




点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容
大家好,我是六哥~
针对AB实验部分,前期已讲解过
AB实验框架以及方案设计

在AB项目实战课程中,发现
不少同学对实验分流表示很难理解
因为没有真正理解透彻原理
所以很难灵活应对面试中分流相关的问题
所以本篇,结合大厂真实项目案例
采用case模拟计算的方法
强化大家对实验分流的理解
三、分流方法之Hash
四、Hash分流步骤
五、实验正交设计
一、背景介绍
1
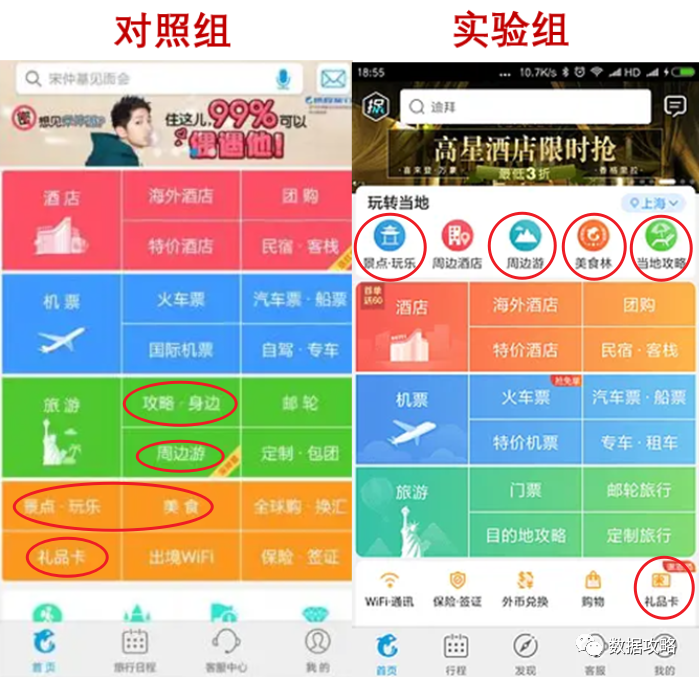
首页改版
携程旅行APP对首页排版进行了优化,主要改动点如下:
② "攻略.身边"改名为"当地攻略",并移至头部
③ "周边游"及"景点.玩乐"移至头部
④ "美食"修改为"美食林",并移至头部
⑤ "礼品卡"下移到定制旅行下面,业务形态上有所弱化
分组信息:
对照组:老版本,如下左图
实验组:新版本,如下右图
2
海外发券
海外部门为提高海外市场份额及用户渗透率,在海外预定页面通过弹窗给海外新用户(在平台从未预定过海外酒店的用户)发放80元新客立减券。
对照组:不弹窗,且无新客立减优惠券
实验组:弹窗,并发放新客立减优惠券
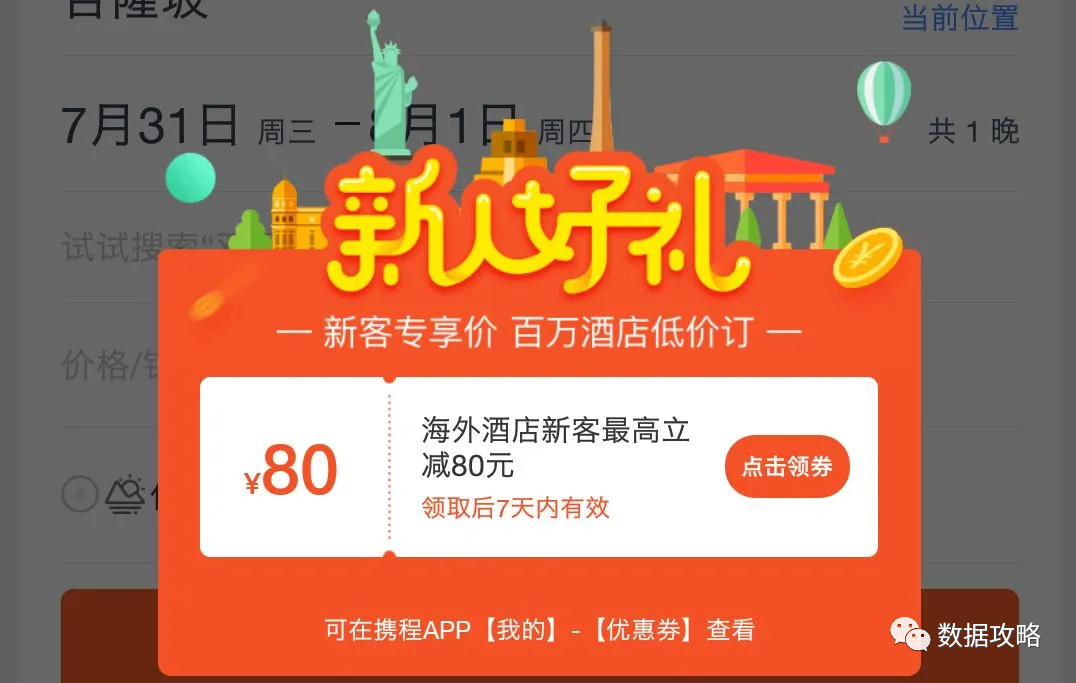
假设这两个实验同时进行,实验时间均为1/1~1/2,为期两天。
下面我们来讲讲:针对多个实验
如何设计实验来保证实验间的独立?
二、分流目标
首先需要对平台用户进行分流,验证实验效果。
为更好理解,我们以case方式来计算阐述:
1
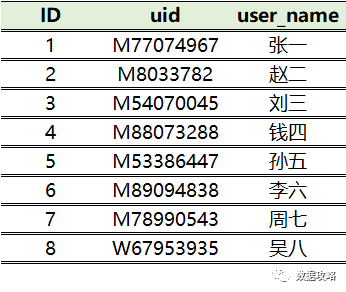
数据说明
假设平台总共有8个用户,每个用户在注册时会随机分配一个用户ID,样例如下(非真实数据):
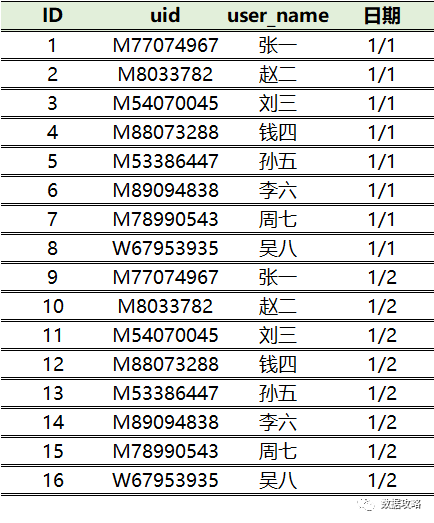
② 访问表
假设这8个用户在1/1~1/2均为活跃状态:
2
分流目标
① 用户比例:实验组和对照组用户为1:1
② 随机性:用户的分组结果应满足随机性
③ 连贯性:为保持用户体验的连贯性,实验期间用户分流结果需要一致。也就是不能出现用户一会是实验组,一会是对照组的情况。
三、分流方法之Hash
为了更好理解Hash分流原理和优点
先举几个常见的方法来看看有啥优劣性
1
分流方法①
先从我们熟悉的随机数进行演示,计算步骤如下:
② 当N大于0.5时,该次访问标记为实验组,否则为对照组
下面用Excel随机生成一个随机数,并对结果进行标记:
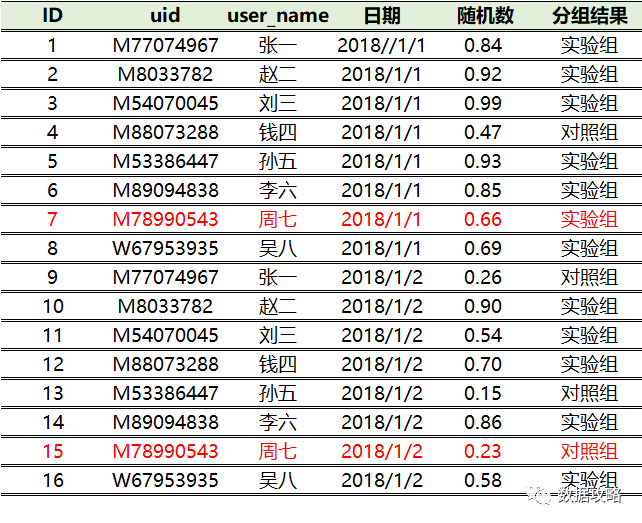
问题:以上随机数的方法,用户周七在1月1日为实验组用户,在1月2日变为了对照组用户,违背了连贯性原则。
2
分流方法②
② 获取N%2的余数M
③ 当M为0时设为实验组,否则为对照组
分组结果如下:
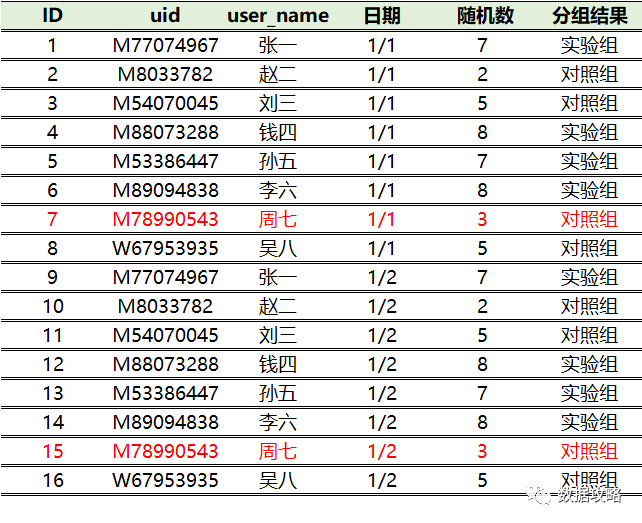
▼ 优点:用户ID在用户注册当日生成,所以采用用户ID进行分流避免了用户体验不一致的问题。
▼ 缺点:当同一个用户命中多个实验时,无法满足正交性。假设首页改版实验和海外发券实验共享同一拨实验组和对照组,现发现实验组效果显著提升,无法归因该提升是因为发券还是首页改版策略。
那该如何满足以上原则进行合理分流呢?
HASH大法好!来,接着往下看怎么用
3
分流方法③——Hash🚩
先从一个简单的例子进行入手理解。
假设现在有10万个电影信息,现在给你一个电影名称,需要你确认这个电影是否在这10万的电影当中。如果我们进行一一匹配,且电影名称又比较长,那么这种方式去检索确认无疑是非常慢的。现在如果存在一个函数可以将这10万的电影分别映射到一个数字,也就是得到一个10万行的电影和数字对应关系表。对于需要检索的电影,那么用同一个函数进行计算,得到一个数字N,那么只需要检索这个N是否在这10万个数字当中即可。
这就是hash算法。hash算法的核心之处在于,字符串(电影信息)与数字的映射关系。用一张图来加强对Hash算法的理解:
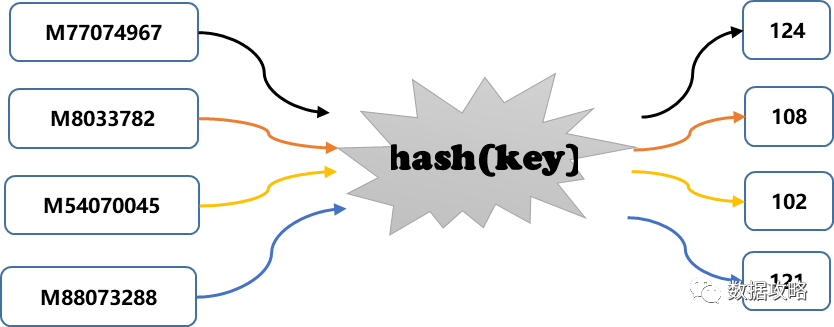
▌Hash算法性质
确定性:相同的输入,得到的hash结果是一样的。同样的,输出结果不一样,那么输入值肯定不相同 散列碰撞:散列函数的输入和输出不是唯一对应关系的,输出结果一样,输入结果可能相同也可能不同 不可逆性:一个哈希值对应无数个输入值,理论上你并不知道哪个是。 混淆特性:对输入的内容进行部分修改,可以产生一个完全不一样的输出
① 假设输出字符串为 M77074967,该字符串为"张一"用户的UID
② 将字符串进行拆解成单个字符,也就是,M,7,7,0,7,4,9,6,7
③ 对于非数字的M,进行ASCII编码,结果为77
④ 将所有数字及转义后的ASCII编码进行相加,得到124
同样的,我们可以对其他UID进行处理,可得到M8033782为108
② 散列碰撞:以上案例中字符串M77074967得到的结果是124,当对调后两位,也就是M77074976,最后计算得到的结果依旧是124。所以说输入和输出不是唯一对应关系的,输出结果一样,输入结果可能相同也可能不同。
③ 不可逆性:结合散列碰撞的特性,给定hash结果为124,无法反向推算输入的字符串。
④ 混淆特性:如果将输入M77074967修改为M77074960,那么得到的结果就是117。也即,对输入的字符串仅做部分修改,可以产生一个完全不一样的输出。
▌Hash常见算法
MD4:MD4(RFC 1320)是 MIT 的Ronald L. Rivest在 1990 年设计的,MD 是 Message Digest(消息摘要) 的缩写。它适用在32位字长的处理器上用高速软件实现——它是基于 32位操作数的位操作来实现的。
四、Hash分流步骤
先罗列一下HASH分流的步骤:
② 选用一个HASH函数,比如MD4
③ 确认分组数量N,比如随机分成100组
④ 通过HASH(Layer,Target)%N确认每一个测试单元对应的分组信息。
1、确认分层信息
分层信息可以理解为,给输入的字符串加一点点作料。
分层信息可以为任意的字符串。在这里以小写的『a』作为分层信息,可以先记住这个点,后续再来理解分层信息的作用。
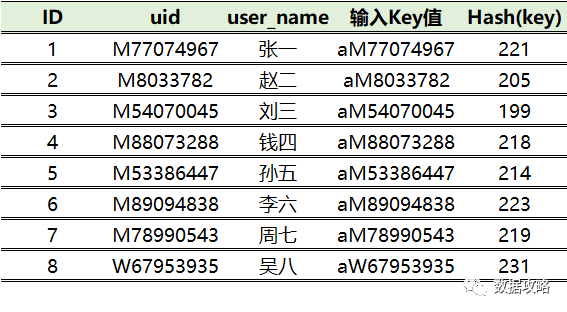
① 字母『a』的ASCII编码是97,字母『M』的ASCII编码是77
② 所以uid=M77074967的输入值是aM77074967,模拟Hash算法得到
97+77+7+7+0+7+4+9+6+7=221
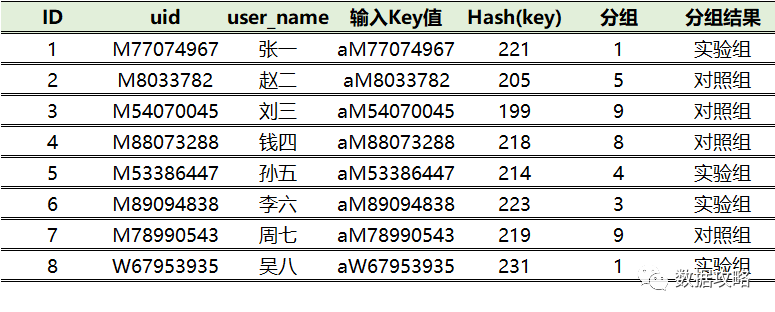
本次实验首页改版计划选取50%的用户,所以将分组数量确认为10,也就是将用户均匀的分成10组,取值范围为0,1,2,3,4,5,6,7,8,9。分组结束后,选择0-4作为实验组,也就满足了50%的用户量选取。
4、确认用户分组信息
第②步中已计算出Hash(key)的模拟值
第③步预先设置的分组为10
并将0-4区间的用户标记为实验组,
所以对每个Hash值除10取余得到如下结果:
五、正交实验设计
由于本次总共涉及到两个实验同时要上线,怎么能说明指标的提升是对应xx策略带来的影响呢?带来的影响是多少?如何可以保证严密的因果关系?
即,该如何设计实验保证多实验间的独立性呢?
一般情况下,实验设计类型分为:
② 实验正交,采用不同的分层信息
分别来说说根据以上两种类型
文章开头介绍的俩实验如何设计:
▌实验互斥
将实验分成4组,分层信息为『a』
将0和1分别作为首页改版实验的实验组和对照组用户
将2和3分别作为海外发券实验的实验组和对照组用户
分组结果如下:
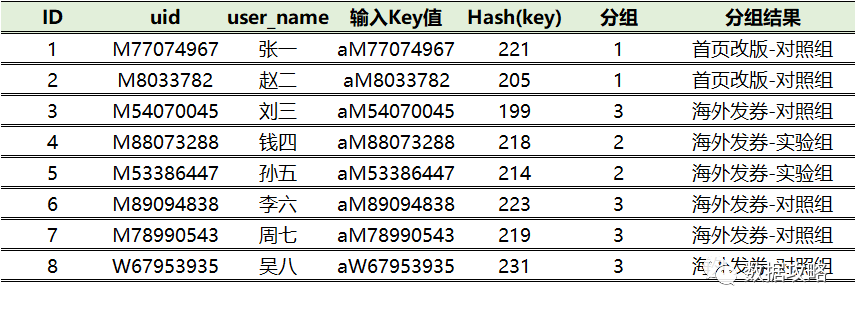
① 本次样例实验用户数较少,所以存在分桶不均衡的情况。在实际工作中,样本量足够大的情况下,HASH算法可以均匀的将用户随机分到每一组中。
② 互斥实验意味着两个实验之间相互不干扰
▌实验正交
① 使用分层信息『a』将用户分成2组,0表示首页改版实验组,1表示首页改版对照组
② 使用分层信息『b』将用户分成2组,0表示海外发券实验组,1表示海外发券对照组
分组结果如下:
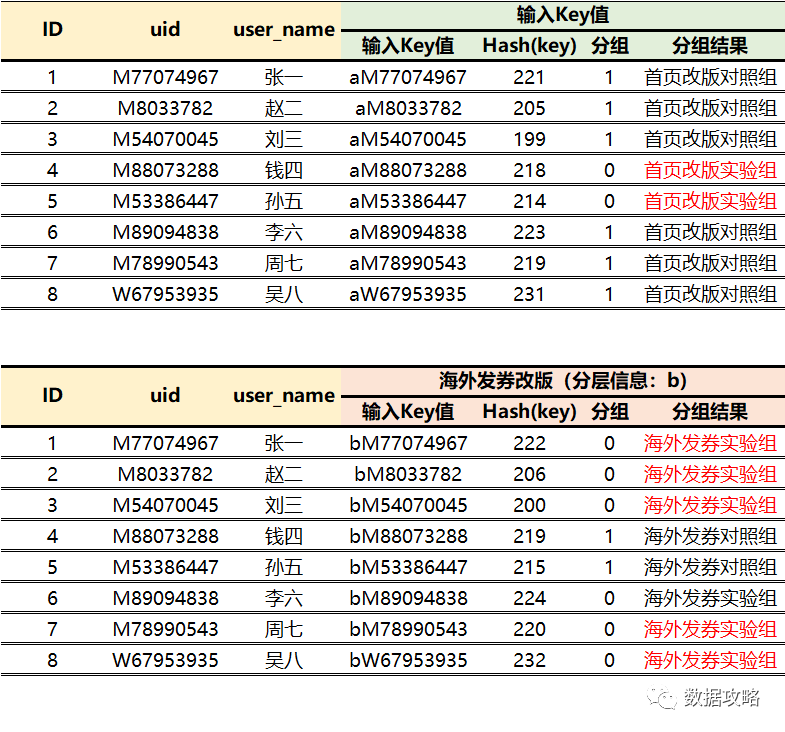
① 两个实验采用不同的分层信息,对于同一个UID输入的key值不一样,比如第一个用户M77074967,在首页改版实验中,输入的key值为aM77074967,而在海外发券实验中输入的key值为bM77074967.
② 对于张一用户来说,他即是首页改版实验的对照组用户,也是海外发券实验的实验组用户。所以实验之间并不是互斥,也就是属于实验正交的情况。
以上就是关于『AB实验分流』的举例讲解
对了,历时4个月,六哥联合业界朋友开发的
百万数据集『AB实验项目实战课』上线了
如果想系统掌握AB实验知识点、攻克面试考点细节等疑问
欢迎来精进,一个项目教你 会做会写又会说!
如若盼 追更 『求职类』干货系列 
 往期好文推荐
往期好文推荐 
Ps. 微信推文改了规则
看完记得设置为 “ 星标 ”
不然我会消失的
点个在看,肝『干货』更有动力
