





导读
编译器类别
在java中编译器主要分为三类:
前端编译器:JDK的Javac,即把*.java文件转变成*.class文件的过程
即时编译器:HotSpot虚拟机的C1,C2编译器,Graal编译器,JVM运行期把字节码转变成本地机器码的过程
提前编译器:JDK的Jaotc,GNU Compiler for the Java(GCJ)等
编译器执行过程
前端编译
java的编译过程首先由javac将.java文件编译为字节码,这部分通常叫做前端编译
编译过程大概分为1个准备过程和3个处理过程,最终会将代码编译为字节码
即时编译
在jvm运行时期,方法被执行前会先检测当前方法是否已经被编译为机器码,如果编译为机器码将直接从CodeCache中获取机器码执行
如果没有编译为机器码,则会进行代码的热点探测,没有达到热点代码的阈值时则由解释器执行。达到阈值时则判断是否为同步编译
同步编译则需要等待jvm将当前热点代码编译为机器码后才能执行
异步编译则本次热点代码由解释器执行,异步的在后台编译机器码
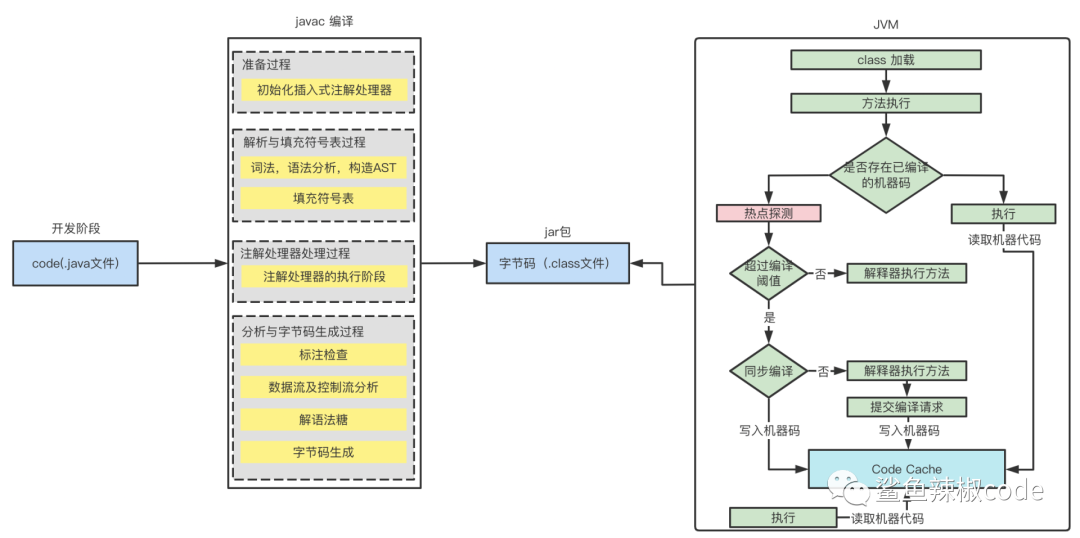
即时编译
解释器和编译器
即时编译器(JIT)
即时编译器类型
客户端编译器(Client Compiler)
服务端编译器(Server Compiler)
分层编译器(Tiered Compiler)
Java 8 默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数 -client 和 -server 都是无效的。当关闭分层编译的情况下,Java 虚拟机将直接采用C2。
0. 解释执行;
1. 执行不带 profiling 的 C1 代码;
2. 执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 代码;
3. 执行带所有 profiling 的 C1 代码;
4. 执行 C2 代码。
编译路径:
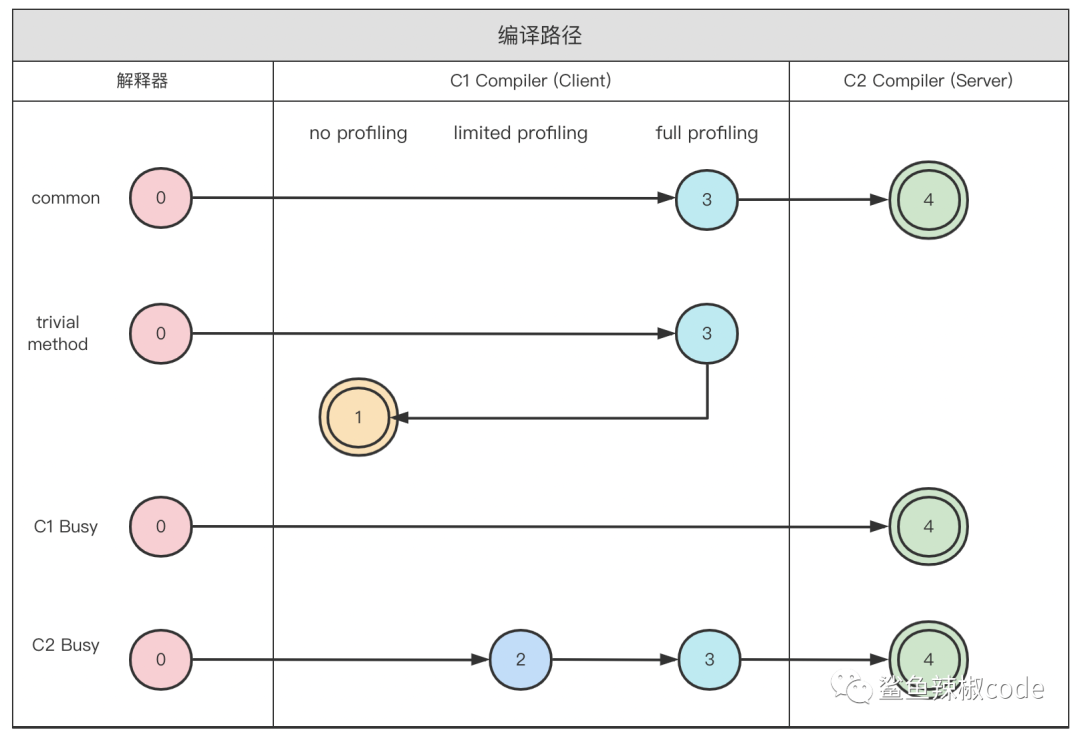
common:通常情况下热点方法会被3层的C1编译,然后再被4层的C2编译
trivial method:如果方法的字节码数目比较少,例如get set方法,而且3层的profiling没有可收集的数据,那么虚拟机会认为该方法使用C1和C2编译的效果相同,在这种情况下Java虚拟机会在3层编译后,选择1层的C1编译
C1 Busy:在C1编译器处于忙碌状态时(C1 Compiler Thread),直接由4层的C2进行编译
C2 Busy:在C2编译器处于忙碌状态时 (C2 Compiler Thread),则由2层的C1编译器编译,然后再被3层的C1编译,减少方法在3层的执行时间。
即时编译的触发
热点代码
触发阈值
s = queue_size_X (TierXLoadFeedback * compiler_count_X) + 1其中 X 是执行层次,可取 3 或者 4;queue_size_X 是执行层次为 X 的待编译方法的数目;TierXLoadFeedback 是预设好的参数,其中 Tier3LoadFeedback 为 5,Tier4LoadFeedback 为 3;compiler_count_X 是层次 X 的编译线程数目。
编译器优化技术
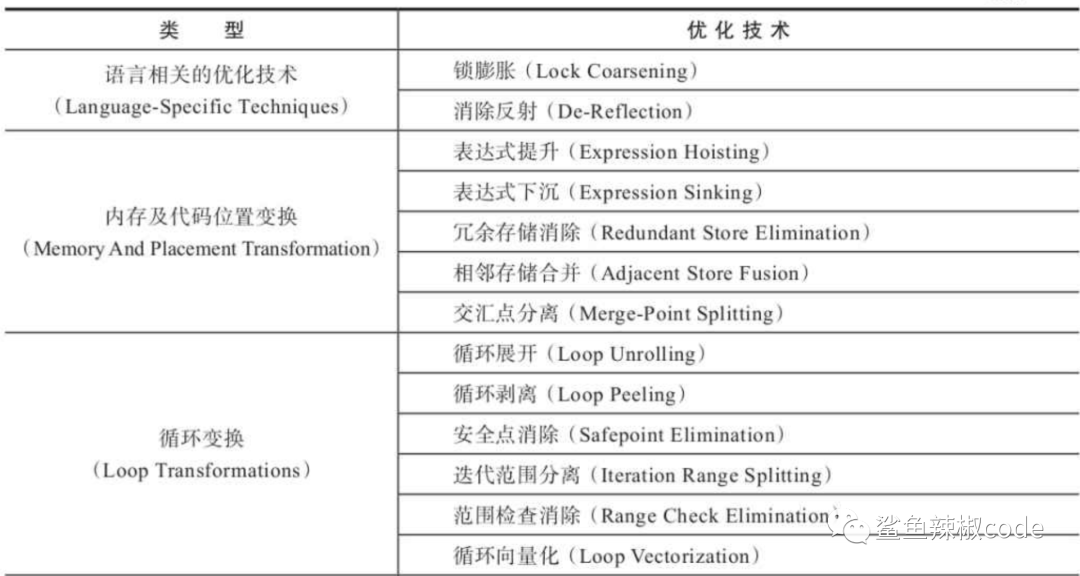
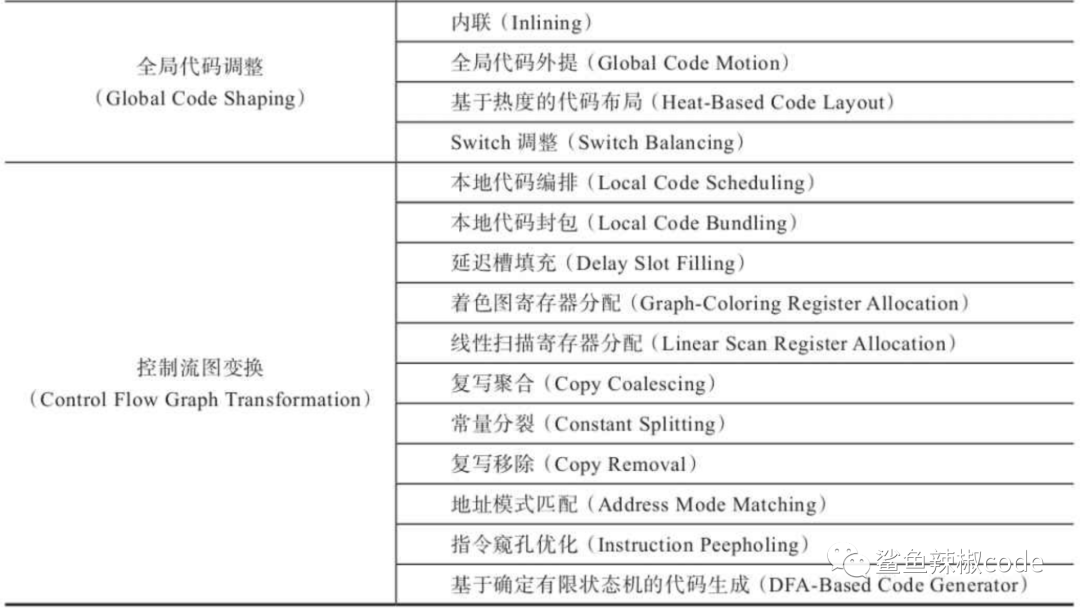
优化的技术点很多,我们重点关注下面几项优化技术:
最重要的优化技术之一:方法内联。
最前沿的优化技术之一:逃逸分析。
语言无关的经典优化技术之一:公共子表达式消除。
方法内联
优化前的原始代码:
static class B {int value;final int get() {return value;}}public void foo() {y = b.get();// ...do stuff...z = b.get();sum = y + z;}
内联后的代码:
public void foo() {y = b.value;// ...do stuff...z = b.value;sum = y + z;}
逃逸分析
逃逸状态:
全局逃逸:一个对象的作用范围逃出了当前方法或当前线程
对象是一个静态变量
对象已经发生逃逸
对象作为当前方法的返回值
参数逃逸:一个对象被作为方法参数传递或者被参数引用,但在调用过程中不会发生全局逃逸,这个状态是通过被调方法的字节码确定的
没有逃逸:方法中的对象没有发生逃逸
优化手段:
栈上分配
当对象没有发生逃逸时,该对象就可以通过标量替换分解成成员标量分配在栈内存中,和方法的生命周期一致,随着栈帧出栈时销毁,减少了 GC 压力,提高了应用程序性能。
标量替换
首先要了解标量和聚合量的区别,标量是指:虚拟机中的原始数据类型(int ,long等),聚合量:例如java中的对象。标量替换的过程是:把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量 恢复为原始类型来访问.
假如逃逸分析出对象可以在栈上分配,并且这个对象可以被拆散,那么程序真正执行时可能不会去创建这个对象
同步消除(锁消除)
线程同步本身是一个相对耗时的动作,如果逃逸分析能够确定变量不会逃逸出当前线程,那么这个变量的读写就不会有竞争,对这个变量的同步措施就可以消除掉
使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析,开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数 - XX:+EliminateAllocations 来开启标量替换,使用 +XX:+EliminateLocks来开启同步消除 , 使用参数 -XX:+PrintEliminateAllocations 查看标量的替换情况
公共子表达式消除
假设存在如下代码:
int d = (c * b) * 12 + a + (a + b * c);
int d = E * 12 + a + (a + E);
即时编译实战
此章节将介绍如何查看以及分析编译结果
PrintCompilation
测试代码:
package com.example.didilog;public class Compiler {public static final int NUM = 15000;public static int doubleValue(int i) {这个空循环用于后面演示JIT代码优化过程for (int j = 0; j < 100000; j++) ;return i * 2;}public static long calcSum() {long sum = 0;for (int i = 1; i <= 100; i++) {sum += doubleValue(i);}return sum;}public static void main(String[] args) {for (int i = 0; i < NUM; i++) {calcSum();}}}
通过-XX:+PrintCompilation参数打印在即时编译时被编译成本地机器码的方法
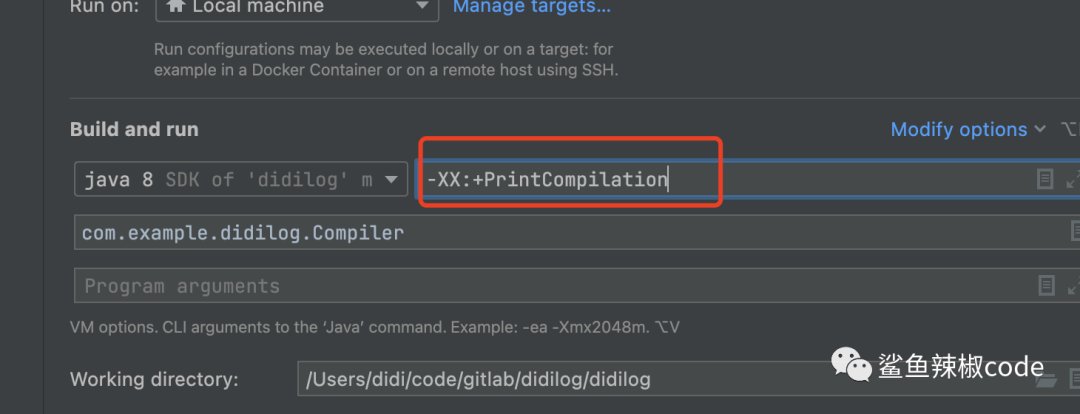
输出的结果:
参数说明:
timestamp:编译完成时间戳
compilation_id:jvm内部任务ID
attributes:编译状态
%:编译为OSR(回边计数器触发的栈上替换编译)
s:方法是同步的
!:方法有异常处理器
b:阻塞模式时发生的编译
n:为封装本地方法所发生的编译
tiered_level:分层编译使用的层级
method_name:编译的方法明
size:编译后的代码大小,java字节码的大小

jstat
使用jstat运行时观察即时编译信息
jstat -compiler 74293 #74293java进程Compiled Failed Invalid Time FailedType FailedMethod3107 0 0 1.15 0
使用-printcompilation参数获取最近被编译的方法,可以定时输出,如下每秒输出一次:
jstat -printcompilation 74293 1000Compiled Size Type Method3131 195 1 java/util/concurrent/ScheduledThreadPoolExecutor reExecutePeriodic3131 195 1 java/util/concurrent/ScheduledThreadPoolExecutor reExecutePeriodic3131 195 1 java/util/concurrent/ScheduledThreadPoolExecutor reExecutePeriodic
在查看编译日志时,如果遇到类似下面的这行信息的错误:
timestamp compile_id COMPILE SKIPPED: reason出现这个错误时有可能是两种原因:
代码缓存(code cache)满了:需要使用ReservedCodeCache标志增加代码缓存的大小
编译的同时加载类:编译类的时候会发生修改,JVM之后会再次编译
即时编译调优
如何选择编译器
简单来说client编译器启动快,server编译器性能更好,而分层编译降低了开发和运维的心智,结合了client和server编译器的优点,java8默认开启了分层编译。以java8 HotSpot举例如果要手动指定编译器类型,需要使用TieredCompilation 参数关闭分层编译。
指定client编译器
-XX:-TieredCompilation -client
指定server编译器
-XX:-TieredCompilation -server
调优代码缓存
JVM生成的native code存放的内存空间称之为Code Cache;JIT编译、JNI等都会编译代码到native code,其中JIT生成的native code占用了Code Cache的绝大部分空间如下图:code cache属于堆外内存
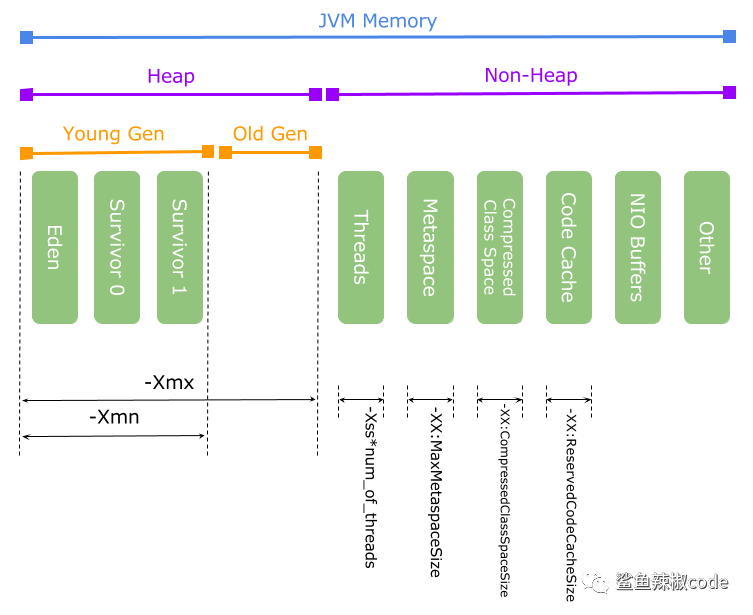
通过-XX:ReservedCodeCacheSize指定最大值,通常默认240M通过-XX:InitialCodeCacheSize指定初始值通过-XX:+PrintCodeCache 可以查看CodeCache的使用情况(在启动时增加,在jvm关闭时会打印使用情况)
当CodeCache被填满时,会打印如下错误:

当遇到这个错误时只需要将-XX:ReservedCodeCacheSize调大一点,一般建议调大
1-3倍即可,各平台上CodeCache默认大小:
JVM类型 | CodeCache大小 |
32位client Java8 | 32M |
32位server 分层编译 Java8 | 240M |
64位server 分层编译 Java8 | 240M |
CodeCache的回收时通过在启动参数上增加:-XX:+UseCodeCacheFlushing 启用回收。打开这个选项在JIT被关闭之前,也就是CodeCache装满之前,会在JIT关闭前做一次清理,删除一些CodeCache的代码;如果清理后还是没有空间,那么JIT依然会关闭。这个选项默认是关闭的。
编译阈值
未启用分层编译
使用-XX:CompilerThreshold参数设置编译阈值
client编译默认值时1500。server编译时默认值时10000,可以更改参数使其更早或更晚进行编译
OSR(回边计数器编译)阈值计算公式:
(CompileThreshold*((OnStackReplacePercentage-InterpreterProfilePercentage)/100))
所有编译器中:-XX:InterpreterProfilePercentage(解释器监控比率)默认值是33
在client编译器中-XX:OnStackReplacePercentage(OSR比率)默认值是933,所以在client编译器中回边计数需要达到13500
在server编译器中-XX:OnStackReplacePercentage(OSR比率)默认值是140,所以在server编译器中回边计数需要达到10700
启用分层编译
如文章中触发阈值章节中所讲,需要根据编译线程计算。分层编译中编译器C1和C2的默认线程数
CPU数量 | C1线程数 | C2线程数 |
1 | 1 | 1 |
2 | 1 | 1 |
4 | 1 | 2 |
8 | 1 | 2 |
16 | 2 | 6 |
32 | 3 | 7 |
64 | 4 | 8 |
128 | 4 | 10 |
对于CPU核心数充足的情况下,可以适当调大编译线程数,以此来加快即时编译的速度。
对于CPU核心数不足的情况下,可以适当减少编译咸亨数,以此来降低即时编译开启的线程,减少CPU的使用。
需要注意的是:如果在程序运行时,如果因为动态加载(classloader)导致触发及时编译,从而让CPU大幅度抖动,可以检查下-XX:CICompilerCount参数的设置。
查看方法:
jinfo -flag CICompilerCount 1503996 #1503996是目标java进程
异步编译
通过-XX:+BackgroundCompilation参数可以设置编译机器码的动作同步还是异步。默认是true(异步)。当设置为false时,执行该方法的代码将一直等到它确实被编译为机器码以后才会执行。用-Xbatch可以禁止后台编译
总结
Just-In-Time (JIT) 编译器是JVM运行时环境的一个重要组件,本文主要介绍了即时编译中的client,server以及分层编译器的原理以及优化手段。通过这些内容有助于对即时编译器加深理解,遇到相关问题时可以有效的分析和排查。
在即时编译器中除了经典的client以及server编译器还有新一代的编译器:Graal编译器,它集成了即时编译器和提前编译器的功能感兴趣的可以自行查阅。
参考
《深入理解Java虚拟机》周志明
《JAVA性能权威指南》Scott Oaks
《深入拆解Java虚拟机》 郑宇迪
基本功 | Java即时编译器原理解析及实践 https://tech.meituan.com/2020/10/22/java-jit-practice-in-meituan.html Graal VM https://www.graalvm.org/
