点击上方蓝色【数据有道DataHayWay】关注+星标~
第一时间获取最新内容
之前介绍过AB实验系统框架
今天,来 “ 填坑” 了!开启AB实验步骤详解篇~
本篇,唠唠 —— 『设定目标、制定方案』
重点讲讲:
▶ 如何分流?
假设此时做了一个AB测试已有了假设并建立了观测指标,此时需要设计具体的实验方案。主要包括2个方面,
① 实验前需要保证所设计实验是有效的;
② 实验后要确立假设检验方法,来检验组间差异,即实验效果的显著性。
本篇重点讲第一部分:
—— 实验前的步骤&注意事项
实验前主要包含以下步骤:
一、确立随机化单元及目标群体;
二、确定实验样本量;
三、预估实验周期;
四、确立分组逻辑
① Hash算法
② 分流原理
确立目标群体前,其实需要先确定随机化单元,一般C端业务选择随机化单元为用户。例如:抖音平台想要针对浏览时长不足10s的用户做浏览领红包奖励策略,即需要选择浏览时长<10s的用户;再比如:抖音电商对商家开发了一个新的功能,想测试该功能对商家运营商品是否有价值,那么此时的测试单元就是商家,而不是抖音电商购买的用户。
由于实验的样本量大小(如用户量)会直接影响结果精度。如果样本量过小则可能造成随机性结果的可能性较高,则实验结果失去统计学意义。拿上面的例子,抖音平台想要针对浏览时长不足10s的用户做浏览领红包奖励策略的AB实验:
测试目标是提升有效浏览用户量
- 衡量指标是人均浏览时长(单日浏览总时长/单日命中实验用户)
假设浏览不足10s的用户3000左右,分流灰度比例在1%,则每天命中实验的实验组UV达30人,实验运行一段时间后检测实验结果,实验的结果很容易受到异常样本影响。例如,抖音“重度使用”用户小李由于前段时间正逢考试周闭关修炼,特意克制考试周刷抖音的时间,恰好分在了实验组,考完试决定好好过把瘾,那么小李的浏览时长就可能带偏整个实验组的统计结果。业务侧之所以做AB测试,是由于无法确认改进版本的效果优劣,需控制变量法来得到结果。
因此综上所述,实验期间的样本量(流量)不宜选择过大,但又需要满足可做显著性检验的样本量,在一定程度上避免随机带来的误差结果。
故在实验前需要预估命中实验的流量是否达到最小样本量要求。
决定实验样本量的考虑因素:
① 样本标准差:如果实验指标选取的为是否有效浏览(即用户是否有效浏览,无论浏览时长是多少),而非人均浏览时长,则该指标的标准差相对后者较小,即说明更小的样本量即可达到相同灵敏度。注:灵敏度即检验到显著差异的能力,会随着标准差的降低而提高。(后期会开启关于灵敏度的专篇讲解)
② P值设定:如果想用更小p值,即需要更有把握的来拒绝原假设,则需要增大样本量。
③ 实验层:实验是否需要和其他实验共享流量?即单层互斥实验还是多层正交运行多个实验?
如果是前者,每个实验只能得到较小流量,需注意满足最小样本量要求以及后续逐步扩大灰度的流量是否够用。
在实验开始前,需要判断实验需要运行多久,太长或太短都不适宜。通常有以下考虑因素:
一般在实验开始前应当预估对应实验评估指标的提升效果,根据预估的提升效果来计算若要达到显著需要的最小样本量
实验周期=根据差异预估的对应每组最小样本量 ÷ 每天进入实验的流量② 周期效应
对于某些行业的产品来说,用户的操作行为存在很大的周期性变化。常见的例如周内效应、季节性效应。- 周内效应:例如视频播放产品,周末与工作日的流量与表现可能会有显著差异,因此实验应至少覆盖完整的用户行为周期(至少≥一周)较为客观。
- 季节性效应:针对一些特定的实验,需要考虑到一些用户在不同周期的表现差异巨大。例如电商行业发放优惠券,则需要考虑到有明显的季节性/节假日大促因素,双十一期间的券吸引力和核销量肯定好于其他的销售淡季。
③ 新奇效应
部分实验可能会存在刚开始有比较强烈/微小的反应,用户要经历一段适应的过程,因此需要一定适应期逐渐建立用户基础,然后再考察实验结果。因此,综上所述,合理的实验周期应该在满足最小样本量的前提下,需要根据对应的实验策略特点,考虑到用户的行为周期和适应期时间。简单做法,可以为每个用户随机产生一个1-100之间的整数,将1-50作为实验组,51-100作为对照组。这种方法可行,但是在实际应用过程中,具有很多弊端,比如算法不稳定,实验较多时,正交性无法保证。业界最常用的分流算法就是HASH算法,那么在正式介绍流量分桶之前,先对Hash算法做一个简单的了解。从一个简单的例子进行入手理解。假设现在有10万个电影信息,现在给你一个电影名称,需要你确认这个电影是否在这10万的电影当中。如果我们进行一一匹配,且电影名称又比较长,那么这种方式去检索确认无疑是非常慢的。现在如果存在一个函数可以将这10万的电影分别映射到一个数字,也就是得到一个10万行的电影和数字对应关系表。对于需要检索的电影,那么用同一个函数进行计算,得到一个数字N,那么只需要检索这个N是否在这10万个数字当中即可。这就是hash算法,hash算法的核心之处在于,字符串(电影信息)与数字的映射关系。确定性:相同的输入,得到的hash结果是一样的。同样的,输出结果不一样,那么输入值肯定不相同散列碰撞:散列函数的输入和输出不是唯一对应关系的,输出结果一样,输入结果可能相同也可能不同不可逆性:一个哈希值对应无数个输入值,理论上你并不知道哪个是。混淆特性:对输入的内容进行部分修改,可以产生一个完全不一样的输出MD4:MD4(RFC 1320)是 MIT 的Ronald L. Rivest在 1990 年设计的,MD 是 Message Digest(消息摘要) 的缩写。它适用在32位字长的处理器上用高速软件实现——它是基于 32位操作数的位操作来实现的。MD5:MD5(RFC 1321)是 Rivest 于1991年对MD4的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4 相同。MD5比MD4来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好。SHA-1:SHA1是由NIST NSA设计为同DSA一起使用的,它对长度小于264的输入,产生长度为160bit的散列值,因此抗穷举(brute-force)性更好。SHA-1 设计时基于和MD4相同原理,并且模仿了该算法。① 如前面提到,确认测试单元Target之后,再确认分层的Layer(举例:这里的Layer可以是任意字符串或者数字),因为hash算法的混淆特性,不同的layer表达的不同的分层。对于同一批测试单元,使用两个不同的Layer,可以保证两次分流之后用户之间可以实现正交的特性。④ 通过HASH(Layer,Target)%N确认每一个测试单元对应的分组信息。举例:假设现在有4个用户,选用两个不同的Layer,且N设置为4,将得到两列不同的哈希值。即可得到每层Layer每一个用户的哈希值。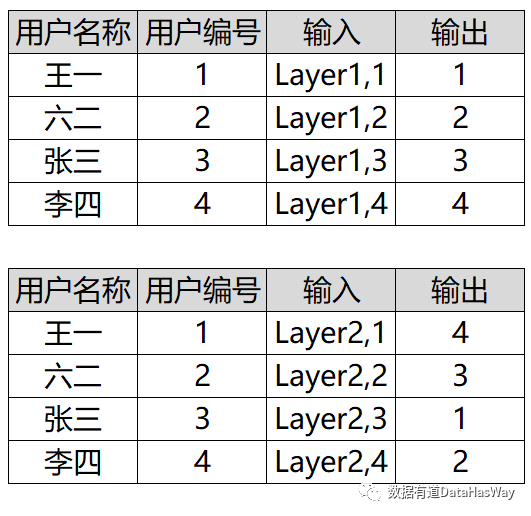
ps:有兴趣的同学也可以详细的阅读一下Google 在 KDD 2010 发表的论文:《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》
点击文末下方名片,进入公众号后台 回复关键字 “ 分流 ” 即可直接获得论文资料 !如若盼 追更 AB系列
回复关键字 “ 分流 ” 即可直接获得论文资料 !如若盼 追更 AB系列 
欢迎大家转发,点亮在看 更多 『求职干货』 & 『日常学习』 系列好文,等你发现~往期好文推荐
更多 『求职干货』 & 『日常学习』 系列好文,等你发现~往期好文推荐





 数据分析岗 | AB实验框架+高频考点(一)
数据分析岗 | AB实验框架+高频考点(一)
