




背景
随着微服务架构广泛应用,当单个微服务处理的数据对其他微服务不可见时,很容易造成数据孤岛。数据库同步技术应用亦愈发广泛。
本文首先分别介绍JDBC、CDC两种数据库同步方技术的优缺点,然后继续探讨传统银行系统如何使用Kafka Connect保持多个应用程序/数据库同步数据的架构案例。
JDBC同步数据库到Kafka
JDBC连接器与Kafka Connect结合,使用定期SQL查询批量数据、进行数据转换(非必需),然后写入Kafka Topic。

优点:
无代码解决方案,设置配置文件即可;查询数据库数据支持重新格式化为AVRO、JSON或ProtoBuf;支持SQL table类型schema,注册到schema registry;
缺点:
无法查询大数据量级数据库(如:TB),对于线上OLTP数据库来说,无法接受;只能捕获数据库的当前状态,无法捕获changelog(如:先insert再update);无法捕获硬删除(数据已从数据库完全删除);源表数据类型与目标数据类型(Avro/Protobuf/JSON)没有精确的一对一映射,这种不匹配可能需要消费者进一步处理;给数据库带来额外的负载,对于生产环境的数据库也是无法接收的;
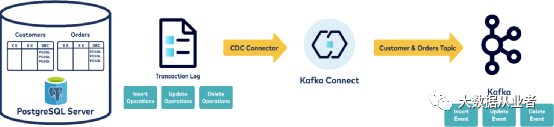
CDC同步数据库到Kafka
DBA通常不会允许Kafka Connect周期使用SQL查询数据库数据。尤其是生产数据库。CDC(Change Data Capture)与Kafka Connect可以配置为从数据库WAL(Write Ahead Log)文件以极低的延迟和低影响读取数据。
广义地说,就是关系数据库使用的事务日志(mysql binlog/oracle redo log),数据库的所有事件都会写入事务日志,包括insert、update、delete、DDL等等。
优点:
直接从WAL读取数据,不会造成数据库额外负载。可以捕获数据变更的所有事件(例如,插入、更新、删除、DDL等)。高效快速处理快照历史事件。
缺点:
与JDBC连接器相比,CDC工具的设置和监控更加复杂。考虑到实际需求,这种复杂性可能是值得的。成本考虑因素:许多CDC工具都是商业产品。
Kafka Connect与CDC实现数据库双活
经典案例说明:传统银行系统为满足客户需求架构体系不断迭代演进。其中,网上银行业务已经上线、交易数据存储在PostgreSQL数据库,但手机业务数据存储在其他数据库。
手机业务数据与网上银行业务数据如何打通公用呢?
最传统的方法可能是让银行系统在夜间运行离线ETL作业,以保持两个数据库同步。这种方法的缺点显而易见:
离线ETL作业仅每日夜间运行一次,很容易导致业务数据延迟高、用户体验差;如果要保持两个数据库双向同步,需要至少两个ETL作业。
使用Kafka Connect可以避免上述问题。上述业务架构如下:

如上图所示:使用Debezium CDC连接器从SQL Server和PostgreSQL这两个数据库提取数据,然后利用Sink将数据从各自的Topic写入到另一个数据库。注意:不同数据库数据类型并不完全相同,所以表具有相似(但不相同)的数据模型。
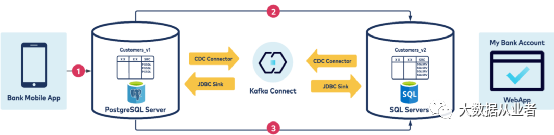
有相关经验的朋友会发现,这种双向数据库同步备份会出现无限循环现象(一条数据反复来回地在两个数据库之间同步)。
了解或者使用过Kafka Replicator、Kafka MirrorMaker做双活方案的朋友肯定遇到过这个问题。两者的解决方案有所不同:Kafka Replicator通过标记每条数据的来源、结合filter过滤器解决;而Kafka MirrorMakerV2版本则通过标记整个Topic来源来解决。
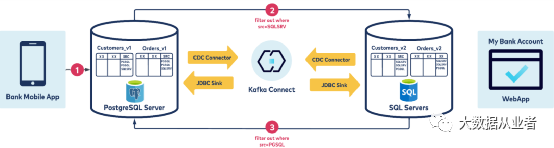
上图所示:使用filter过滤器可以避免无限循环现象,一条数据写入PGSql数据库、再同步到SqlServer数据库、不再同步回PGSql数据库。
详细描述如下:
1.手机银行App写入数据到PostgreSQL表的同时也插入一个SRC列、其值为PGSQL(表示该条数据来自于PostgreSQL)。2.Debezium CDC Source Connector for PostgreSQL配置exclusion过滤器SRC=SQLSRV,即排除从SQLServer同步过来的数据、只同步手机银行App写入的数据。而JDBC Sink Connector写入数据到SQLServer同时设置SRC=PGSQL。3.同样的道理, CDC SQLServer connector配置exclusion过滤器SRC=PGSQL,即排除从PostgreSQL同步过来的数据、只同步WebAp写入的数据。而JDBC Sink Connector写入数据到PostgreSQLServer同时设置SRC=SQLSRV。
综上所述,PostgreSQL数据库和SQLServer数据库完成双向数据同步,传统银行系统可达到手机银行App和WebApp数据共享的效果。
