





TroubleShooting wait for table flush

事件说明:
2019年01月20日下午在备份归档库进行逻辑导入期间,
show process list
发现数据库后台存在大量waiting for table flush等待事件,对应其他session做登录操作,及其查询操作被阻塞,通过kill thread id方式解决该问题。
对于该等待事件,mysql5.7版本官方描述为:
The thread is executing FLUSH TABLES and is waiting for all threads to close their tables, or the thread got a notification that the underlying structure for a table has changed and it needs to reopen the table to get the new structure. However, to reopen the table, it must wait until all other threads have closed the table in question.
This notification takes place if another thread has used FLUSH TABLES or one of the following statements on the table in question: FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE, or OPTIMIZE TABLE.


工作原理对应指标分析:
mysql如何flush table
>FLUSH TABLES是强制关闭所有表。这主要是为了确保如果有人在MySQL之外添加一个新表(例如,通过将文件复制到数据库目录中cp),所有线程将开始使用新表。这
也将确保所有表更改都刷新到磁盘
>执行a时FLUSH TABLES,变量 refresh_version会递增。每次线程释放一个表时,它都会检查表的刷新版本(在打开时更新)是否与当前相同 refresh_version。如果没有,它将关闭它并在其上广播一个信号
COND_refresh
>在线程获得对表的锁定之后 ,当前refresh_version也与open相比较refresh_version。如果刷新版本不同,则线程将释放所有锁,重新打开表并尝试再次获取锁。这只是为了快速让所有表使用最新版本。这是由sql/lock.cc::mysql_lock_tables()和 处理 sql/sql_base.cc::wait_for_tables()。
>当所有表都关闭后,FLUSH TABLES返回给客户端。
>如果正在执行的线程FLUSH TABLES 对某些表有锁定,它将首先关闭锁定的表,然后等待所有其他线程也关闭它们,然后重新打开它们并获取锁定。在此之后,它将为其他线程提供打开相同表的机会。
问题复现实验:
首先执行mysqldump-h exbellmysql.clustercvkirmoyjqm9.ap-northeast-1.rds.amazonaws.com-uexbelltech-pexbell2018 proarch t_account_action-e
--max_allowed_packet=4194304--net_buffer_length=16384 --skip-lock-tables >/DB/data/t_account_action.sql逻辑备份。

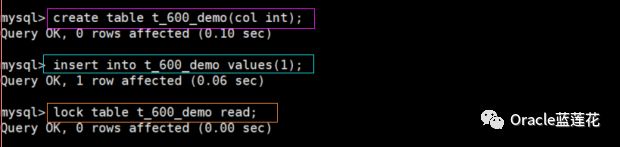
首先创建测试表,插入测试数据,对当前测试表进行lock操作,同时记录thread id为753。
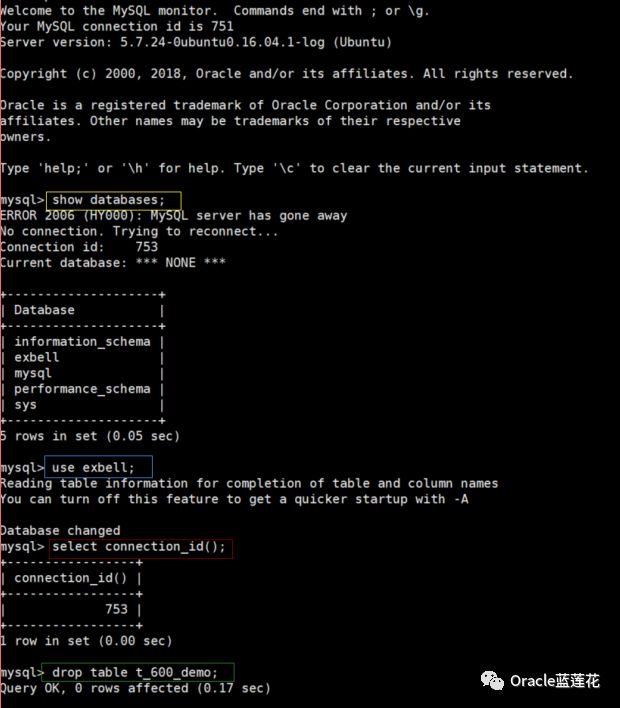
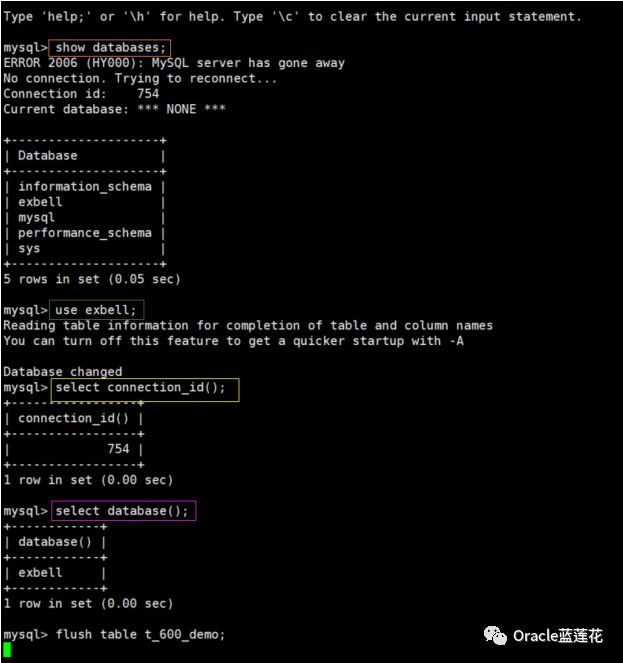
新开一个会话,记录thread id为754,然后对刚才新建立的测试表执行flush table t_600_demo 操作,此时会话754 hang住,并且处于阻塞状态。
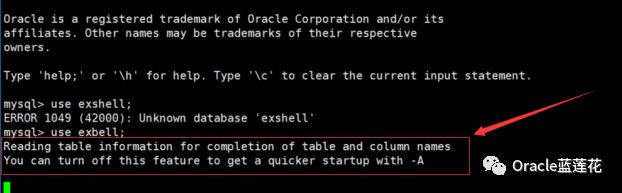
新开第三个会话,当尝试use exbell切换数据库时候提示Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with A,切换期间处于阻塞状态。
我们使用mysql A uroot p方式登录,不预读mysql数据库方式登录,这种方式类似oracle的sqlplus prelim as sysdba方式,只不过prelim参数更多是为了捕获挂起数据库的自动会话历史记录,注意下面截图,当我们尝试查询测试表,仍然处于阻塞状态。
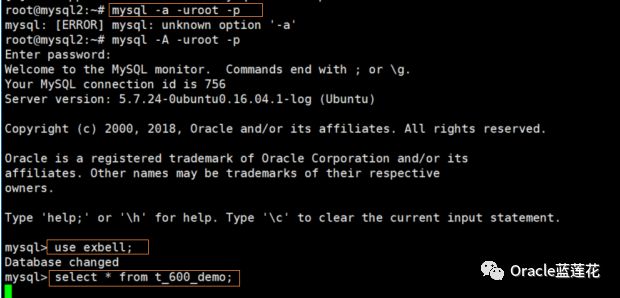
注意,我们在开一个会话,使用show full processlist方式查看当前进程发现754 755 756thread id都处于wait for table flush状态。
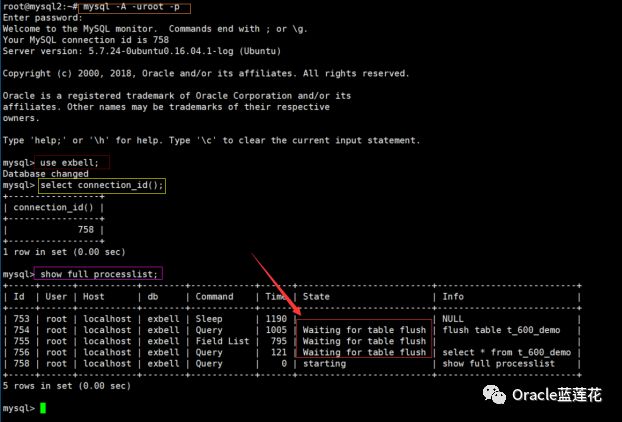
我们尝试在新会话验证需要open table的表,同时kill掉flush table操作的进程号。

注意,上一步的操作,只是一个示范,我们kill掉flush table的进程是无法解决问题的,因为日常生产环境很多时候可能不是lock table read造成的阻塞,并发insert导致的索引独占锁,慢查询等都会导致flush table一直无法关闭该表而一直处于等待状态。,下面的截图可以清晰的看到,对应756号进程阻塞仍然没有被释放。
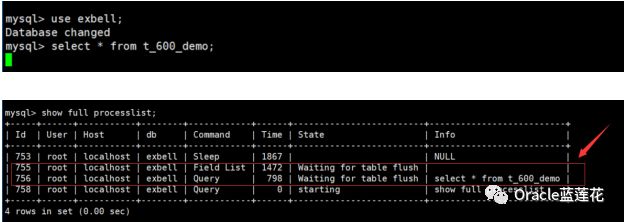
其实问题本质在于mysqldump备份时,如果没有使用参数—singletransaction 或由于同时使用了flush-logs与—single-transaction两个参数是会引起这样的等待场景,这个两个参数放在一起,会在开始dump数据之前先执行一个FLUSH TABLES操作。这正是我们的案例中由于使用了flush-logs和single_transactioncan导致的flush table行为。
解决办法:
出现Waiting for table flush时,我们一般需要找到那些表被lock住或那些慢查询导致flush table一直在等待而无法关闭该表。然后Kill掉对应的线程即可,但是如何精准定位是一个挑战,尤其是生产环境,你使用show processlist会看到大量的线程。让你眼花缭乱的,怎么一下子定位问题呢?
对于慢查询引起的其它线程处于Waiting for table flush状态的情形
可以查看show processlist中Time值很大的线程。然后甄别确认后Kill掉,如上截图所示,会话连接14就是引起阻塞的源头SQL。有种规律就是这个线程的Time列值必定比被阻塞的线程要高。这个就能过滤很多记录对于lock table read引起的其它线程处于Waiting for table flush状态的情形对于实验中使用lock table read这种情况,这种会话可能处于Sleep状态,而且它也不会出现在show engine innodb status \G命令的输出信息中。 即使showopen tables where in_use >=1;能找到是那张表被lock住了,但是无法定位到具体
的线程(连接),其实这个是一个头痛的问题。但是inntop和mytop等工具可以帮助我们定位,innotop就类似oracle的oratop,界面几乎一样。

再看一个场景:线程758查询表执行sleep休眠操作,同时另一个线程761执行收集统计信息操作,此时761 hang住
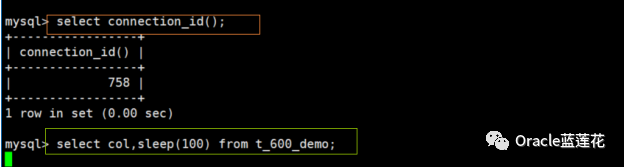
此时,我们再一次验证processlist,会发现wait flush table等待事件
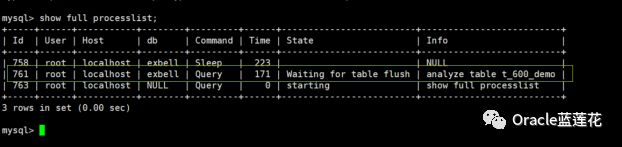
这个案例告诉我们,慢查询同样也会引起wait for flush table的等待事件。



