




点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容

于是本篇,换个玩法
相关的思路/答案解析 是你们的主场

 )
)一、选择题
① 概率论&机器学习
② 大数据技术
③ SQL技能
④ 逻辑推理
二、编程题
答案:A
答案:C
答案:D
【A】随机森林可以是分类树也可以是回归树,GBDT的树只由回归树组成
【B】都是boosting方法
【C】随机森林的扰动属于属性扰动,不属于样本扰动
【D】随机森林对异常值敏感,GBDT对异常值不敏感
答案:A
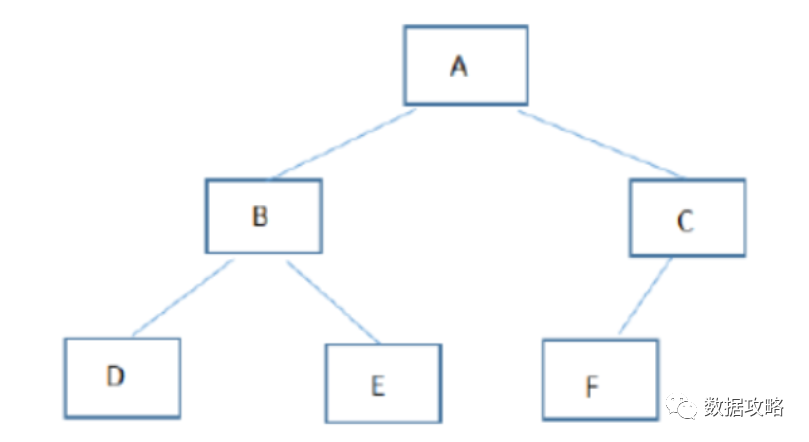
【A】 ABDECF
【B】ABCDEF
【C】DBEAFC
【D】DEBFCA
【A】四格表的卡方检验计算时,卡方值=(ad-bc)2n/(a+b)(c+d)(a+c)(b+d),此时用于进行配对四格表的相关分析,如考察两种检验方法的检出率有无差别。
【B】卡方检验最常见的用途就是考察某无序分类变量各水平在两组或多组间的分布是否一致实际上。
【C】卡方检验是离散分布。
【D】根据χ2分布及自由度可以确定在H0假设成立的情况下更极端情况的概率P,如果P值很小,说明观察值与理论值偏离程度太大,应当拒绝无效假设。
1, 以下哪个不属于大数据流式数据处理框架( )
【A】Hive
【B】Spark Streaming
【C】Storm
【D】Flink
【A】可靠性
【B】分布式
【C】低延迟数据访问
【D】高吞吐量
【A】2
【B】3
【C】4
【D】5
答案:B
【A】Partitioner
【B】RecordReader
【C】Mapper
【D】Reducer
答案:D
【A】avg
【B】percentile_approx
【C】ntile
【D】percentile
答案:D
【A】第二范式中不能有多个主键
【B】第三范式是指属性可以有传递依赖
【C】第一范式是指一个字段只存储一项信息
【D】第二范式是指属性完全依赖于主键
答案:B
【A】需具备可更新性
【B】反映历史变化
【C】数据是可冗余的
【D】是面向主题的
答案:A
【A】两者都可以频繁修改索引列
【B】聚集索引不一定会比非聚集索引性能更优
【C】聚集索引的叶节点就是最终的数据节点,而非聚集索引有一个指向最终数据的指针
【D】聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
A:一个表中必须有主键
B:主键的值不可重复
C:一个表中只能有一个主键
D:主键的值可以为空
答案:BC
1,以下哪条SQL语句可以返回table_A中的全部的key()
【A】
select tabel1.keyfrom table1left semi join tabel2on table1.key=table2.key
【B】
select tabel_A.keyfrom table_Ajoin tabel_Bon table_A.key=tabel_B.key
【C】
select tabel_A.keyfrom table_Aright semi join tabel_Bon table_A.key=tabel_B.key
【D】
select tabel_A.keyfrom table_Aleft outer join tabel_Bon table_A.key=tabel_B.key
【A】
selectdistinct(userid)from orders o1where o1.pid = 'p01'and exists (select 1 from orders o2 where o1.userid= o2.userid and o2.pid='p02')
【B】
selectdistinct (o1.userid)from orders o1left join orders o2on o1.userid= o2.useridand o2.pid='p02'where o1.pid='p01'
【C】
select distinct (userid)from orders olwhere ol.pid in ('p01','p02')
select distinct (userid)from orders olwhere ol.pid = 'p01'and ol.pid = 'p02'
3, 有如下一段json字符串信息info:
[{"type":"Promo fund","currency":"AUD","amount":15,"actualAmount":15,"rebatePolicyIDs":[214,215]},{"type":"AirlineRebate","currency":"AUD","amount":7,"actualAmount":7,"rebatePolicyIDs":[450283,450284]}]
我们想拿到type为Promo fund对应的currency、amount及对应rebatePolicyIDs的第一个活动ID promoid,结果如下:
type
promoid
currency
amount
可以执行以下哪段sql语句()
【A】
selectget_json_object(default.json_array(info)[0],'$.type') as type,get_json_object(default.json_array(info)[0],'$.rebatePolicyIDs') as promoid,get_json_object(default.json_array(info)[0],'$.currency') as currency,get_json_object(default.json_array(info)[0],'$.amount') as amount
【B】
selectget_json_object(default.json_array(info)[0],'$.type') as type,default.json_array(get_json_object(default.json_array(info)[0],'$.rebatePolicyIDs'))[0] as promoid,get_json_object(default.json_array(info)[0],'$.currency') as currency,get_json_object(default.json_array(info)[0],'$.amount') as amount
【C】
selectget_json_object(info,'$.type') as type,default.json_array(get_json_object(info,'$.rebatePolicyIDs'))[0] as promoid,get_json_object(info,'$.currency') as currency,get_json_object(info,'$.amount') as amount
【D】
selectget_json_object(info,'$.type') as type,get_json_object(info,'$.rebatePolicyIDs') as promoid,get_json_object(info,'$.currency') as currency,get_json_object(info,'$.amount') as amount
4,有一张表test:CREATE TABLE test(a INT )。表中共有4行数据,字段a的值分别为:1、2、3、NULL,下面运行结果为()
SELECTSUM(a),COUNT(DISTINCT a),COUNT(1),AVG(a)FROM test
【A】6、4、4、1.5
【B】NULL、3、4、2
【C】NULL、4、4、1.5
【D】6、3、4、2
1,下图中,对应的图形为()
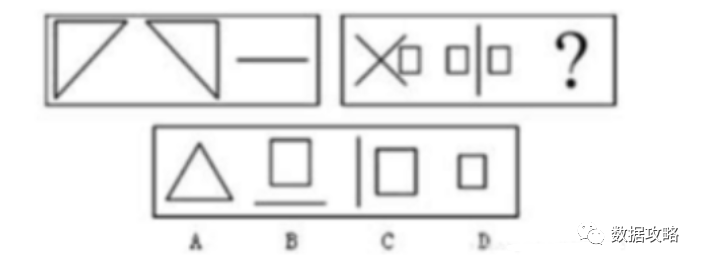
【A】A
【B】B
【C】C
【D】D
答案:D
记录的表为ctrip_hotel_order,其中:
order_id:订单id
hotel_id:被访问的酒店id
hotel_id:酒店ID
hotel_name:酒店名称
hotel_id:酒店id
hotel_name:酒店名称
order_num:订单量
注意:当订单量重复时,请按照 hotel_id 升序排列,最终输出至多两条数据
selecthotel_id,hotel_name,order_numfrom(selectb.hotel_id,b.hotel_name,count(distinct a.orderid) as order_numfrom ctrip_hotel_order ajoin ctrip_hotel_info bon a.hotel_id = b.hotel_idgroup byb.hotel_id,b.hotel_name)torder by order_num desc,hotel_id asclimit 2;
携程酒店有两张数据表。
用户表(user1)存放所有用户信息,包含
uid:用户id
name:姓名
orderid:订单id
uid:用户id
cost:用户该单付款金额
hotelid:入住酒店ID
uid: 用户id
name: 姓名
avg_cost: 单均价。
单均价用数学平均,结果四舍五入保留一位小数即可 如果用户在历史上没有下过任何订单,则记为0
最后结果按照用户单均价由大到小降序排列
如果单均价相同,则按照用户id升序排列
selecta.uid,a.name,round(sum(a.cost)/count(distinct a.orderid),1) as avg_costfrom(selecta.uid,a.name,ifnull(b.orderid,1) as orderid,ifnull(b.cost,0) as costfrom user1 as aleft join order1 as bon a.uid = b.uid)agroup bya.uid,a.nameorder byround(sum(a.cost)/count(distinct a.orderid),1) desc,a.uid asc;
问题 ③
携程人力资源系统中,部门表为department,包括字段:
bu_id:部门id
bu_name:部门名称
emp_id:员工id
emp_name:员工姓名
bu_id:部门ID
salary:员工薪资
level:职级(范围:1-10)。
bu_name:部门ID salary_avg:平均工资
▼ 参考答案:
select bu_name,salary_avgfrom (select bu_name,round(avg(salary),2) as salary_avgfrom department ainner join employee b on a.bu_id = b.bu_idwhere b.level >= 5group by bu_namehaving round(avg(salary),2)>= 9000) torder by salary_avg desc;
以上就是相对完整的携程笔试真题~
后续六哥会继续收集整理更多大厂笔试真题
如果你有相关资料,也欢迎联系我一起共享+共建
如若盼 追更 『求职类』干货系列 

Ps. 微信推文改了规则
看完记得设置为 “ 星标 ”
不然我会消失的

 往期好文推荐
往期好文推荐 