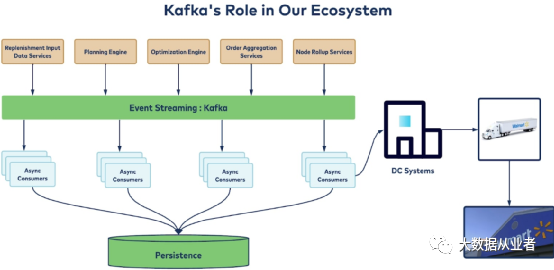
沃尔玛业务遍布全球、拥有很多零售店,加上其强大且快速增长的电子商务业务,使其成为全球库存管理最具挑战性的零售公司之一。面对消费者快速变化的购买行为和购买意向,实时库存清算、实时补货必不可少。 所谓实时补货,抽象一点就是供应链网络中每个站点满足库存需求的方式。沃尔玛为了优化资源配置和提高消费者满意度,一旦遇到库存低于某个阈值的情况,就需要结合当前供应链网络的实际影响因素(如销售预测、安全库存、站点可用性)自动补充该项库存。 沃尔玛不仅有很多实体店还拥有数百个不同类型的配送中心(DC),所以准确、可靠、实时的补货是一项非常有挑战性的工作。而Apache Kafka®是实现这一切的复杂IT架构的重要组成部分。 沃尔玛的运营规模和复杂性造就它的实时补货具有独特的挑战性:周期短:尽可能缩短订单发出和库存到达商店之间的时间。平台需要结合供应商供货时间和配送中心提货时间,在极短的规定时间内为大量SKU(StockKeepingUnit,即库存进出计量的基本单元)制定调度计划。
准确性:随着客户需求越来越精细化,库存质量和数量的准确性变得越来越重要。不能交付客户不需要的商品(既占用商店空间也不能满足需求),需要确保在正确的时间交付正确数量的商品。
速度:需要优化供应链,使其尽可能高效。需要充分利用每个配送中心的每次配送行程,这就意味着根据计划处理订单的时间非常有限。在很短的时间内准确运行和构建大量SKU的订单计划面临着独特的挑战,这要求平台的每个部分(包括虚拟机(VM)、Kafka、数据库、网络)都需要以最佳速度运行。
降低复杂性:需要确保平台的高性能和架构简洁,以便能够快速迭代添加功能以响应新的供应链需求、在出现任何系统和功能问题时进行快速调试和分析。
弹性和可扩展性:鉴于数据规模不断增长,功能需求不断变化,平台需要以最佳成本快速满足新需求。
恢复能力:在规模、数据和处理时间的敏感性方面,当部分或全部平台没有响应或速度慢,影响SLA时,平台具有必要的故障切换和恢复能力是极其重要的。
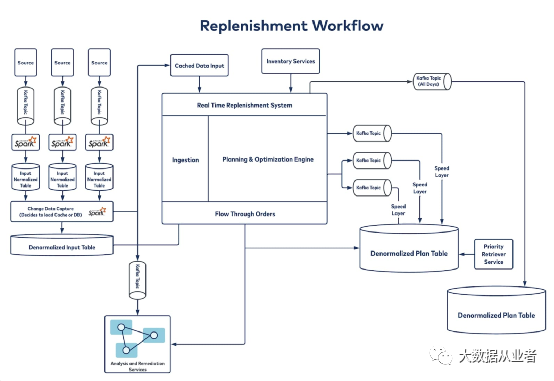
在满足不断变化的客户行为的同时,实现上述所有系统和平台架构需求并非易事。下图简单展示沃尔玛当前业务规模: 沃尔玛的实时补货系统每天都要在三个小时内处理近1亿SKU数百亿条信息,为所有沃尔玛商店生成高精确度订单计划,吞吐量高达85GB消息/分钟。同时还要确保通过事件跟踪、数据重放、重试等方法做到不会丢失数据。 如上图实时补货工作流可以看出,计算框架使用微批处理架构Spark,数据源输入到Kafka,经过Spark处理后进入到非规范化视图(Denormalized Input Table),以便随时快速访问。实时补货系统中的计划引擎对数据进行处理,涉及库存位置、预测、库存阈值、配送中心、商店、配送方法等信息。以上工作都是每天处理近1亿SKU的3小时内完成的。然后通过不同层级的Kafka Topic发布整个实时补货计划。目前沃尔玛Kafka集群有18个Broker、20多个Topic,每个Topic都有500多个分区。 该文介绍了沃尔玛使用Kafka构建实时补货业务场景的相关内容。沃尔玛作为世界上最大的零售商,实时补货在满足数百万在线和非预约客户的需求方面发挥着关键作用,通过使用Kafka及其生态系统确保了所需库存的及时性和可用性。