




kafka消费者消费消息流程,目前只支持poll拉取的模式,而在消费者客户端获取消息的编码也非常简单,只需要简单的三步,即可完成对kafka消息的获取,对于使用者来说,单单从使用的角度,只需要处理业务上的一些异常信息即可,对于内部的原理无需关注,也可以将kafka运用到实际的业务中去,这与kafka一贯的思想也是相符的,即:封装复杂的流程,规避使用上的复杂性,提供简单易用的上层API给应用。
public Consumer(final String topic,final String groupId,final boolean readCommitted){super("KafkaConsumerExample", false);this.groupId = groupId;Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");if (readCommitted) {props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");}props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");consumer = new KafkaConsumer<>(props);this.topic = topic;}
consumer.subscribe(Collections.singletonList(this.topic));
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<Integer, String> record : records) {System.out.println(groupId + " received message : from partition " + record.partition() + ", (" + record.key() + ", " + record.value() + ") at offset " + record.offset());}
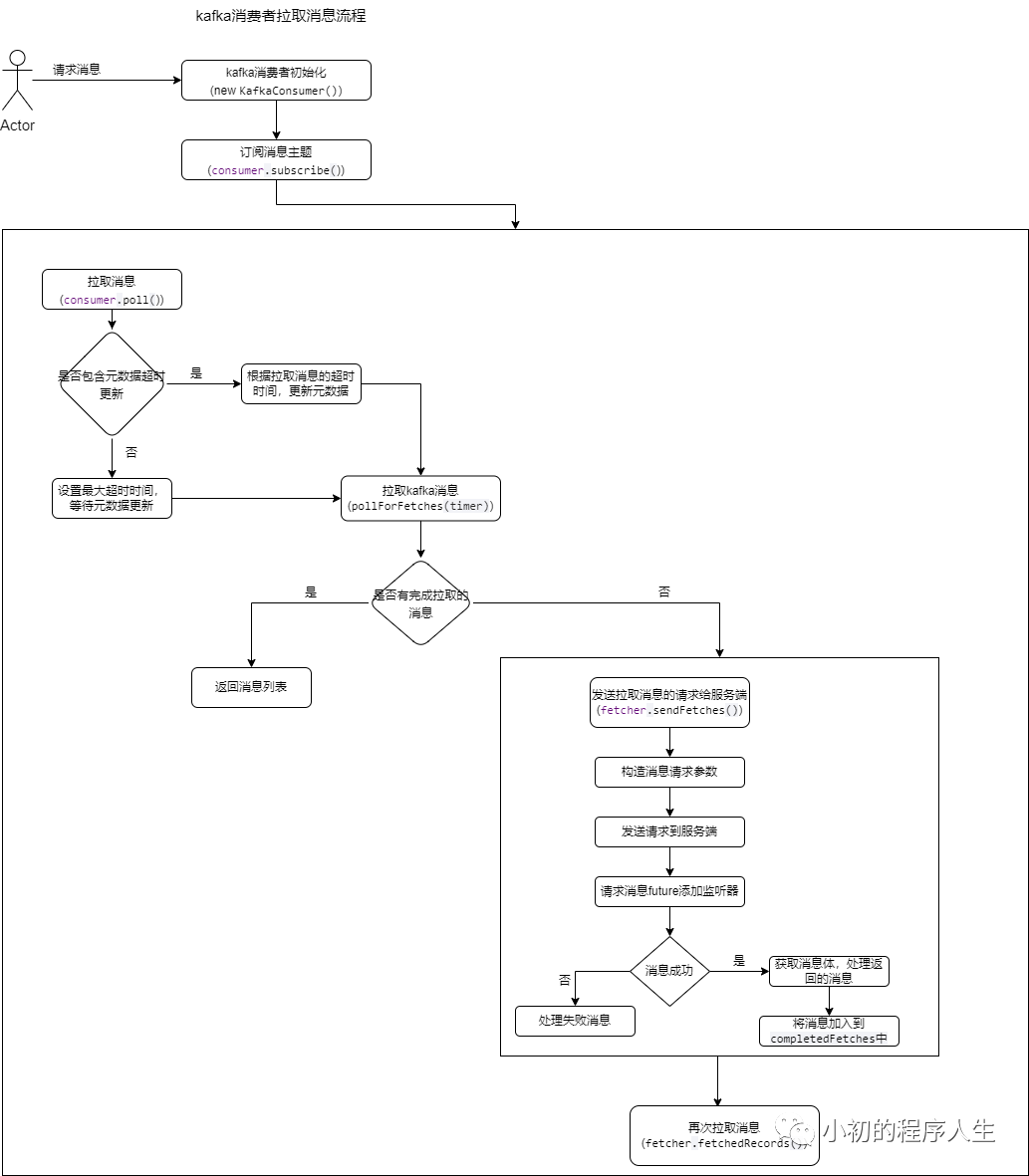
1.更新元数据,主要更新消息订阅的一些详细信息,并且对于消费者组的一些处理,kafka的消息处理是按照消费者组的维度进行处理的,所以,更新元数据,也包括了消费者组的初始化,消费者组的加入,以及选举消费者组的协调者等流程,这里的选举,很简单,只是将第一个加入到消费者组的消费者作为这个组的协调者,后面消费者组内部消费者消费哪些分区的消息,都是由协调者与borker进行交互,最终把消费者的消费分区分发给各个消费者,再由消费者统一去消费kafka的消息列表。
2.拉取本地暂存的消息列表,这里采用消息暂存的机制,主要是为了减少消费者与borker端的交互,将消息暂存在本地,增加消息的拉取效率。
3.发送拉取消息的请求给borker端,获取消息列表,这里消费者的设计是异步实现的,通过添加监听器的机制,完成消息的拉取,并且把成功拉取的消息,放入到本地的队列中。
4.kafka服务端消息处理流程
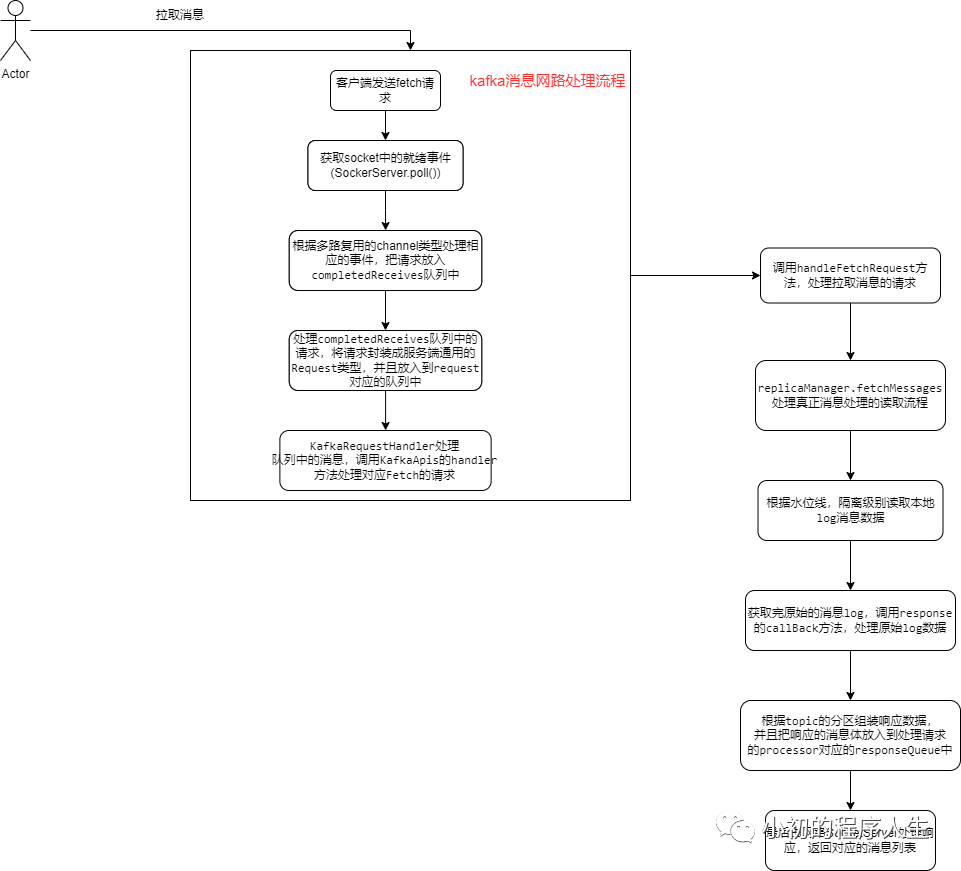
4.将响应列表数据,放入processor对应的responseQueue中,由IO线程处理对应的事件,把数据发送给客户端。
5.消息消费常见问题
a. 重复消费
如果是Kafka消费能力不足, 则可以考虑增加Topic的分区数, 并且同时提升消费组的消费者数量, 消费者数 = 分区数。 (两者缺一不可),此种方案一定要考虑消息的顺序性问题,如果消息有序,那么消息的扩展分区,很可能会造成业务处理异常的问题,如果是这类问题,那么不要轻易扩展分区,而要考虑把消息的消费做的轻量化,考虑失败之后的一些容错手段,以及异步处理消息的方法等。
6.消息者重要参数
| 参数名称 | 描述 |
| heartbeat.interval.ms | Kafka 消费者和 coordinator 之间的心跳时间, 默认 3s。该条目的值必须小于 session.timeout.ms ,也不应该高于 session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消费者和 coordinator 之间连接超时时间, 默认 45s。超过该值,该消费者被移除,消费者组执行再平衡。 |
| max.poll.interval.ms | 消费者处理消息的最大时长, 默认是 5 分钟。超过该值,该 消费者被移除,消费者组执行再平衡。 |
| fetch.min.bytes | 默认 1 个字节。消费者获取服务器端一批消息最小的字节 数。 |
| fetch.max.wait.ms | 默认 500ms。如果没有从服务器端获取到一批数据的最小字 节数。该时间到,仍然会返回数据。 |
| fetch.max.bytes | 默认 Default: 52428800( 50 m)。消费者获取服务器端一批 消息最大的字节数。如果服务器端一批次的数据大于该值 (50m)仍然可以拉取回来这批数据,因此,这不是一个绝 对最大值。一批次的大小受 message.max.bytes ( broker config) or max.message.bytes (topic config) 影响。 |
| max.poll.records | 一次 poll 拉取数据返回消息的最大条数, 默认是 500 条。 |
