




作者:吴炳锡
知数堂联合创始人及MySQL高级讲师,3306π社区联合创始人,腾讯TVP成员。
本文导读
整体结构
Radon中配置了解
Radon中表的分类
不同类的SQL在Radon针对不同表的拆分路由情况
基于RadonDB Schema实现及最佳建议
RadonDB SQL限制
总结
全文7200字,阅读时间大概20分钟。
这篇也可以说是:RadonDB使用最佳建议,从原理上了解RadonDB的拆分后数据访问逻辑。Radon中整理架构如下:
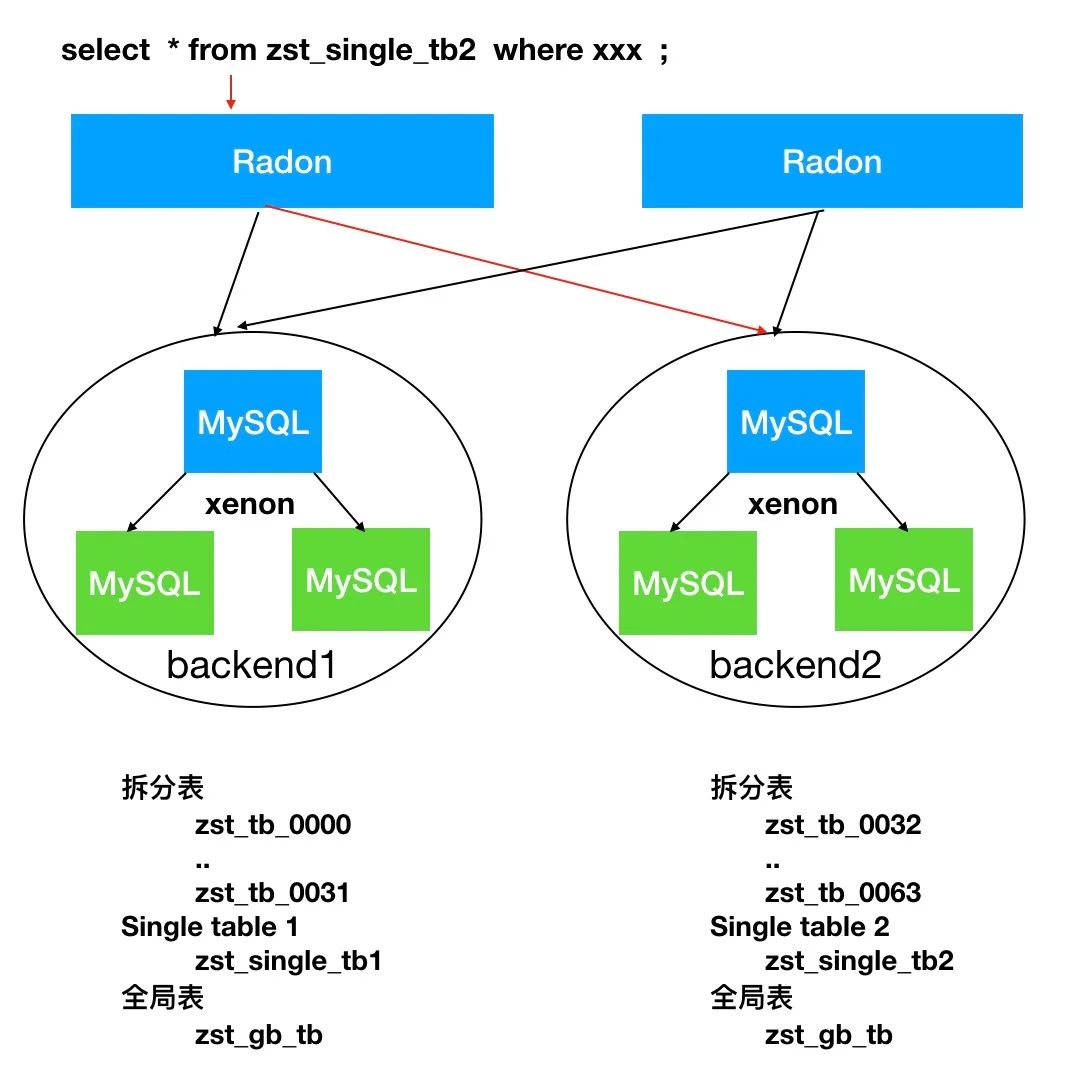
在Radon的架构中可以利用“表名”唯一,同时利用global table, 拆分表, single table 特性实现table在RadonDB集群中分布。
为什么要使用Radon构建数据统一访问层呢?主要有以下原因:
原生高可用实现
配置自动化,不需要对每个表定义拆分规则
基于golang开发,轻量,易部署,易管理
先了解Radon配置项
config
{
"max-connections": 支持前端应用最多少个连接连到Radon上, [required]
"max-result-size": 返回结果,最大支持多少byte, [required]
"max-join-rows": 在join运算中,最多有多少行可以参与. [required]
"ddl-timeout": DDL超时的时间, [required]
"query-timeout": Radon中DML含select运行超时间(in millisecond), [required]
"twopc-enable": 是否使用Radon分布式事务提交,如果需要显式使用begin,commit需要开启, [required]
"allowip": ["allow-ip-1", "allow-ip-2"], [required]
"audit-mode": 开启审计日志, "N": disabled, "R": read enabled, "W": write enabled, "A": read/write enabled, [required]
}
更改参数参考:
curl -i -H 'Content-Type: application/json'-X PUT -d '{"max-connections":1024, \
"max-result-size":1073741824, "max-join-rows":65535, \
"ddl-timeout":3600000, "query-timeout":60000, \
"twopc-enable":true,,"audit-mode":"A"}' http://127.0.0.1:8080/v1/radon/config
max-result-size 返回结果,最大支持多少byte max-join-rows 在join运算中,最多有多少行可以参与 query-timeout Radon中DML含select运行超时间(in millisecond)
Radon支持表类型:
single 表
global 表
拆分表
可以指定拆分数量的拆分表
single表:默认只会存在第一个节点。这是因为在Radon中很多show语句请求是默认转发到第一个节点,所以对于single表也默认存在第一个节点上,也可以通过distributed by指定存储的后端节点。对于写入读取Radon可以透明传输,性能也是最高的。
创建方法:
create table tb_single(id ..
...
)engine =Innodb single distributed by(backend1);
对业务不明的情况下,可以考虑所有表建成single table通过distributed by指定single表在分端节点的分布,将来数据量大了,利用Radon的Reshard功能重新拆分即可。
global表: RadonDB后面各个分组上都会存在, 对于写入Radon使用分布式事务,所有的节点都会写一份数据,适合在写少读多的场景的表。例如,全国地理位置信息等。创建语法:
create table tb_global(id ..
...
)engine =Innodb global;
分区表: 也可以说是Radon中的拆分表,每个表默认按64个小表进行拆分,默认按该表的主键运行hash的方式拆分,而该hash,只能对单个字段运行,所以不能出现联合索引的主键。创建语法:
create table tb_part(id ..
...
)engine =Innodb;
CREATE TABLE zst_bt (
id INT notnull,
c1 varchar(32) notnull
store_id INT
)
PARTITION BY HASH(id)
PARTITIONS 4;
Radon中SQL执行流程
在RadonDB中,Radon担任着SQL解析和结果汇聚类的运算。针对该架构,SQL在Radon中执行,大致分为5大类:
单表(拆分表)查询中where条件有拆分键,对于global table, single table都是tcp转发,行为简单就不在列举
单表(拆分表)查询中where条件不包含拆分键
single table和拆分的join操作
global table和拆分的join操作
两个拆分的表做join操作
第一类 拆分表where条件中包含主键的等值查询
对于拆分表带有明确的拆分运算的语句,可以直接精确的投递到后面的节点,运算后直接返给前端。例如:select k from sbtest1 where ID=10; 其中id是拆分键。还有一类, 例如select k from sbtest1 where ID in (1,2,3,4,5); Radon也可以明确算出来以上数据在那个子表,明确给计算出来。
第二类 单表(拆分表)查询中where条件不包含拆分键
查询中不包含拆分键,同样表是拆分表的情况下,该sql会发向所有后面的节点上该表的拆分表,进行运算,然后在Radon上进行结果集的排序合并处理,返回给前端。例如:select id, k from sbtest1 where k=499 limit 10; 这类SQL中比较复杂,实质上是走的Radon对SQL分布,然后在中间件汇聚结果,最终展示(这个过程有点类似于google开源的Vitess)。
第三类 single table和拆分的join操作
对于非分表: single table
(只在后面某一个节点上存储,一般是第一个节点)和拆分表做join ,如:
CREATE TABLE clv2 (
CountryCode char(3) NOT NULL DEFAULT '',
...,
PRIMARY KEY (CountryCode,Language),
KEY CountryCode (CountryCode)
) single;
SQL语句:
select a.Name, a.Population , b.Language, b.IsOfficial \from city a, clv2 b where a.CountryCode =b.CountryCode \limit 10
转化为:
{"Query": "select a.Name, a.Population, a.CountryCode from \zst.city_0000 as a order by a.CountryCode asc","Backend": "`backend1`","Range": "[0-64)"},...{"Query": "select a.Name, a.Population, a.CountryCode from \zst.city_0063 as a order by a.CountryCode asc","Backend": "`backend2`","Range": "[4032-4096)"},{"Query": "select b.language, b.IsOfficial, b.CountryCode from \zst.clv2 as b order by b.CountryCode asc","Backend": "`backend1`","Range": ""}"Join": {"Type": "INNER JOIN","Strategy": "Sort Merge Join"},"Limit": {"Offset": 0,"Limit": 10}
从上面可以看出来对于分区表和single的join被拆分成两步,第一步 分别在backend1,backend2上操作 SQL:
select a.Name, a.Population, a.CountryCode \from zst.city_XXXX as a order by a.CountryCode asc ;
第二步执行:select b.language, b.IsOfficial, b.CountryCode \ from zst.clv2 as b order by b.CountryCode asc ;
最终在Radon上按流式合并返回。如果需要顺序返回则后面需要添加order by ,如:
select a.Name, a.Population , b.Language, b.IsOfficial \from city a, clv2 b where a.CountryCode =b.CountryCode \order by Name limit 10;
在执行计划中会根据排序字段排序返回:
"GatherMerge": [
"Name"
],
第四类 global table和拆分的join操作
global table
(后端每个节点上都存在)该类表的查询行为可以明确约定,对global表的单表操作不用做SQL改写,目前读操作按轮询的机制发向后端节点进行处理。对于join操作,对分区表改写,global表不动直接下发. 如
CREATE TABLE countrylanguage (
CountryCode char(3) NOT NULL DEFAULT '',
Language char(30) NOT NULL DEFAULT '',
...
PRIMARY KEY (CountryCode,Language),
KEY CountryCode (CountryCode)
) global;
测试SQL语句:
select a.Name, a.Population , b.Language, b.IsOfficial \from city a, countrylanguage b where \a.CountryCode =b.CountryCode limit 10;
拆分为:
{"Query": "select a.Name, a.Population, b.language, b.IsOfficial \from zst.city_0000 as a, zst.countrylanguage as b where \a.CountryCode = b.CountryCode limit 10","Backend": "`backend1`","Range": "[0-64)"},...{"Query": "select a.Name, a.Population, b.language, b.IsOfficial from \zst.city_0063 as a,zst.countrylanguage as b where \a.CountryCode = b.CountryCode limit 10","Backend": "`backend2`","Range": "[4032-4096)"}],"Limit": {"Offset": 0,"Limit": 10}
从执行计划上可以看出来对于global表的join操作,相当于把分区表,表名改写后进行下推运算,如果没有排序,直接流式返回,如果有排序,则需要全部数据执行完毕后排序返回给前段。
第五类 两个分区表join操作
两个分区表join操作:
select a.Name, a.District, a.Population, b.Name from city a ,\country b where a.CountryCode=b.Code \and b.name='China' order by a.Population desc limit 10;
对于该类SQL Radon也会给转为表的请求,如:
{"Query": "select a.Name, a.District, a.Population, a.CountryCode \from `zst.city_0000` as a order by a.CountryCode asc","Backend": "backend1","Range": "[0-64)"},...{"Query": "select b.Name, b.Code from `zst.country_0063` as b\where b.name = 'China' order by b.Code asc","Backend": "backend2","Range": "[4032-4096)"}..."Join": {"Type": "INNER JOIN","Strategy": "Sort Merge Join"},"GatherMerge": ["a.Population"],"Limit": {"Offset": 0,"Limit": 10}
从上面可以看出来,一个join语句也被拆分成两个单个SQL执行,最终在Radon上做结果的合并,返回给前端。
基于RadonDB Schema实现及最佳建议
因为以上的设计,为了在Radon中获取最佳的性能,建议遵循以下规则
对于数据量较小的表,有频繁更新读的表,建议使用single表,即可。
对于写量少,但读取量大,或是经常需要和其它表进行关联查询的,可以使用global表。
对于数据量大,写入量也大,且有高并发写入的业务,可以使用分区表。对于高速数据写入RadonDB表现比较好。对于分区表,实质上最需要注意的是分区键选择。默认官方建议是使用id bigint auto_increment 做分为分区键,而且Radon中代码写入,对于是Id的列名(不论大小写),全部要使用bigint定义。但实际使用,减少业务中读放大的问题,建议使用业务中的主键做为分区键,例如:UserId ,OrderId,MsgId, ImageId等等有意义的字段,该字段需要定义成为主键或是唯一索引。对于分表数量,建议从物理表大小,子表单表10G以内,子表总行数来考虑1500万以内,避免拆分过多的问题。
在SQL编上,尽量减少读放大的问题。对于多表join在Radon上限制有两个限制配置:总共行数不能超过< max-join-rows: 32768 ,结果集大小不能超过< max-result-size:1073741824
对于single table, global table建议物理大小不超过5G,单表行数在1千万以下。
从拆分的角度理解MySQL最佳实践中表的总数量,例如,我们约定一个MySQL实例上可以放500个表,Radon默认分区64个,如果只有一个Backend的情况下,建议该节点最多可以放8个分区表,需要在多的分区表时,建议扩展新的backend。
RadonDB SQL限制:
目前RadonDB中,为性能和安全,约束还比较多。在本次测试中遇到的,限制如下:
Radon中SQL区分大小写,如 select * from tb1 where id=XX 和select * from tb1 where ID=XX 和后面表的结构定义的字段非常敏感。如果后面表tb1的字段定义成:ID,则 id=XX 会拆分成和后端分表数量一致的多条SQL执行, 而ID=XX,可以明确计算出来属于那张表进行计算。这个从Radon好修复,大概了解就可以。
分区表不支持外键 (点赞)
分区表不支持联合主键
不支持lock table/unlock table操作
join查询不能使用 select * ,需要明确字段,和官方交流后,该功能已经修复。
不支持insert into c1(id, c1, c2) select id,c1,c2 from c limit 10;
delete 和update必须带where条件
Radon对MySQL的一些函数支持不够友好
... 估计使用还会遇到,欢迎总结 :)
总结
Radon从开发和设计上都比较轻量,从整体使用上考,Radon在设计上对于安全和性能,准确性要求比较高。这个可能和青云把RadonDB定位在金融环境的中间件有关系。大家有兴趣可以去尝试使用,如果遇到问题,也可以第一时间在 https://github.com/radondb/radon/issues 提交问题,Radon开发团队目前响应比较快,欢迎尝试。
想加入专业Radon讨论群,添加作者,留言:RadonDB

