





文章转载自公众号:PostgreSQL学徒
作者:熊灿灿
比较PostgreSQL中的负载均衡
负载均衡可以提升系统的性能,从应用的角度来看,多台计算机提供含有相同数据的服务。它的工作方式是,将客户端的查询分配给除其主节点或主节点之外的副本节点,同时将数据库修改仅路由到主节点。对主节点的任何修改随后都会使用PostgreSQL流复制原理传播到每个副本。
负载均衡器如何影响PostgreSQL?
要使用负载均衡需引导客户端应用程序连接到负载均衡器,并根据查询请求的类型将发起的连接分发到可用的PostgreSQL节点。
这有助于缓解特定的PostgreSQL服务器上的负载压力,并使集群中可用节点之间的负载相对均衡。
基于PostgreSQL,目前已经有一些现有的解决方案。这些解决方案可以无缝运行,或者负载均衡可以与当前拓扑(主节点和备用节点)一起使用,但是负载均衡是在应用程序层本身中实现的。负载均衡面临许多同步问题的挑战,这是服务器之间协同工作的基础困难。因为没有单一的解决方案可以消除所有使用案例中的同步问题,所以有多种解决方案。每个解决方案都以不同的方式解决此问题,并最大程度地减少了对特定工作负载的影响。
在此博客中,我们将通过比较这些负载均衡器以及对PostgreSQL工作负载带来的好处。
PostgreSQL的HAProxy负载均衡
HAProxy是一个事件驱动的非阻塞引擎,将代理与速度非常快的I O层以及基于优先级的多线程调度器结合在一起。由于设计时以数据转发为目的,因此其体系架构设计为在轻量级过程中运行,该过程经过优化,可以以最少的操作尽可能快地移动数据。它着重于通过尽可能长时间地将连接保持在同一个CPU上以优化CPU的缓存效率。基于此,它实现了一个分层模型,该模型在每个级别都提供了旁路机制,以确保除非需要,否则数据不会达到更高的级别。大多数处理在内核中执行。HAProxy尽最大努力通过给出一些提示或避免某些可能在以后进行分组的操作来帮助内核尽可能快地完成工作。结果,典型数据显示,在HAProxy中花费的处理时间占15%,而在TCP或HTTP关闭模式下,内核花费的处理时间为85%,对于HAProxy,在HTTP保持活动模式下,HAProxy花费的处理时间为30%,而内核为70%。
HAProxy还具有其他功能如负载均衡。例如,TCP代理功能允许我们将其用于PostgreSQL连接,通过内置的检查服务。即使有数据库服务支持,它也不能满足所需的健康检查,特别是对于复制类型的集群。在生产环境中部署它的标准方法是使用TCP检查,然后依靠具有HAProxy的xinetd。
为PostgreSQL使用HAProxy的优点
HAProxy的最好之处在于其轻巧,易于配置和使用,并且可以按预期完成任务。在大型企业中,已经将HAProxy应用于PostgreSQL群集之上并已多次部署和部署到各种SME SMB以供生产使用。长期以来,它已经被证明可以用于生产和高负载容量中,所以不仅适用于数据库,而且适用于其他网络服务,如web应用程序或地理负载均衡(跨多个数据中心分发流量)。HAProxy位于PostgreSQL之上,它使用户能够限制或限制响应,以将负载并行化并正确分配给群集中的所有可用节点。HAProxy的内置机制还允许用户无缝设置高可用性,并且更易于扩展,并避免单点故障(SPOF)。
为PostgreSQL使用HAProxy的缺点
HAProxy不提供查询过滤,也不提供查询分析来识别所请求语句的类型。它缺乏在单个端口上执行读/写拆分的能力。在HAProxy之上设置负载均衡要求为读写操作设置不同的端口。这就需要更改应用程序以满足需求。
HAProxy仅为PostgreSQL提供了非常简单的功能支持以进行运行状况的检查,但这只能确定节点是否正常运行,就好比它只是对该节点执行ping操作并等待回应。它并不知道试图将连接转发到对应节点的相应角色。因此,HAProxy并不能理解或者说没有相应特性来理解复制的拓扑结构。尽管用户可以基于不同的端口创建单独的侦听器,但它仍然会在应用程序中进行更改,以满足负载均衡的需求。这意味着使用带有xinetd的外部脚本可以作为满足需求的解决方案。尽管如此,它还没有集成到HAProxy中,很容易出现人为错误。
如果必须将一个节点或一组节点置于维护模式下,那么还需要对HAProxy应用更改,否则可能是灾难性的。
PostgreSQL的Pgpool-II负载均衡
Pgpool-II是一种开源软件,已被庞大的PostgreSQL社区所采用,Pgpool-II实现了负载均衡,并使用它作为从应用程序到代理层的中间件,然后再分配负载(充分分析了每个查询或数据库连接的请求类型)。Pgpool-II自2003年以来已经存在了很长的时间,最初被命名为Pgpool,直到2006年成为Pgpool-II,这是一个非常稳定的代理工具,不仅仅用于负载均衡,而且还具有许多很酷的功能。
Pgpool-II被称为PostgreSQL的瑞士军刀,是位于PostgreSQL服务器和PostgreSQL数据库客户端之间的代理软件。Pgpool-II的基本思想是,它位于客户端上,然后读请求传递到备用节点,而写入或修改请求则直接到达主节点。Pgpool-II是一个非常智能的负载均衡解决方案,不仅可以实现负载均衡,而且还支持高可用并提供连接池。智能机制会在主从之间平衡负载。因此写操作被传到主服务器上,而读操作则被定向到可用的只读服务器上,又叫hot-standby。Pgpool-II还提供逻辑复制。尽管随着PostgreSQL内置复制选项的改进,它的使用和重要性降低了,但是对于旧版本的PostgreSQL来说,这仍然是一个有价值的选择。最重要的是,它还提供连接池。
为了支持Pgpool-II的所有功能,Pgpool-II具有比PgBouncer更为复杂的体系结构。虽然两者都支持连接池,但后者没有负载均衡的功能。
Pgpool-II可以管理多个PostgreSQL服务器。使用复制功能可以在2个或更多物理磁盘上创建实时备份,以便在磁盘出现故障的情况下无需停止服务器就可以继续服务。由于Pgpool-II也具有连接池功能,因此它可以限制超出的连接数。PostgreSQL的最大并发连接数是有限制的,超过这个数量的连接会被拒绝。但是,调整最大连接数会增加资源消耗并影响系统性能。Pgpool-II也对最大连接数有限制,但是额外的连接将被排队,而不是立即返回错误。
在负载均衡中,如果使用了数据库的复制特性,则在任何服务器上执行SELECT查询都会返回相同的结果。pgpool-II利用复制功能,通过在多个服务器之间分配SELECT查询来减少每台PostgreSQL服务器的负载,从而提高了系统的整体吞吐量。理想状态下,性能会与PostgreSQL服务器的数量成比例地线性提高。在有很多用户同时执行许多查询的情况下,负载均衡最有效。
使用并行查询功能,可以将数据划分到多个服务器上,这样一个查询可以在所有服务器上同时执行,减少总体执行时间。并行查询在搜索大规模数据时工作得最好。
为PostgreSQL使用Pgpool-II的优点
这是一个功能丰富的软件,不仅有负载均衡,还提供了连接池(另一个选择是PgBouncer)原生复制,联机恢复,内存查询缓存,自动故障转移以及通过看门狗实现的高可用。这个工具已经很老了,并且一直得到PostgreSQL社区的大量支持,所以解决问题寻求帮助并不难。当您在这里寻求问题时,文档是您的朋友,但在社区中搜索帮助并不困难,而且这个工具是开源的,所以只要您遵守BSD许可,您就可以自由使用它。
Pgpool-II也有SQL解析器。这意味着它能够准确解析sql并重写查询。这允许Pgpool-II根据查询请求提高并行度。
为PostgreSQL使用Pgpool-II的缺点
Pgpool-II没有提供节点fencing机制的STONITH (shoot the other node in the head)。当PostgreSQL服务器出现故障时,Pgpool-II会继续保持服务可用。Pgpool-II也同样可以是单点故障(SPOF)。一旦节点宕机,那么数据库连接和可用性就从那时开始停止。尽管可以通过Pgpool-II冗余并使用watchdog来协调多个Pgpool-II节点来解决这个问题,但这会增加额外的工作。
对于连接池而言,不幸的是,对于仅专注于连接池的用户而言,Pgpool-II不能很好地利用连接池,尤其是对于少数客户端而言。因为每个子进程都有其自己的池,并且无法控制哪个客户端连接到哪个子进程,所以在重用连接时需要碰运气。
PostgreSQL的JDBC负载均衡
JDBC是Java编程语言的应用程序编程接口(API),它定义了客户端如何访问数据库。它是Java Standard Edition平台的一部分,并提供查询和更新数据库中数据的方法,并且面向关系数据库。
PostgreSQL JDBC Driver(简称PgJDBC)允许Java程序使用标准的,独立于数据库的Java代码连接到PostgreSQL数据库。PgJDBC是用Pure Java(Type 4)编写的开源JDBC驱动程序,并以PostgreSQL本机网络协议进行通信。因此,驱动程序是独立于平台的。一旦编译,驱动程序就可以在任何系统上使用。
它无法与我们之前指出的负载均衡解决方案相提并论。因此,此工具是您的应用程序编程接口API,该API允许您从应用程序连接,需支持JDBC或至少具有与JDBC连接的适配器的任何一种编程语言。另一方面,它对Java应用程序更有利。
使用JDBC实现负载均衡是相对稚嫩的,但却可以完成这项工作。JDBC提供了连接参数,可以触发该工具提供的负载均衡机制:
ØtargetServerType:根据PostgreSQL服务器的定义,连接到特定状态的PG server。允许的值为any,primary,master(不推荐使用),slave(不推荐使用),secondary,preferredSlave和preferredSecondary。通过观察服务器是否允许写入来确定状态或角色。
ØhostRecheckSeconds:控制相关主机状态信息在JVM范围的全局高速缓存中缓存多长时间。默认值为10秒。
ØloadBalanceHosts:允许您配置是否始终尝试连接第一个主机(当设置为false时)还是随机选择连接(当设置为true时)
因此,loadBalanceHosts接受一个布尔值。loadBalanceHosts在其默认模式下被禁用,并且主机以给定的顺序连接。如果启用,则从一组合适的候选主机中随机选择主机。使用jdbc连接到数据库时的基本语法如下:
ljdbc:postgresql:database
ljdbc:postgresql:/
ljdbc:postgresql://host/database
ljdbc:postgresql://host/
ljdbc:postgresql://host:port/database
ljdbc:postgresql://host:port/
假设loadBalanceHosts为true,并且配置了如下:
jdbc:postgresql://host1:port1,host2:port2,host3:port3/database
这允许JDBC从一组合适的候选对象中随机选择。
为PostgreSQL使用PgJDBC的优点
不需要中间件或代理作为负载均衡器。所以可以带来的更多的性能提升,因为每个请求无需通过额外的“层”。如果您已经准备好应用程序并支持JDBC,那么这将是有利的,并且您不需要更多的中间件,尤其是在您的预算紧张并且只想限制专用于其唯一目的和功能的过程的情况下。与高流量和大量需求的应用程序不同,它可能需要代理服务器充当负载均衡器,并且可能需要额外的资源来正确处理对连接的高要求,这也对CPU和内存有需求。
为PostgreSQL使用PgJDBC的缺点
您必须为每个请求的连接设置代码。这是一个应用程序编程接口,这意味着要进行大量处理,尤其是如果您的应用程序非常需要将每个请求发送到适当的服务器时。另外没有高可用,自动伸缩,并且也有单点故障。
用libpq实现的包装器或工具实现PostgreSQL负载均衡?
Libpq 是为C语言开发者提供的关于PostgreSQL的接口。Libpq 由相关库函数组成,可以允许客户端程序通过将查询请求传递给 PostgreSQL后台服务器并接收这些查询返回的结果。同时,libpq 也是其它几个PostgreSQL应用程序接口的底层引擎,包括 C++,Perl,Python,Tcl和ECPG。因此,如果你使用这些包之一,libpq某些方面的行为将对你很重要。
libpq不会自动均衡负载,因此不应被视为负载均衡的解决方案。但是,如果列出的用于连接的前一个服务器失败,它仍然能够连接到下一个可用的服务器。例如,如果有两个可用的hot-standby节点,如果第一个节点太忙,在超时时间内无法响应,那么它将连接到给定连接中的下一个可用节点。这取决于您指定的会话属性类型。这取决于参数target_session_attrs。
参数target_session_attrs接受read-write,如果未指定,则为默认值。参数target_session_attrs的作用是,如果设置为read-write,则仅在连接期间接受读写事务的连接。成功建立连接后,将发送查询SHOW transaction_read_only。如果结果为on,则连接将关闭,这意味着该节点被标识为副本或不处理写入。如果在连接字符串中指定了多个主机,则将尝试其余所有服务器,就像连接尝试失败一样。此参数的默认值any,表示所有连接都是可接受的。尽管仅依靠target_session_attrs不足以实现负载均衡,但是您可以模拟循环方式。请参阅下面使用libpq的示例C代码
#include
#include
#include
#include
#include
#include
const char* _getRoundRobinConn() {
char* h[2];
h[0] = "dbname=node40 host=192.168.30.40,192.168.30.50";
h[1] = "dbname=node50 host=192.168.30.50,192.168.30.40";
time_t t;
//srand((unsigned)time(&t));
sleep(1.85);
srand((unsigned)time(NULL));
return h[rand() % 2];
}
void
_connect()
{
PGconn *conn;
PGresult *res;
char strConn[120];
snprintf(strConn, 1000, "user=dbapgadmin password=dbapgadmin %s target_session_attrs=any", _getRoundRobinConn());
//printf("\nstrConn value is: %s\n", strConn);
conn = PQconnectdb(strConn);
res = PQexec(conn, "SELECT current_database(), inet_client_addr();");
if ( PQresultStatus(res)==PGRES_TUPLES_OK )
{
printf("current_database = %s on %s\n", PQgetvalue(res, 0, 0),PQhost(conn));
} else {
printf("\nFailed... Message Code is: %d\n", PQresultStatus(res));
}
PQclear(res);
PQfinish(conn);
}
int main(void)
{
int i;
for (i=0 ; i<5 ; i++)
_connect();
return 0;
}
root@debnode4:/home/vagrant# gcc -I/usr/include/postgresql -L/usr/lib/postgresql/12/lib libpq_conn.c -lpq -o libpq_conn; ./libpq_conn
current_database = node40 on 192.168.30.40
current_database = node40 on 192.168.30.40
current_database = node50 on 192.168.30.50
current_database = node40 on 192.168.30.40
current_database = node50 on 192.168.30.50
请注意,如果节点.40(主节点)发生故障,只要target_session_attrs值为any,它将始终将连接定向到.50。
在这种情况下,您可以在libpq的帮助下自由地创建自己的文件。尽管依赖libpq和/或它的包装器的过程还太原始,不能说这可以提供理想的负载均衡机制,使其均匀分布到节点上。当然,这种方法和编码是可以改进的,但我们的想法是,这是免费和开源的,您可以在不依赖中间件的情况下进行编码,并自由地设计负载均衡工作方式。
为PostgreSQL使用libpq的优点
libpq库是用C编程语言构建的应用程序接口。然而,这个库已经被用各种语言作为包装器实现,这样程序员就可以使用他们喜欢的语言与PostgreSQL数据库通信。您可以使用自己喜欢的语言直接创建自己的应用程序,然后列出您想要发送查询的服务器,但只有在其他服务器出现故障或超时之后,才会将负载发送到您想要分发负载的可用节点。它可以在Python、Perl、PHP、Ruby、Tcl或Rust等语言中使用。
为PostgreSQL使用libpq的缺点
负载并行的实现并不完美,您必须根据代码编写自己的负载均衡机制。没有可以使用或自定义的配置,因为它只是在target_session_attrs参数的帮助下,作为PostgreSQL数据库的编程接口。
这意味着,在组合数据库连接时,需要在代码中将读连接连到备节点,将写连接连到主节点,所以要么是在你自己的应用中实现,或是必须创建自己的API来管理负载均衡。
从前端应用程序的角度来看,使用这种方法不需要或不依赖中间件作为后端数据库。当然,这是轻量级的,但是当在连接时发送服务器列表时,并不意味着负载已经被理解并均匀地发送,除非您必须为这种方法添加代码。这只会增加麻烦,然而,已经有现成的解决方案,所以为什么需要重新发明轮子呢?
结论
用PostgreSQ实现负载均衡可能会很困难,但要取决于您要处理的应用程序类型和成本。有时,对于高负载需求,它需要中间件充当代理,以便正确分配负载并监督其节点状态或运行状况。另一方面,它可能需要服务器资源,要么必须在专用服务器上运行它,要么需要额外的CPU和内存才能满足需求,这增加了成本。因此,还有一种简单的方法但很耗时,但可以将负载分配给您已经拥有的可用服务器。然而,这需要编程技能和对API功能的理解。
译后感
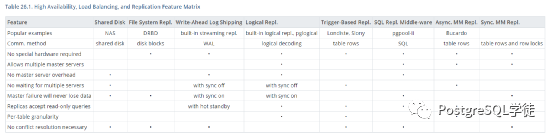
官网上这一块对各个方案做了一个简单的比较,High Availability, Load Balancing, and Replication Feature Matrix
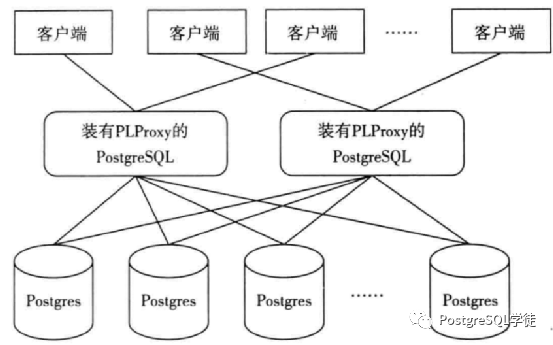
类似的,PL/Proxy中间件也可以实现类似的伪“负载均衡”
参考:
http://blog.itpub.net/6906/viewspace-2663949/
http://blog.itpub.net/6906/viewspace-2663949/
https://www.postgresql.org/docs/current/different-replication-solutions.html





新闻|Babelfish使PostgreSQL直接兼容SQL Server应用程序

更多新闻资讯,行业动态,技术热点,请关注中国PostgreSQL分会官方网站
http://www.postgresqlchina.com
中国PostgreSQL分会生态产品
http://www.pgfans.cn
中国PostgreSQL分会资源下载站
http://postgreshub.cn


点击此处阅读原文
↓↓↓
