




听起来以为是 送分题,实则有可能是 “ 送命 ” 题 !
APP整体留存率却下降了,
问作为BI的你,如何分析?
▶ 面试官在考你什么?
▶ 这类问题到底是啥?该如何回答?
乍一看以为是异常归因类题型,实则不是!
其实,这就是统计学中的经典问题—— 辛普森悖论!
待我一 一解析道来。
------正文手动分割线------
抛一个之前写在星球的生活常见例子
可以先思考,你的答案是什么 ~
例:昨天小李买了苹果和梨子,今天这两种水果的单价都涨价了。
问:今日小李购买这两类水果,所花平均价格是否一定会上升?
答:不一定!
❓ 为什么
我们利用 极端假设,先快速理解一番:
昨天,苹果卖2元/斤,梨子4元/斤,
-小李嗓子疼,只买了1斤梨子润润喉,均价花了4元;
今天,苹果涨价到3元/斤,梨子5元/斤,
-小李觉得梨子卖的太贵了,就只买了1斤苹果,均价花了3元。
因此,并不一定涨价了所买均价一定会提升~
有同学肯定会反驳这个例子,
说:题目描述小李两类水果都买了,举得例子却是只买了其中一种水果,
所以,结论不对!
再啰嗦的举一个不极端的case:
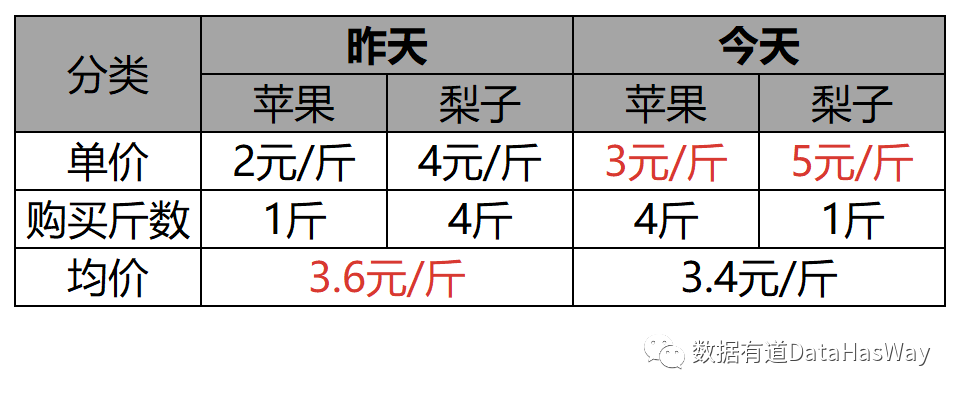
假设昨日苹果和梨子价格分别为2元/斤、4元/斤,小李各买了1斤、4斤。
今日分别上调为3元/斤,5元/斤,小李各买了4斤、1斤。
-- 昨日平均价格为:(2*1+4*4) 5=3.6元/斤
-- 今日平均价格为:(3*4+5*1) 5=3.4元/斤
因此,同样出现:今天购买水果的均价<昨天购买均价 !
借上述例子,下面,来系统总结一下 
什么是辛普森悖论?为啥会发生?
常见发生场景有哪些?该如何避免?
1
啥是辛普森悖论
—— 引用百度百科的官方定义:
辛普森悖论为英国统计学家E.H.辛普森于1951年提出的悖论:
在某个条件下的两组数据,分组研究时都会满足某种性质,可是一旦合并考虑,却可能导致相反的结论。
直白来理解,拿上面的例子:
分开说均价,两类水果都涨价了,合起来算均价,反而可能降了。
这种 “反直觉” 的现象就是 辛普森悖论。
2
为啥会出现
简言之,就是分组和整体看时,受到分组群体权重系数 (样本量) 的影响。
具体解释就是:分组后其中的主要群组的影响权重更大,
样本相对较小的群组单个看,虽然可能在数据指标上表现更高,
但放在一起看,对于总体指标表现影响较小,即话语权较小,从而形成了辛普森悖论。
还是上面的例子:
小李购买苹果和梨子所花均价,除了和两类水果的单价有关,其实还和小李想各买多少斤的意愿有关。
来张图,直观看下上述例子,均价到底咋受影响?
=3.6元/斤
今天小李购买水果的均价
因此,小李想买的斤数就是其中的混杂变量,作为权重,其实影响着最终均价结果。
3
常遇哪些场景
【1】异常定位
// 例如,对于某页面在9月份,男性女性用户点击率同比8月均增长,为何用户总体点击率下降?//
// 例如,想知道APP中某个频道的用户浏览次数与APP使用时长的关系,直觉上呈正相关,结果做回归模型发现相关关系为负,为什么?//
//例如,上了一个产品策略在灰度时效果是显著正的,结果全量了效果对全站影响为负//
(挖个坑,下次开AB系列文章时专门来讲 ~)
4
该如何避免
分析前问自己:
所分析的问题是否有必要拆分维度?
——当数据与业务sense不一致时,再决定下钻拆分。
如果细分维度,如何选取维度?
——结合业务理解,判断哪些维度拆解具有实际业务指导意义。
分析中请牢记:
辛普深悖论和各组样本量大小有关系,可以结合实际问题,定义个别分组的权重,用以消除基数差异影响。
这里,可以套用全概率的知识点来做具体分析:
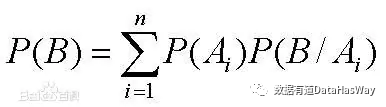
即同时考虑各分组 “质” 和 “量” 的问题来做统一定量描述。
同时,辛普森悖论常常跟混淆变量有关,
要 注意 频率统计无法直接揭示因果关系,
要从数据背后,结合 业务实际目标及含义,找到根因、发现异常。
知识点总结 ↓
一切看似简单的问题,其实可能涉及多变量,如果只说某一变量表现,问你最终结果的问题都是在挖坑!
工作时,要!谨!慎!
普适性数据(算数平均)是否有参考意义?要结合实际业务,case by case具体甄别!
以上,结合实例,就是从定性及定量角度,来理解 辛普森悖论 。
如若其中某一方点对你有帮助,欢迎点赞,点亮在看
也可以在公众号后台找到我,说说你目前的困惑 ~

欢迎关注
更多 『求职干货』 & 『日常学习』 系列好文,等你发现~
