点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容
前几篇的面试真题收到很多粉丝的积极响应
这不,继字节、淘宝、腾讯后
本篇继续来一篇阿里系之
—— 『饿了么』
一如既往,真题可先自测模拟
再总结归纳,内化成自己的个性化题库
一、SQL题
二、机器学习与概率论
三、开放性问题
ps.文末送惊喜!有求职题库
▌面试真题1:
① 语法公式不同:
左连接:左连接的关键字是left join
右连接:右连接的关键字是right join
② 基础表不同
左连接:左连接的基础表为left join左侧数据表
右连接:右连接的基础表为right join右侧数据表
③ 结果集不同
左连接:左连接的结果集为left join左侧数据表中的数据,再加上left join左侧与右侧数据表之间匹配的数据。
右连接:右连接的结果集为rightjoin右侧数据表中的数据,再加上rightjoin左侧与右侧数据表之间匹配的数据。
where和having的区别
where语法
where是一个约束声明,使用where来约束来自数据库的数据
where是在结果返回之前起作用的
where中不能使用聚合函数
having语法
having是一个过滤声明;
在查询返回结果集以后,对查询结果进行的过滤操作;
在having中可以使用聚合函数。
执行顺序说明
where 早于 group by 早于 having
where子句在聚合前先筛选记录,也就是说作用在group by 子句和having子句前,而 having子句在聚合后对组记录进行筛选
Tips:

▌面试真题1:
异常值如何识别和处理?
★参考答案
▶ 异常值定义
是指样本中一些数值明显偏离其余数值的样本点,也称为离群值。
方法①:3σ原则
方法②:箱线图
方法①:删除,直接将含有异常值的记录删除,
优点:方法简单可行,
缺点:缺点是造成样本不足,统计模型不稳定。
方法②:视为缺失值,利用处理缺失值的方法来处理
优点:能够利用现有变量的信息,来填补异常值
缺点:需要根据缺失值的特性进行处理,工作量有所增加。
方法③:平均值修正
优点是能克服了丢失样本的缺陷
缺点是丢失了样本“特色”
方法④:盖帽法,整行替换数据框里99%以上和1%以下的点,将99%以上的点值=99%的点值;小于1%的点值=1%的点值
方法⑤:分箱法,分箱法通过考察数据的“近邻”来光滑有序数据的值,也就是将数据进行分段。
优点:异常值将分配到某箱中,模型和数据不再不受异常值影响。
缺点:数据缺乏连续性。
方法⑥:回归插补,通过构造y=f(x)进行回归学习变量之间的变化关系。得到函数f后,再根据x来更新y的值,这样就能去除其中的随机噪声,这就是回归去噪的原理 。
方法⑦:多重插补,重插补的处理有两个要点:先删除Y变量的缺失值然后插补
方法⑧:不处理:根据该异常值的性质特点,使用更加稳健模型来修饰,然后直接在该数据集上进行数据挖掘。
K-means 算法的原理和优缺点
原理请参考 ☞ 字节数据分析岗面试真题
k-means优点:
原理简单,实现方便,收敛速度快:
聚类效果较优;
模型的可解释性较强;
调参只需要簇数k;
k-means缺点:
k的选取不好把握:
对于不是凸的数据集比较难以收敛
如果数据的类型不平衡,比如数据量严重失衡或者类别的方差不同,则聚类效果不佳
采用的是迭代的方法,只能得到局部最优解:
对于噪音和异常点比较敏感。
▌面试真题
请设计一个估算配送时间的模型
★参考思路
首先对估算配送时间拆解为三部分:
商家出餐速度
骑手配送速度
用户交付速度
针对每一部分单独建立回归模型,模型可选择
Xboost
GBDT
深度学习算法
等等
下面罗列可能影响每个模型的因素
① 商家出餐速度
餐品的品类
时间段
天气
是否节假日
是否有促销活动
商家销量
出餐速度
餐品数量及重量
② 配送速度
时间段
配送人力
配送产品数量
天气
是否节假日
配送经过地段
③ 用户交付速度
楼层
时间段
是否有电梯
是否节假日
用户历史交付速度
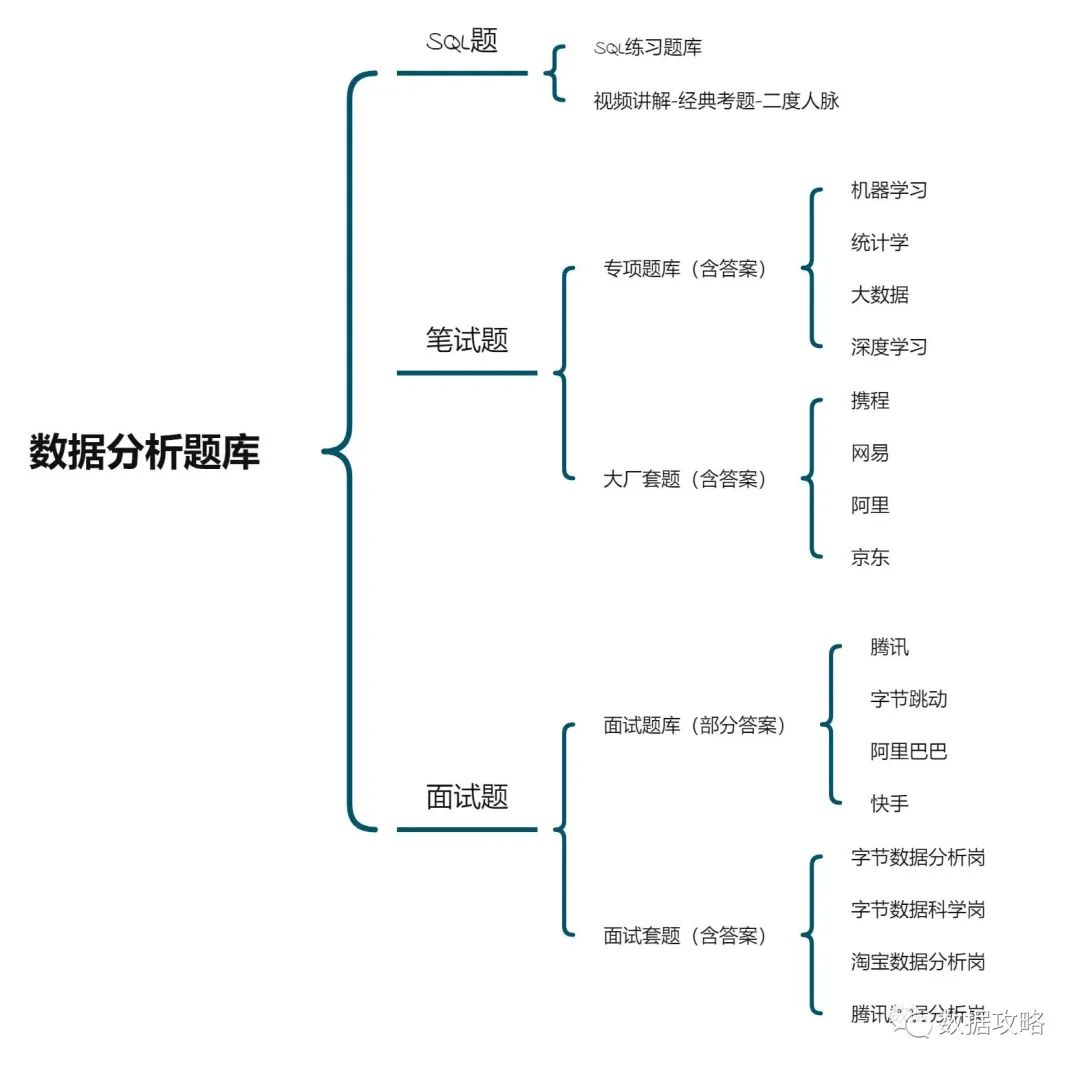
资料库部分资料列举:

 往期好文推荐
往期好文推荐 更多 『求职干货』 & 『日常学习』 系列好文,等你发现~

Ps. 微信推文改了规则
看完记得设置为 “ 星标 ”
不然我会消失的