




1. 平台概述
知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
当下,常规大数据分析会采用基于知识驱动的指标管理平台和基于数据驱动的人工智能两种分析方法,这两种方法原理不同,各有利弊,能够相互交叉验证,但很难有效结合起来,如果说采用机器学习和深度学习的人工智能是统计学和模式识别在海量历史数据上的深化和优化,那么知识图谱的图数据挖掘相关的分析方法则是试图从广度、关联性和网络结构性上去探寻群体性知识和构建知识结构,本质上也是检索、识别和认知的自动化。知识图谱可以成为两者逐步融合的桥梁,一方面通过将业务知识沉淀到知识图谱平台中,一方面将精准识别的判识结果数据沉淀到知识图谱中,通过关联搜索、规则推理等能力逐步实现对大数据判识分析的自学习能力。
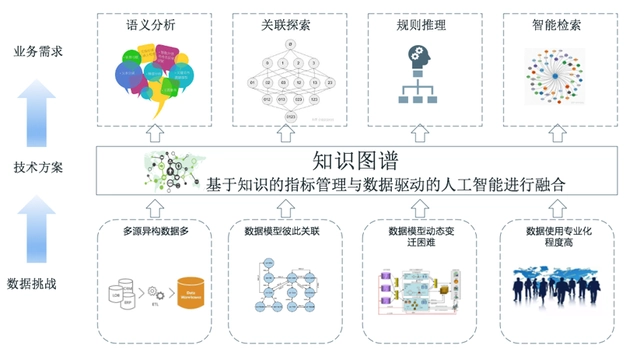
2. 适用场景
2.1. 企业知识图谱
基于图数据库构建企业知识库,将业务应用系统数据、非机构化文档数据和外部行业相关数据通过企业对象模型进行关联,实现图关联搜索和行业智能问答。
2.2. 欺诈检测
通过深度关联分析实时的检测欺诈模式,从而构建反欺诈应用。例如分析购买和转账关系是否有环,判断是否刷单作弊或恶意套现
2.3. 公共安全分析
构建公共安全领域知识图谱,挖掘人物、事件、地点及其关联数据,利用专家经验和机器学习技术,支撑公安机关开展嫌犯追踪、案件分析和重大事件预警等工作。
2.4. 智能运维
智能运维平台将网络设备和服务关联等信息存储在图数据库中,可以通过图查询和图计算来规划路由、诊断故障和收敛报警等。
3. 平台功能
3.1. 知识图谱功能组成
目前知识图谱技术已经被广泛被用在金融反欺诈、设备健康管理、在灾害风险预测分析、基础设施监控和智慧医疗等领域。在这个过程中,我们需要一个强大的图展现工具、图数据库和图计算引擎,解决数据关联分析,挖掘问题。也需要相应的图算法去解决图的构建,分析问题。
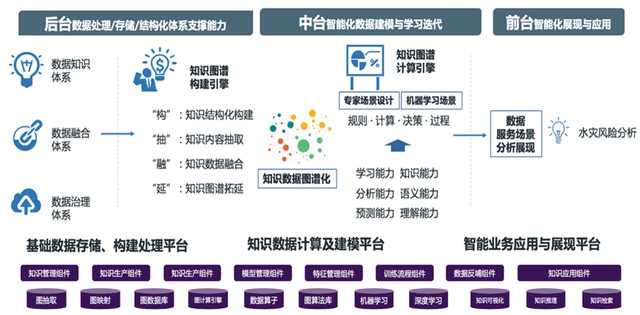
3.2. 知识图谱构建过程
知识图谱主要有自顶向下(top-down)与自底向上(bottom-up)两种构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库,自底向上指的是从一些开放链接数据中提取出实体,选择其中置信度较高的加入到知识库,再构顶层的本体模式。目前,大多数知识图谱都采用自底向上的方式进行构建。
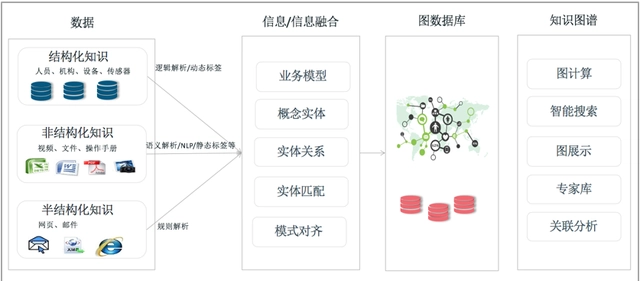
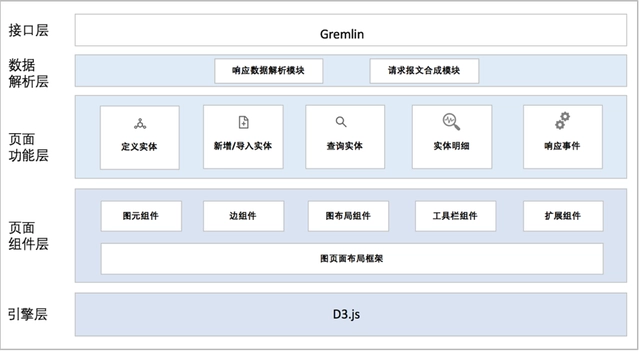
3.3. 知识图谱技术架构
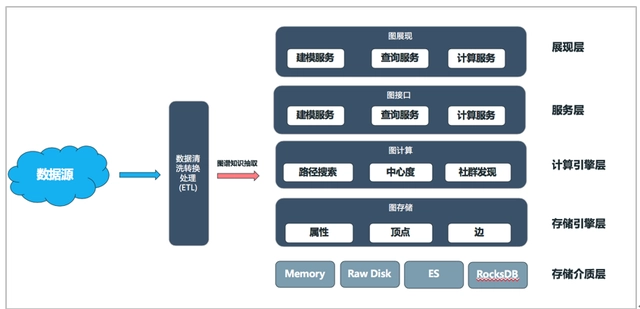
3.4. 图展现
3.4.1. 图展现架构
知识图谱平台具体功能包括:新增图数据,查询图数据,操作图数据,图布局展示等几个功能。涵盖了添加图数据、查询图数据、操作图数据和灵活丰富的布局设置功能,涵盖了图数据完整的操作过程,并且可以极大的提高用户对图数据分析操作体验。
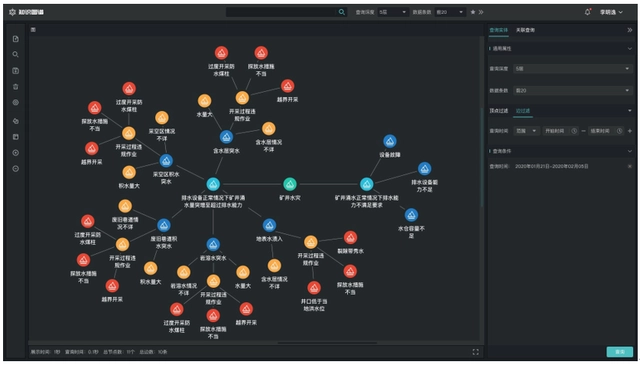
3.4.2. 新增图数据
o 增量数据添加:会根据默认力导图布局,动态完成增量数据添加,达到节点扩散,关系发现等效果。
o 支持文件上传、数据源导入和REST接口数据导入等多种方式。
o 全量数据渲染:支持全量数据渲染,满足保存,导入,导出等需求。
3.4.3. 查询图数据
图数据查询主要在右侧完成,通过图元的属性动态生成业务字段过滤项,根据属性类型动态判断筛选方式,支持多过滤条件组合查询,快速检索所需要的数据。
3.4.4. 操作图数据
数据分析过程是一个动态交互的过程,对于图分析也不例外。因此我们需要一些分析组件帮助我们辅助分析,这里知识图谱工具内置了两款组件:Toobar通用工具栏(左侧)和图元上的事件设置,目前事件设置分为左键单击和右键菜单两种,当单击左键时显示图元详细属性信息,当右键单击是显示右键菜单项,右键菜单项可根据图元类型动态定义,此时可以与多维分析平台或其他外部平台进行链接,通过参数传递灵活进行更加深入的分析。
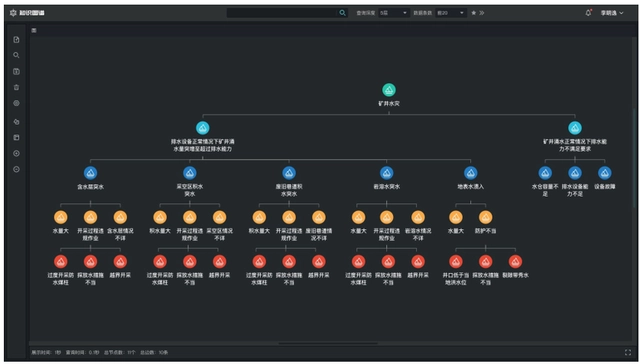
3.4.5. 图布局展示
内置丰富的布局,支持布局切换,满足不同场景下的布局需求。布局样式可根据业务需要动态扩展。支持力导图、横向布局、纵向布局等多种布局展示方式,如下图为纵向布局展示方式。
3.5. 图数据库
图数据库实现了 Apache TinkerPop3 框架及完全兼容 Gremlin 查询语言, 具备完善的工具链组件,助力用户轻松构建基于图数据库之上的应用和产品。HugeGraph 支持百亿以上的顶点和边快速导入,并提供毫秒级的关联关系查询能力(OLTP), 并可与 Hadoop、Spark 等大数据平台集成以进行离线分析(OLAP)。
具备如下特点:
· 支持从本地文件、HDFS 文件、MySQL 数据库等多种数据源批量导入数据,支持TXT、CSV、JSON多种文件格式导入
· 基于 Apache TinkerPop3 框架实现,支持 Gremlin 图查询语言
· 具备独立的 Schema 元数据信息,拥有强大的图建模能力,支持属性图,顶点和边均可添加属性,支持丰富的属性类型
· 可以对边和顶点的属性建立索引,支持精确查询、范围查询、全文检索
· 存储系统采用插件方式,支持 RocksDB、Cassandra、ScyllaDB、HBase、MySQL、PostgreSQL、Palo 以及 InMemory 等
· 与 Hadoop、Spark GraphX 等大数据系统集成,支持 Bulk Load 操作
· 支持高可用 HA、数据多副本、备份恢复、监控等
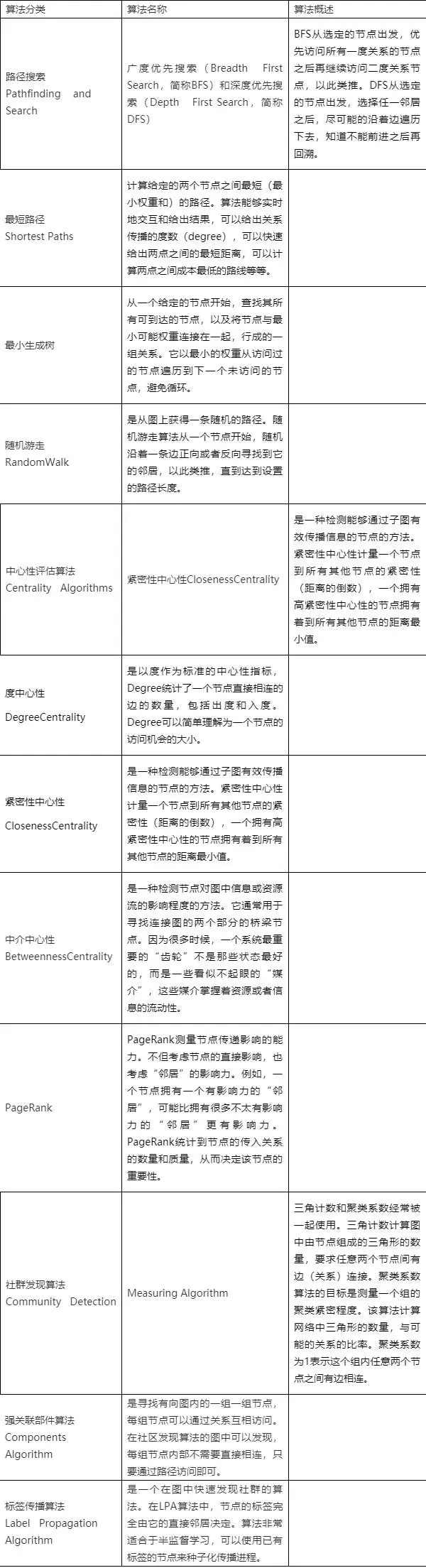
3.6 图算法
4. 平台特点
-
具备强大的数据导入工具,支持多种数据源多种格式数据导入,轻松完成百亿级数据快速导入
-
支持强大的图检索能力,支持数千用户并发的在线实时操作,毫秒级响应。
-
支持WEB在线方式构造图模型,支持对图元扩展菜单,与可视化工具进行无缝对接。
-
支持WEB在线方式可视化图查询,支持图搜索和图算法查询,支持多种页面布局方式。
-
支持与Spark GraphX和Python NetworkX无缝集成,内置三类10多种图算法,可与业务场景无缝融合。
-
图数据库支持 Gremlin 图查询语言与 Restful API,同时提供图检索常用接口,具备功能齐全的周边工具,轻松实现基于图的各种查询分析运算。
-
可支持分布式存储、数据多副本及横向扩容,内置多种后端存储引擎,也可插件式轻松扩展后端存储引擎。
文章来源:https://baijiahao.baidu.com/s?id=1746244772364805433&wfr=spider&for=pc
