




数据库系统中,为了加快处理速度,通过数据文件加载到内存,之后读取内存中的数据。MySQL的Innodb引擎缓存池,如Oracle的SGA(系统全局内存区)共享缓冲存储区一样,实现对数据库数据的管理和操作。MySQL的Innodb引擎缓存池可分为4个区域,支持不同的内存服务体系。
Buffer Pool
MySQL里保存内存数据的地方就叫缓冲池,缓冲池里包含实际数据区域和索引数据的区域。缓冲池允许直接从内存访问频繁使用的数据。在服务器上,通常物理内存的50%~80%的分配给缓冲池。
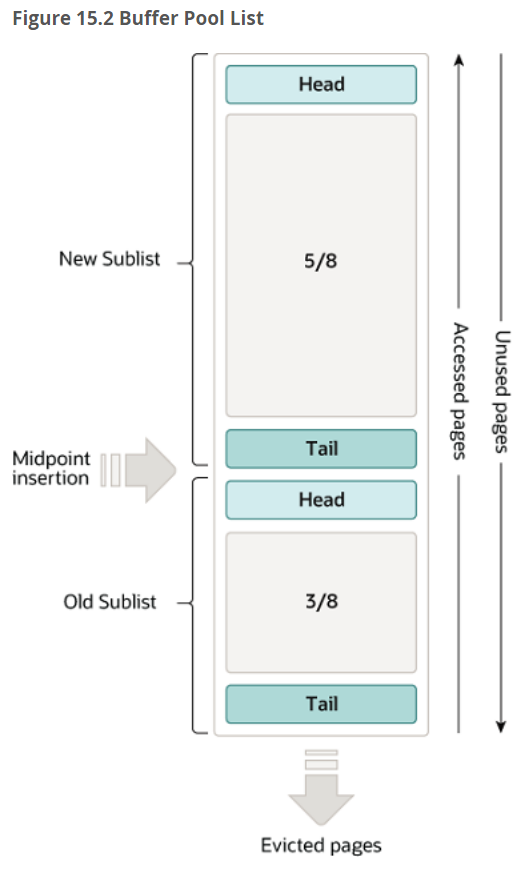
数据和索引加载到内存提供了更快的访问速度,但大量的数据能否全部加载到缓冲池中,那是不可能的。所以有限的内存空间,采用经典的LRU淘汰算法。
使用LRU算法将缓冲池作为列表进行管理:当需要空间向缓冲池添加新页时,将删除最近最少使用的页,并将新页添加到列表的中间。这种中点插入策略将列表分成两个子列表。
-
头部,最近被访问的新(“young”)页面的子列表;
-
尾部,是最近访问次数较少的旧页面的子列表;
-
将经常使用的页面保留在新的子列表中。旧的子列表包含较少使用的页面;无缓冲空间的可用的时,将被驱逐;
-
默认已3,5原则划分新旧数据区域;
-
对于监控缓冲池变化可以通过命令行可以查看。这些变化可以分析出缓冲池是否足够满足现有需求:
mysql> SHOW ENGINE INNODB STATUS\G;
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 0 #分配给INNODB的总内存大小
Dictionary memory allocated 480465 #分析给INNODB数据字典的内存大小
Buffer pool size 8192 #分配给INNODB的总buffer pool大小,单位page
Free buffers 6975 #数据库中innodb buffer pool中空闲page的数量
Database pages 1211 #数据库中innodb buffer pool中非空闲page的数量。
Old database pages 467 #Old子列表中的page数量
Modified db pages 12 #当前buffer pool中被修改的page数量
Pending reads 4 #数据由磁盘读到buffer pool,被挂起的次数
Pending writes: LRU 0, flush list 0, single page 0
#写入被挂起的次数
#LRU链表的page被淘汰出内存,要写入到磁盘
#check point操作期间page要被写入到磁盘
#单个page要被写入到磁盘
Pages made young 2, not young 0 #young:page由old列表移动到new列表的次数.
#not young:page由new列表移动表old列表的次数.
0.17 youngs/s, 0.00 non-youngs/s #youngs/s:平均每秒有多少个page由old移动到new
#non-youngs/s:平均每秒有多少个page由new移动到old
Pages read 1067, created 144, written 199
#从buffer pool中读,创建,写的page的总数
90.26 reads/s, 12.18 creates/s, 16.83 writes/s
#平均每秒从buffer pool中读,创建,写的page的数
Buffer pool hit rate 941 / 1000, young-making rate 0 / 1000 not 0 / 1000
#buffer pool的命中率,无限接近1。
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
#每秒read ahead的次数,每秒淘汰的page次数,随机read ahead的次数
LRU len: 1211, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
影响缓存池
从上述监控缓冲池变化就能看出那些会影响缓冲池指标。
1.缓冲池大小
- 理想情况下,将缓冲池的大小设置为实际的最大值,缓冲池越大,InnoDB就越像一个内存数据库,从磁盘读取一次数据,之后读取过程中从内存访问数据。通过3个重要参数,构成数据&索引区域。
| 参数 | 说明 |
|---|---|
| innodb_buffer_pool_size | 缓冲池的大小(以字节为单位),InnoDB缓存表和索引数据的内存区域。 |
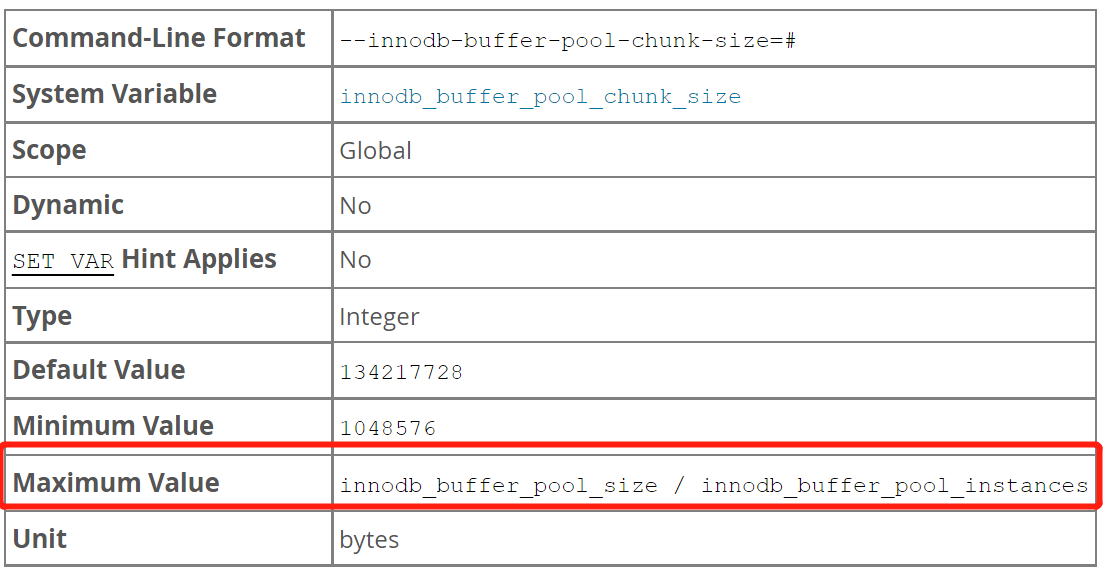
| innodb_buffer_pool_chunk_size | 缓冲池已块chunk单位进行控制。innodb_buffer_pool_size应该等于innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的倍数。 |
| innodb_buffer_pool_instances | 使用散列函数,缓冲池划分多个域,提高并发性,每个缓冲池管理自己的空闲列表、刷新列表、LRU等结构,并由自己的缓冲池互斥锁保护。单个分配必须大于1G 才生效。建议不要超过CPU核算 |
备注:单个instance分配域必须大于1G才生效。避免潜在的性能问题,块的数量(innodb_buffer_pool_size / innodb_buffer_pool_chunk_size)不应该超过1000。目前官方提供的innodb_buffer_pool_chunk_size没有最大值限制。可以通过这个算法灵活控制大小。
2.新旧页分配
缓冲池新旧配置基于协调LRU值和时间 进行替换规则:
| 参数 | 说明 |
|---|---|
| innodb_old_blocks_pct | 控制LRU列表中"old"块的百分比。innodb_old_blocks_pct的默认值是37,对应原来的固定比率3/8。 |
| innodb_old_blocks_time | 防止缓冲池被预读,新旧页不停切换,可以避免由于表或索引扫描而产生的类似问题。第一次访问一个页面后的时间窗口(毫秒),在此期间,该页面可以被访问而不被移动到LRU列表的前面。 |
备注:随着工作负载的变化,innodb_old_blocks_time参数的影响比innodb_old_blocks_pct参数更难预测,所以采取默认值即可。
3.预读设置
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)。区别在于,线性预读放到以extent为单位,而随机预读放到以extent中的page为单位。考验的是硬件的IO处理能力。

| 参数 | 说明 |
|---|---|
| innodb_read_ahead_threshold | 控制是否将下一个extent预读到buffer pool中,如果一个extent中的被顺序读取的page超过或者等于该参数变量时,Innodb将会异步的将下一个extent读取到buffer pool中。 |
| innodb_random_read_ahead | 随机预读方式则是表示当同一个extent中的一些page在buffer pool中发现时,Innodb会将该extent中的剩余page一并读到buffer pool中,由于随机预读方式给Innodb code带来了一些不必要的复杂性,同时在性能也存在不稳定性 |
备注:因为数据的大小和行为 很难预估,当然内存足够大,io能力强的话 完全可以都打开,所以采取默认值即可。
Change Buffer
Change Buffer是一种特殊的数据结构,当辅助索引页不在缓冲池中时,它将更改缓存到辅助索引页。缓冲的更改可能来自INSERT、UPDATE或DELETE等操作(DML),当其他读操作将页面加载到缓冲池中时,将合并这些更改。所以总结就是二级索引更新区。
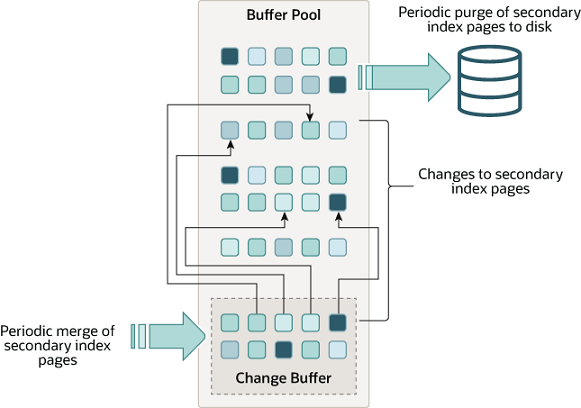
与聚集索引不同,辅助索引通常不是唯一的,并且对辅助索引的插入以相对随机的顺序发生。类似地,删除和更新可能会影响不在索引树中邻接位置的辅助索引页。当受影响的页面被其他操作读入缓冲池时,通过合并缓存的更改,可以避免大量的随机访问I/O。
| 参数 | 说明 |
|---|---|
| innodb_change_buffer_max_size | 允许配置更改缓冲区的最大大小,从buffer pool总大小的百分比,这部分内存也包含在innodb_buffer_pool_size里。 |
| innodb_change_buffering | InnoDB执行更改缓冲的程度。允许的操作none,inserts,deletes,changes,purges,all |
备注:随着工作负载的变化,innodb_old_blocks_time参数的影响比innodb_old_blocks_pct参数更难预测,所以采取默认值即可。
Change Buffer占据缓冲池总页的百分比:
mysql> SELECT (SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE
WHERE PAGE_TYPE LIKE 'IBUF%') AS change_buffer_pages,
(SELECT COUNT(*) FROM INFORMATION_SCHEMA.INNODB_BUFFER_PAGE) AS total_pages,
(SELECT ((change_buffer_pages/total_pages)*100))
AS change_buffer_page_percentage;
+---------------------+-------------+-------------------------------+
| change_buffer_pages | total_pages | change_buffer_page_percentage |
+---------------------+-------------+-------------------------------+
| 2 | 8192 | 0.0244 |
+---------------------+-------------+-------------------------------+
备注:如果二级索引包含降序索引列,或者如果主键包含降序索引列,则不支持更改缓冲
Adaptive Hash Index
自适应哈希索引使InnoDB在缓冲池内存的hash内存数据库,而不牺牲事务特性或可靠性。哈希索引通过支持对任何元素的直接查找,将索引值转换为一种指针,从而加快查询速度。InnoDB有一个监视索引搜索的机制。如果InnoDB注意到查询可以从建立哈希索引中获益,它就会自动这么做。
按照目前了解的自适应Hash索引InnoDB自创建条件如下:
- 索引中的页访问的模式是相同的,不包含主键;
- 索引命中的该页上的记录数要大于该页上总记录数的1/16;
- 索引中的某个页已经被访问了至少100次
满足上面的条件就会自动添加到自适应hash索引中。自适应哈希索引特性是分区的。每个索引都绑定到一个特定的分区,每个分区都由一个单独的锁存器保护。
mysql> SHOW ENGINE INNODB STATUS\G;
。。。
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 10, free list len 174, seg size 176, 8 merges
#size 10:已经合并记录页的数量
#free list:插入缓冲中空闲列表长度
#seg size: 176显示了当前insert buffer的长度,大小为176*16K/1024=2.75M。
#merges:合并插入的次数
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 2 buffer(s) #Hash table size 34679表中2 使用中
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 4 buffer(s)
Hash table size 34679, node heap has 114 buffer(s) #Hash table size 34679表中114 使用中
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
| 参数 | 说明 |
|---|---|
| innodb_adaptive_hash_index | InnoDB自适应哈希索引是否启用。 |
| innodb_adaptive_hash_index_parts | 分区自适应哈希索引搜索系统。每个索引都绑定到一个特定的分区,每个分区由一个单独的锁存器保护。默认设置为8。最大可设置为512。 |
备注:MySQL的Adaptive Hash Index默认打开,按照理解基本在只读场景下才能性能提高。因为自适应哈希本身维护锁机制,其他操作可能会导致锁等待,甚至导致MySQL hung或极端场景下的数据损坏。此外,AHI会消耗Buffer Pool的空间,虽然用索引构建,但索引字段不合理,这可能会影响整体性能。由于很难预先预测adaptive hash index功能是否适合特定系统和工作负载。所以IO负载高的场景下建议禁止。
Log Buffer
Log Buffer是存储要写入磁盘上redo文件的数据的内存区域。Log Buffer的内容定期会刷新到磁盘。保证操作日志楼盘,保证数据的一致性。通过日志缓冲区的批量处理机制,频繁磁盘I/O交互。
| 参数 | 说明 |
|---|---|
| innodb_log_buffer_size | InnoDB写入磁盘上日志文件的缓冲区大小(以字节为单位)。默认值是16MB。大的日志缓冲区使大型事务能够运行,而不需要在事务提交之前将日志写入磁盘。 |
| innodb_flush_log_at_trx_commit | 控制日志缓冲区的内容如何写入和刷新到磁盘。 |
| innodb_flush_log_at_timeout | 控制日志缓冲区的内容刷新频率。 |
备注:innodb_log_buffer_size的最大值可以达到4G的空间,可以支持到一次性4G的事务。但内存里寻址,也是很消耗性能的,同时占据Innodb整体缓存池的。所以MySQL里建议还是单个事务方式提交处理。
总结
通过MySQL Innodb内存结构的的理解,可以合理的设置内存参数,并且协助排查诸多这方面的问题。
