点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容
应加我私人号的你们强烈要求和反馈
希望多来点儿 “大厂面试真题解析” 系列
这不 继字节、淘宝、腾讯后
本篇,讲一讲业界薪资天花板之
—— 『拼多多』
一如既往,为大家整理了拼多多面试真题
可以自测模拟,直观感受下难易程度
一、SQL题
二、机器学习与概率论
三、开放性问题
ps.文末送惊喜!有求职题库
现有一张用户成交订单表
表名:user_order_summary,字段如下:
uid 用户ID,主键
order_cnt 成交订单数
▌面试真题1:
首先先了解一下众数的概念
众数(Mode)是指在统计分布上具有明显集中趋势点的数值,代表数据的一般水平。也是一组数据中出现次数最多的数值,有时众数在一组数中有好几个。
情况①:一组数据中,出现次数最多的数就叫这组数据的众数。
举例:1,2,3,3,4的众数是3。
举例:1,2,2,3,3,4的众数是2和3。
举例:1,2,3,4,5没有众数
★参考答案
SELECT order_cntFROM(SELECT order_cnt,user_cnt,rank()over(order by user_cnt desc) AS rank_idFROM(SELECT order_cnt,COUNT(1) AS user_cntFROM user_order_summaryGROUP BY order_cnt)a)aWHERE user_cnt > 1 -- 剔除情况3AND rank_id = 1
请使用mysql计算出成交订单数的四分位数
首先先了解一下四分数的原理及计算逻辑
四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。它是一组数据排序后处于25%,中位数和75%位置上的值。四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据
四分数的位置:
Q1的位置= (n+1) × 0.25
Q2的位置= (n+1) × 0.50
Q3的位置= (n+1) × 0.75
n表示项数,也就是计算样本量
由小到大排列: 6, 7, 15, 36, 39, 40, 41, 42, 43, 47, 49
总共11项
Q1的位置=(11+1)×0.25=3,所以Q1=13
Q2的位置=(11+1)×0.50=6,所以Q2=40
Q3的位置=(11+1)×0.75=9,所以Q2=43
▼ 情况②
数据总量: 7, 15, 36, 39, 40, 41
一共6项
Q1的位置=(6+1)×0.25=1.75,在第1和第2个之间
Q2的位置=(6+1)×0.50=3.50,在第3和第4个之间
Q3的位置=(6+1)×0.75=5.25,在第5和第6个之间
▼ 当Qi的位置并非整数,如何计算呢?
第一步:将数据从小到大排序,计为数组a,a[i]表示第i个位置的数值 第二步:确认四分位数的位置P,将P的整数部分计为c,小数部分记为d,比如Q1的位置为1.75,那么c=1,d=0.75
第三步:计算位置P对应的值,a[p] = a[c]+(a[c+1]-a[c])*d,比如Q1的位置1.75计算结果为a[1.75]=a[1]+(a[1+1]-a[1])*0.75=7+(15-7)*0.75=13
以此类推,可以计算得到
a[Q1]=a[1.75]=a[1]+(a[2]-a[1])*0.75=13
a[Q2]=a[3.5]=a[3]+(a[4]-a[3])*0.5=37.5
a[Q3]=a[5.25]=a[5]+(a[6]-a[5])*0.25=40.25
SELECT int_q1_value+(int_q1_next_value-int_q1_value)*decimal_q1_place AS q1,int_q2_value+(int_q2_next_value-int_q2_value)*decimal_q2_place AS q2,int_q3_value+(int_q3_next_value-int_q3_value)*decimal_q3_place AS q3FROM(SELECT-- Q1的相关数据MAX(if(int_q1_place = b.rn,order_cnt,NULL)) AS int_q1_value,MAX(if(int_q1_place+1 = b.rn,order_cnt,NULL)) AS int_q1_next_value,MAX(decimal_q1_place) AS decimal_q1_place-- Q2的相关数据,MAX(if(int_q2_place = b.rn,order_cnt,NULL)) AS int_q2_value,MAX(if(int_q2_place+1 = b.rn,order_cnt,NULL)) AS int_q2_next_value,MAX(decimal_q2_place) AS decimal_q2_place-- Q3的相关数据,MAX(if(int_q3_place = b.rn,order_cnt,NULL)) AS int_q3_value,MAX(if(int_q3_place+1 = b.rn,order_cnt,NULL)) AS int_q3_next_value,MAX(decimal_q3_place) AS decimal_q3_placeFROM(-- 位置取整数和小数部分SELECT FLOOR(q1_place) AS int_q1_place,q1_place-floor(q1_place) AS decimal_q1_place,FLOOR(q2_place) AS int_q2_place,q2_place-floor(q2_place) AS decimal_q2_place,FLOOR(q3_place) AS int_q3_place,q3_place-floor(q3_place) AS decimal_q3_placeFROM(-- 位置SELECT MAX(rn) AS n -- 样本数,(MAX(rn)+1)*0.25 AS q1_place,(MAX(rn)+1)*0.50 AS q2_place,(MAX(rn)+1)*0.75 AS q3_placeFROM user_order_rn)a)aINNER JOIN user_order_rn bON 1 = 1 -- 笛卡尔乘积)a
▍Tips:
拼多多均会重点考察SQL题
且相比其他大厂,拼多多对SQL的要求较高
所以,请务必熟练熟练再熟练!
▌面试真题1:
模型过拟合怎么处理
模型过拟合主要可以从以下几个方面入手
获取更多数据,扩大数据量。
降低模型复杂度。
添加正则项。
改为集成学习。
请介绍一下SVM原理
SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。(间隔最大是它有别于感知机)
情况①:当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;
情况②:当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机;
情况③:当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机
这类问题碰到一些偏技术向面试官,会揪着细节不断发问,以来考察你的基本功是否扎实,所以还需要对原理进行详细的理解和推导
下面补充两个SVM的衍生问题,供大家参考:
★参考答案
当训练数据线性可分时,存在无穷个分离超平面可以将两类数据正确分开。感知机利用误分类最小策略,求得分离超平面,不过此时的解有无穷多个。线性可分支持向量机利用间隔最大化求得最优分离超平面,这时,解是唯一的。另一方面,此时的分隔超平面所产生的分类结果是最鲁棒的,对未知实例的泛化能力最强。
▍问题②:为什么SVM要引入核函数?
★参考答案
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
▌面试真题1
假设拼多多近期GMV下滑严重,请问如何分析
★参考思路
问题确认:首先,需要确认该问题是否真实存在,即校验数据的准确性。例如:数据提取是否存在逻辑错误,上游表是否存在重复记录的问题?
确认有无外因,举例:
环境影响:是否存在外界因素,比如受疫情影响,快递公司无法正常配送。导致线上无法成交。
时间因素:是否存在季节性的波动,比如双十一大促属于用户成交高峰期,而非双十一大促成交相对较少。
竞品因素:比如竞品淘特/抖音等上线大型补贴活动,势必会对拼多多产生较大的冲击。
内因分析拆解,提供一种思路,具体大家可以拓展发挥举例:
货-商品维度拆解:例如可设计相关指标(如:贡献度)定位异常行业、店铺等
人-用户维度拆解:例如可根据用户的属性,比如地域,年龄,新老客,价值等级等维度进行拆分解析
场-场景维度拆解:例如可根据大盘常见场景有无做功能变动、策略迭代等进行拆解确认等等

▌面试真题2
怎么估算上海外卖员的数量
▶ 指标拆解
外卖员的数量 = 每天订单总数 每人每天可配送的订单数
每天订单总数 = 目标用户数 点单频度
目标用户数 = 上海市总人数*点外卖人数占比
每人每天可配送的订单数 = 每天工作时间 完成一个订单需要的时间
完成一个订单需要的时间 = 商家距离/骑手速度+排队等待时间+目的地距离/骑手速度 + 用户等待时间
上海市总人数:2500w
点外卖人数占比:假设为40%
骑手每天工作时间:10H
商家距离:假设为3KM
骑手速度:25KM/h
排队等待时间:0.25H
目的地距离:4KM
用户等待时间:0H
▶ 计算可得
每天的总订单数 = 200w
每人每天可配送的订单数 = 18.9单
外卖员的数量=10.5万人
Tips: 估算类问题重点考察解题思路。
以上就是拼多多面试真题解析参考
🔶 福利时间!!
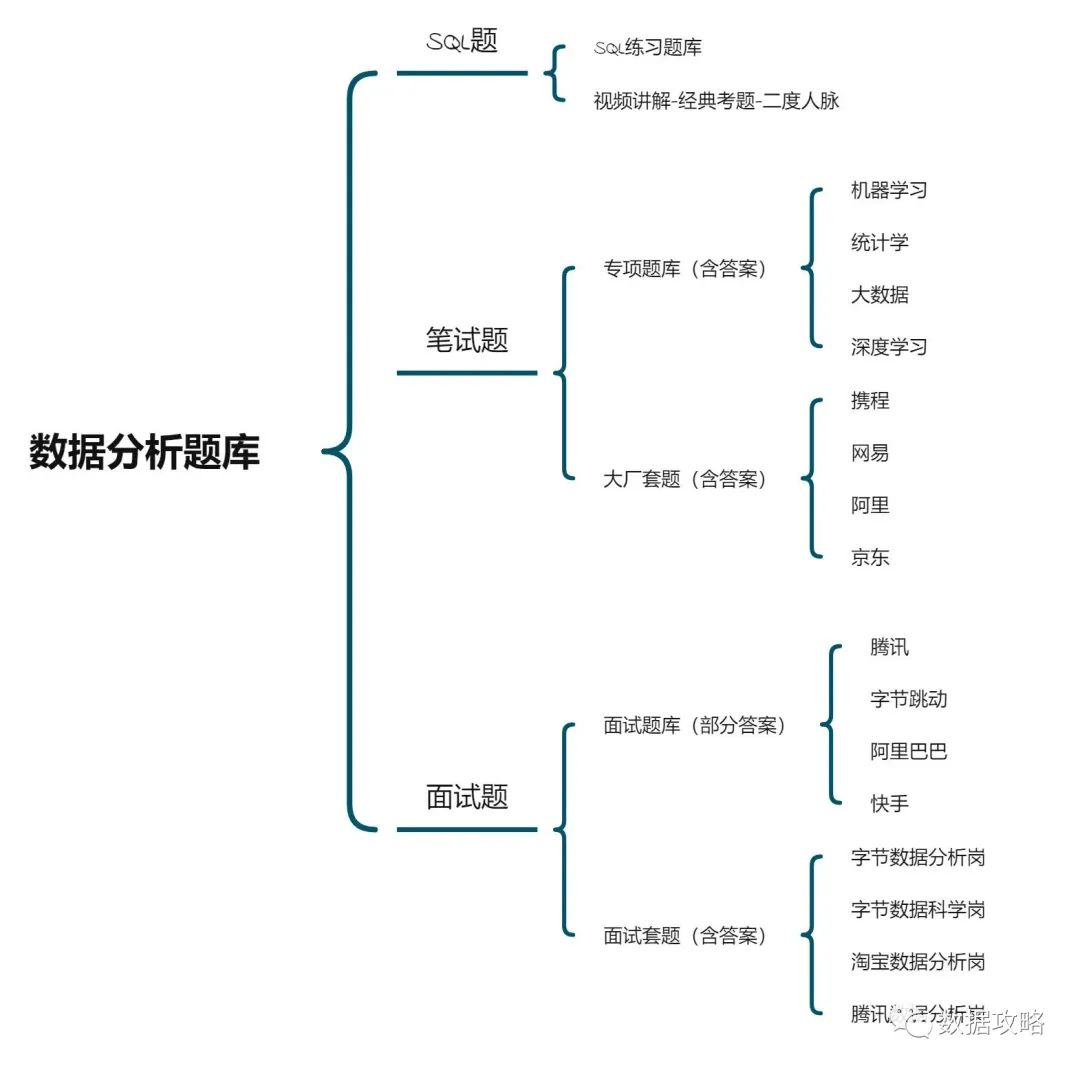
资料库部分资料列举:

 往期好文推荐
往期好文推荐 更多 『求职干货』 & 『日常学习』 系列好文,等你发现~

Ps. 微信推文改了规则
看完记得设置为 “ 星标 ”
不然我会消失的