库的关键概念是点(代表实体)和边(代表关系),通过边将顶点连接在一起,从而进行快速的图检索操作。相对于关系数据库来说,图数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询,而在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。
根据存储方式的不同可以将图数据库分为两类:
原生图数据库:数据存储模式为存储和管理图而设计,为图进行过优化,如Neo4j、Nebula Graph等。
非原生图数据库:将图数据序列化,采用关系型数据库、面向对象数据库、或是其他通用数据存储,如JanusGraph、HugeGraph等。
原生图数据库无论从功能上还是性能上都明显优于非原生图数据库,是我们做图数据存储计算技术实施的首选,下面我们针对目前常用的图数据库进行分析介绍。
Neo4j
Neo4j是一个嵌入式的、基于磁盘的、具备完全事务特性、由Java语言编写的面向图的数据库,它将结构化数据存储在图上而不是表中,重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图的数据量没有任何关系。结合我们的使用经验总结来看Neo4j的特点主要为:
较早发布的图数据库,功能完善稳定,易用(Cypher支持最完善);
基于JVM运行,跨平台支持友好,易于满足国产化要求;
社区版仅支持单节点,在千万节点上亿边的数据规模下有较好的表现,在数据规模较大时可通过部署多个Neo4jServer做数据拆分,但限制为一个图的数据规模要在单个节点可承受的数据范围(大概单图数据规模控制在千万顶点上亿边)内。
HugeGraph
HugeGraph是百度安全事业部在解决所面对的反欺诈、威胁情报、黑产打击等业务的图数据存储和建模分析需求的基础上逐步扩展衍生出的图数据库。实现了ApacheTinkerPop3框架及完全兼容Gremlin查询语言, 具备完善的工具链组件,助力用户轻松构建基于图数据库之上的应用和产品。HugeGraph支持百亿以上的顶点和边快速导入,并提供毫秒级的关联关系查询能力(OLTP),并可与Hadoop、Spark等大数据平台集成以进行离线分析(OLAP)。它的典型应用场景包括深度关系探索、关联分析、路径搜索、特征抽取、数据聚类、社区检测、 知识图谱等,适用业务领域有如网络安全、电信诈骗、金融风控、广告推荐、社交网络和智能机器人等。
HugeGraph的整体架构如下图所示:
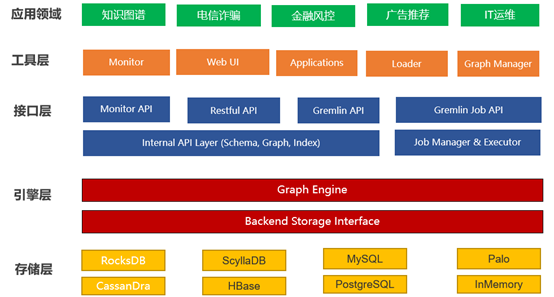
与社区版Neo4j对比,主要有以下不同:
在千万顶点上亿边的数据规模下Neo4j由于针对图做了专门的存储和计算优化性能会好于HugeGraph。
可支持较大的数据规模,HugeGraph存储系统支持RocksDB、Cassandra、ScyllaDB、HBase等分布式存储,可通过扩展集群规模来支撑更大规模的数据。
Neo4j使用cypher作为图查询语言, 而HugeGraph基于Apache TinkerPop3框架实现,支持Gremlin图查询语言。
值得注意的是开源版的HugeGraph 和企业版的差距较大,例如图更新速度企业版可达到10w/s,而社区版为2k/s。企业版支持高可用、Spark GraphX框架等。
NebulaGraph
NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库,它采用 shared-nothing 架构,支持在不停止数据库服务的情况下扩缩容,能够承载数千亿个点和数万亿条边的超大规模数据集。架构图如下所示:
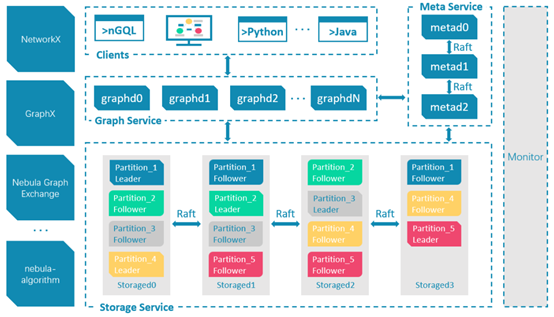
Nebula Graph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
Meta 服务:在 NebulaGraph 架构中,Meta 服务是由nebula-metad 进程提供的,负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。
Nebula Graph 采用计算存储分离架构。Graph 服务负责处理计算请求,Storage 服务负责存储数据。它们由不同的进程提供,Graph 服务是由 nebula-graphd 进程提供,Storage 服务是由 nebula-storaged 进程提供。
Graph 服务:Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤。查询请求发送到 Graph 服务后,会由如下模块依次处理:
Parser:词法语法解析模块。
Validator:语义校验模块。
Planner:执行计划与优化器模块。
Executor:执行引擎模块。
Storage 服务:Nebula Graph 使用 RocksDB 作为本地存储引擎,实现了自己的 KVStore。Nebula Graph 将点和边的信息存储为 key,同时将点和边的属性信息存储在 value 中,以便更高效地使用属性过滤。为应对节点数量高达百亿到千亿,边数量高达万亿的超大规模图谱,Nebula Graph 采用边分割的方式将图元素切割,并存储在不同逻辑分片(Partition)上。分片策略采用静态 Hash 的方式,即对点 VID 进行取模操作,同一个点的所有 Tag、出边和入边信息都会存储到同一个分片,这种方式极大地提升了查询效率。
需要注意的是Nebula Graph的Storage服务是分布式的,而Graph服务是单点的,在对大规模数据进行计算时可配合Spark GraphX或Plato(需企业版Nebula Graph)来实现分布式计算。
性能测试
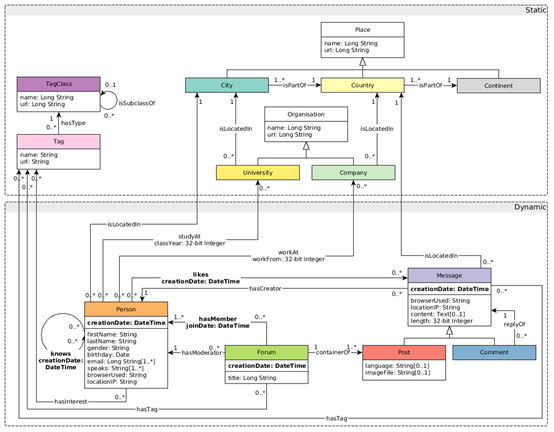
结合我们当前对大规模实体和边的存储计算需求,初步确定使用Nebula Graph做为图数据库,对此我们也进一步对Nebula Graph (V2.5.0版本)进行了多场景的性能测试。测试采用的是LDBC-SNB标准数据进行的,LDBC即Linked Data Benchmark Council(关联数据基准委员会)是图和RDF数据管理的基准指南制定者,SNB即SocialNetwork Benchmark(社交网路基准)是关联数据基准委员会(LDBC)开发的软件基准(Benchmark)之一,LDBC-SNB对图存储计算引擎提供了一个公平,诚实的比较评判机制。测试使用的数据集中涉及的实体和关系描述如下图所示:
我们分别采用了100G、300G规模的社交数据对NebulaGraph的单机和集群进行了测试,测试结果统计如下表所示:
数据 | 操作 | Nebula Graph(集群) | Nebula Graph(单机) |
大小:100G 节点:2.8亿+ 边数:18亿+ | 数据导入 | 3385.80s | 49915.06s |
一度关系 | 0.006079s | 0.074553s | |
二度关系 | 0.021242s | 1.541751s | |
三度关系 | 0.592882s | 43.595190s | |
大小:300G 节点:8亿+ 边数:52亿+ | 数据导入 | 12559.13s | 158855.03s |
一度关系 | 0.007558s | 0.19777s | |
二度关系 | 0.033336s | 0.582645s | |
三度关系 | 2.124033s | 2.136218s | |
测试环境配置(共3台机器) | CPU:2*E5-2650V4-12Core; 内存:8*32GB; 硬盘:2*400GB SATA SSD,3*1.2TB SAS) | CPU:2*E5-2680 v2-10Cores; 内存:8*16GB内存 硬盘:4.5T HDD |
经过对数据导入、多度关系查询等场景的测试,Nebula Graph基本满足我们的性能需求。也证实了Nebula Graph可通过集群扩容实现接近线性的性能提升。
选型总结:在数据规模较小的情况下(不超过千万顶点上亿边)建议选择Neo4j社区版,其功能最完善、性能也比较稳定。数据规模较大的情况下选择NebulaGraph,它采用shared-nothing 架构,可通过扩容存储节点来满足多达千亿顶点和万亿边的数据规模,计算层可通过集成SparkGraphx来实现分布式查询计算能力。
最后,按惯例广告一下
九识-领域知识图谱构建管理平台 帮助企业快速构建和管理领域知识图谱,实现从知识建模、知识抽取、知识推理到图谱分析的全流程工具化支持,助力企业领域知识沉淀,实现认知智能为基础的企业智能知识库、智能客服、智能运维等。
