




引言
唐代有个著名的文学家、也是哲学家,名字叫韩愈字退之,贞元八年(792年),韩愈登进士第,两任节度推官,累官监察御史。后因论事而被贬阳山,历都官员
外郎、史馆修撰、中书舍人等职。元和十二年(817年),出任宰相裴度的行军司马,参与讨平“淮西之乱”。其后又因谏迎佛骨一事被贬至潮州。晚年官至吏部侍
郎,人称“韩吏部”。
在韩愈《进学解》中有这样一句话:“障百川而东之,回狂澜于既倒。”比喻尽力挽回危险的局势并且扭转乾坤、反败为胜。是的,今天要和大家分享的一个
Oracle参数DB_FILE_MULTIBLOCK_READ_COUN

DB_FILE_MULTIBLOCK_READ_COUNT

1. DB_FILE_MULTIBLOCK_READ_COUNT如何控制 oracle cbo优化器行为:
1.1DB_FILE_MULTIBLOCK_READ_COUNT 是可用于在表扫描或索引快速完全扫描过程中最大程度减少 I/O 次数的参数之一。该参数指定在一次顺序扫描过程中,一次 I/O 操作的最大块读取数。执行全表扫描或索引快速完全扫描所需的 I/O 总数取决于多种因素,如段的大小、多块读取计数以及是否对操作使用了并行执行。从 Oracle Database 10gR2 开始,此参数的默认值对应于可高效执行的最大 I/O 大小。此值与平台相关,在多数平台上为 1 MB。
1.2由于参数用块表示,因此系统会自动计算一个值,该值等于可高效执行的最大 I/O 大小除以标准块大小。请注意,如果会话数量极大,则会减少多块读取计数值,以避免缓冲区高速缓存中充斥太多表扫描缓冲区。即使默认值较大,但如果不设置此参数,优化程序也不会倾向于选择大型计划。仅当将此参数显式设置为一个较大值时,优化程序才会选择大型计划。一般情况下,如果不显式设置此参数(或设置为 0),则在计算全表扫描和索引快速完全扫描的成本时,优化程序将使用默认值 8。对于联机事务处理 (OLTP) 和批处理环境,此参数的值通常在 4 到 16 这个范围内。对于 DSS 和数据仓库环境,此参数的值越 大越好。如果此参数的值很大,则优化程序就更有可能选择全表扫描,而不选择索引。
1.3某些参数的设置可能会影响索引的使用。比如在大多数情况下都建议使用DB_FILE_MULTIBLOCK_READ_COUNT 和 OPTIMIZER_INDEX_COST_ADJ 的默认值。除非某 些特定的操作有特定的建议,使用其它值会使索引的成本不现实的减少或变大从而极大的降低查询的性能。

2.表统计信息DBA_TAB_STATISTICS层面:
2.1NUM_ROWS
这是基数计算的基础。如果表是嵌套循环联接的驱动表,则行计数尤为重要,因为它定义了内部表被探测多少次。
2.2BLOCKS
已使用数据块的数量。块计数与DB_FILE_MULTIBLOCK_READ_COUNT 组合在一起给出了基表访问成本。
2.3EMPTY_BLOCKS
表中空的(从未使用的)数据块数量。这是已使用数据块和高水位标记之间的块。
2.4AVG_SPACE
分配给表的数据块中空闲空间的平均数量(以字节为单位)。
2.5CHAIN_CNT
这是表中从一个数据块链接到另一个数据块、或者移植到了新块,且需要用链接来保留原有 ROWID 的行的数量。
2.6AVG_ROW_LEN
表中行的平均长度(以字节为单位)。
2.7STALE_STATS
指明统计信息在相应表中是否有效

3.深入分析:
3.1一个表上的完整扫描操作读取一个I/O中的多个块,而不是每次只读取一个I/O中的一个块。在一个多块I/O中读取的块数量可以从b_file_multiblock_read_count
参数中指定的块数量不等。例如,如果将参数设置为64,并且表中有640个块,则最小值为number of I/O需要得到所有块= 640/64 = 10
注意:由于对多块读调用有以下限制,I/O的可能不止一个:
3.1.1.多块读取不能跨越范围边界,例如。如果db_file_multiblock_read_count = 64和区段大小= 8block,那么多块读取最多只能在一个I/O中读取8blocks
3.1.2.如果请求的块已经在缓冲区缓存中,它将不会作为多块读取的一部分再次被读取。Oracle会简单地将这些块读到内存中还没有的地方,然后发出另一个read调用,跳过这些块来读取剩下的部分,假设db_file_multiblock_read_count = 64和要读取的块的范围在1号块和64号块之间。如果没有。32已经在缓冲区缓存中可用,第一次对block 1到31进行多块读读,然后从block 33读到block 64读
3.1.3.多块读取不能超过操作系统对多块读取大小的限制
3.2来看一个工作原理分析的猜想:
3.2.1 已知block大小为8K :

3.2.2 然后我们设置
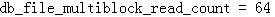
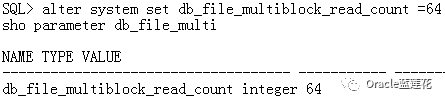
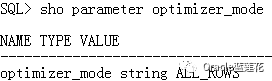
3.2.3 验证一下优化器环境:
3.2.4 创建表空间,区段大小分别为 64K 512K 1024K

3.2.5创建三张堆组织表,
表t_demo_64k在tbs_oracle_64k中,其中uniform extent size = 8 blocks
表t_demo_512k在tbs_oracle_512k中,其中uniform extent size = 64 blocks
表t_demo_1024k在tbs_oracle_1024k中,其中uniform extent size = 128 blocks

3.2.6收集统计信息:

3.2.7确定段区分配信息:
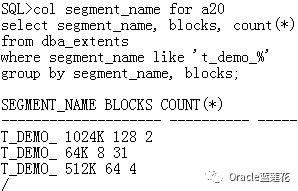
3.2.8确定表的object_id:
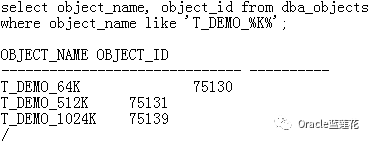
3.2.9我们完成全表扫描,并通过monitor方式进行跟踪:

3.2.10确定trace文件地址:

4.trace文件分析:
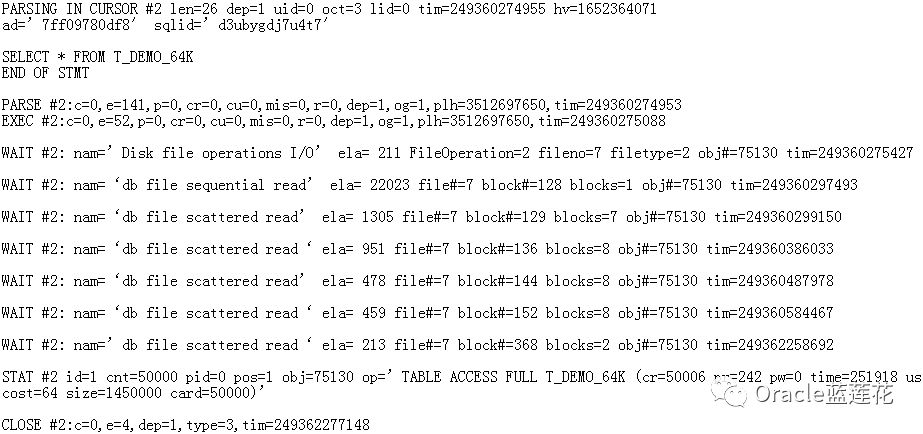
4.1表t_demo_64k

4.2具体等待:
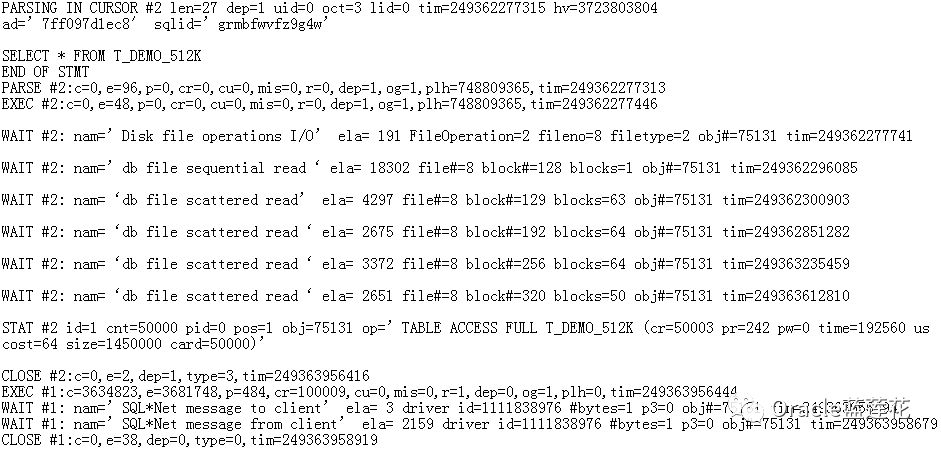
4.3表t_demo_512k

4.4T_DEMO_512K表的等待事件
4.5T_DEMO_1024K (object_id = 75139)
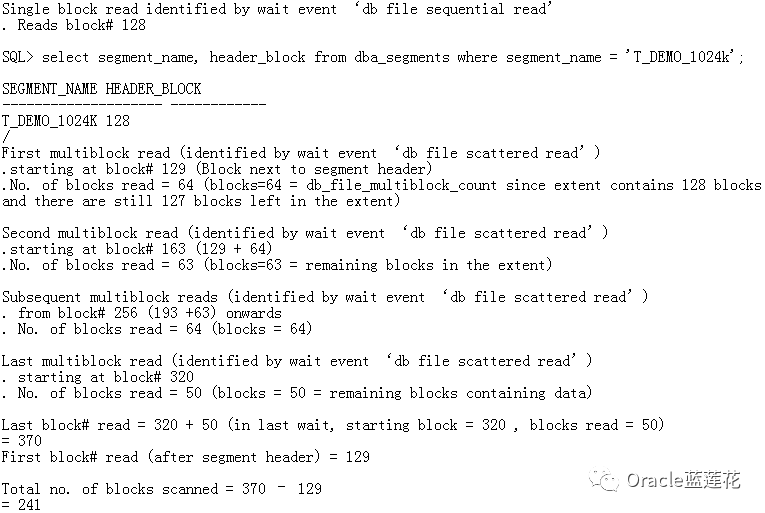
4.6T_DEMO_1024K等待事件
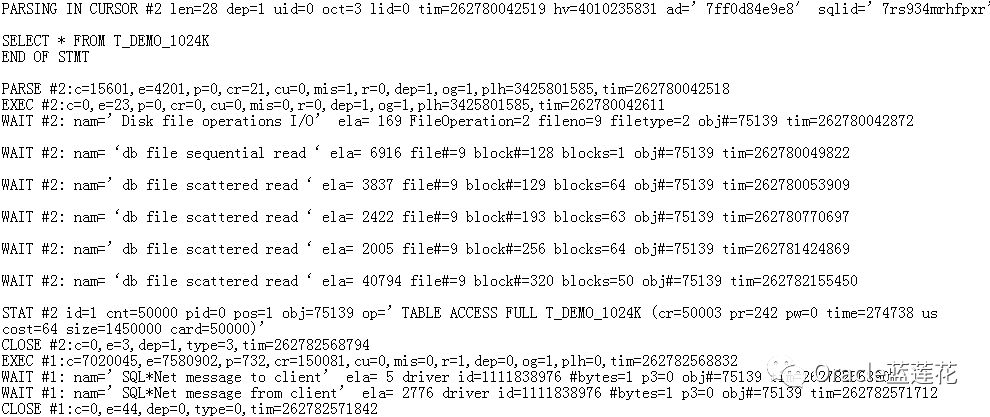
5.分析结果:
5.1 在FTS中,segment header是使用单块读取来获取区段映射的。
5.2 在第一次多块读取时,如果区段db_file_multiblock_read_count中的剩余块读取第一个区段中的剩余块(不包括分段头信息块)。否则(>范围内
剩余块= db_file_multiblock_read_count,
读取blocks = db_file_multiblock_read_count
5.3 在随后的多块读取期间,如果区段db_file_multiblock_read_count中的剩余块,读取范围中的其余块。否则(>范围内
剩余块= db_file_multiblock_read_count,
读取blocks = db_file_multiblock_read_count
5.4 在最后一次多块读取期间,将读取包含数据的其余块。如果区段大小<= db_file_multiblock_read_count
那么number of blocks 读取单个 I/O = number of blocks 的一个extent
5.5 如果区段大小> db_file_multiblock_read_count
那么number of blocks read 读取单个 I/O = least (db_file_multiblock_read_count, number of blocks containing data)
5.6 因此结论是多快读参数是不能够跨区段的。

