






接上篇《严选微服务架构下的监控报警体系化探索》所述,随着业务服务全面接入监控,围绕着以监控指标、异常日志为核心的报警配置逐步失控。在报警治理前:报警接入服务数量800+,报警配置项达60W+,其中超50%为非标报警配置项,此外还有接近10%的僵尸报警项,日均触发报警数量为6W+,其中15%左右的报警长期持续在报,人均日接受报警信息数量为400+。
当一个开发人员日均接收400+报警的情况下,很难再去做到对报警的高响应。但同时一个合格的报警处理动作又一定会有响应时效要求。而导致这两者矛盾的根因,就在于报警风暴问题。为对抗报警风暴,我们在2021年的6月份开启了报警的统一管理建设:
能力层建设:支持了报警的全生命周期追踪、响应处理反馈、自降权处理等。
治理运营:借力稳定性运营小组,同步推进无效报警的下线处理。
2. 报警管理衡量标准
如何抑制告警风暴?如何保障重要告警不漏不丢?如何快速的甄别根因告警?如何沉淀告警处置经验?如何快速恢复业务运行?这些都是我们在做报警管理时面临的最棘手的问题。
要解决以上问题,就要求我们首先能够抽象出一套标准去衡量当前平台的能力边界,明确平台的建设目标和演进路线。基于“不漏报”、“少误报”、“高响应”的目标要求,我们将报警管理时效指标和报警的成熟度模型作为我们报警管理建设的衡量标准。
2.1 报警管理时效指标
衡量报警管理的关键指标为:MTTI、MTTA、MTTR、MTBF,我们会从报警的整个生命周期的不同时间节点来计算关键指标:
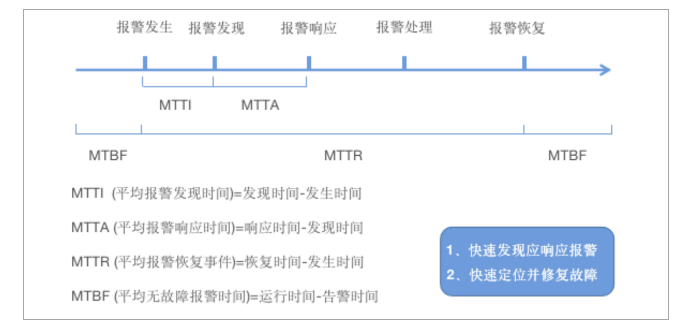
报警管理的根本目标是降低MTTA、缩短MTTR、提升MTBF,即快速发现并响应报警,快速定位并修复故障。
2.2 报警管理建设成熟度

L1-L4 是我们当前平台建设重点关注的成熟度匹配等级,主要针对报警产生后对报警的管理和分析;
L5以及之上的报警预防,则聚焦于故障发生后的无感知自愈,甚至通过报警预测联动知识图谱及自动化运维平台能力将报警消灭在萌芽状态,是我们报警管理的终极目标。
3. 报警风暴治理
3.1 治理思想
报警平台的功能建设,核心就是围绕报警管理时效指标和提升报警管理成熟度,本质上也就是为了能够持续地提升报警的时效性和有效度。
为了达到这个目的,自然而然的,我们就想到了报警聚合:跨模块、跨策略的报警聚合,更主动、更智能的报警抑制。而想要做到这一点就需要我们能尽可能降低报警的噪点干扰,要达到降低报警噪点干扰、减少报警脏污染的目的,就又需要我们首先治理好报警风暴问题。
按照我们最初的设想,所有的报警问题都应该在报警平台侧得到收敛,平台提供让问题就此终结的能力。换言之,我们期望报警平台就是那颗解决报警风暴的银弹。但实际上,在方案推演过程发现,针对当时的报警现状,想要单纯依靠聚合策略的优化去治理报警风暴问题并不现实,原因主要有以下几点:
选择忽略非标场景:意味着策略会根据报警配置是否合规,选择性生效,相当于在事件流内部人为的造成了数据割裂,进一步加大了后续跨资源、跨应用进行报警关联性推导的难度。 选择覆盖非标场景:需要额外再引入一套策略去识别出非标的配置并整合成一个规范的报警配置项,先不论用一个标准的策略去适配一个非标的场景是否合理,如何保证识别策略在面对完全未知的非标接入手段时依旧能够生效?... 这些都是问题。
随着业务发展,过期报警项未及时调整; 部分同学离职后负责的监控报警项未做交接; 部分业务将报警、通知、记录混用。
该规则是否能检测到一个目前检测不到的、紧急的、有操作性的并且即将发生或者已经发生的可见故障? 这条报警是否确实显示了用户正在受到影响,是否存在用户没有受到影响,也可能触发报警的情况?
3.2.1 报警状态全程追踪
对于报警事件的状态追踪:
数据层面:最理想的情况是能追踪到每条报警的全生命周期流转流程,即:每条报警信息以eventID(可追溯product+service+eventName+timestamp信息)为唯一标识,全流程追踪报警的状态转换(聚合/发送/响应),直至该类报警事件超过设定的发送频率时间窗口不再被触发,那么即可认定该报警已恢复并打上恢复标识。在两个恢复标识之间的所有报警记录都可被认定为已恢复,同时恢复时间以后一次打上恢复标识的时间为准。这样,每一条报警记录就都能追踪到对应的恢复时间(或者一直未恢复、持续在报)。
业务层面:并不关心也不需要关心每一条报警记录的最终状态,只需关注单一报警事件最终是否恢复即可。也就是基于业务的视角,并不需要把一个报警事件下钻到多条报警记录的程度。尽管逻辑上两者之间确实存在关联关系。但实质上只需提炼出两条有代表性的报警记录即可:首次报警记录、最近报警记录。这样,异常的起止和影响面更明显,同时也大大降低了计算和存储的复杂度。
3.2.2 报警处理反馈机制
在构建报警处理反馈机制中,重依赖了飞书的卡片消息。当报警级别为P0/P1时(或接入了报警时效处理模块的服务),飞书的报警信息会自动上升为富文本格式,附带处理反馈按钮。一但该报警的接收人中有任意一人点击了立即处理按钮,即认为该报警目前已经处于响应状态,并同步触发报警静默策略,在一定窗口期内(当前为1H)不再发送同类报警。此外,在锦衣卫平台的报警生命周期管理中,该报警的状态也将由待处理状态更新为处理中。如果报警持续在报且长期无人响应,报警方式将自动升级为电话报警。通过这样一种手段,既实现了对报警响应状态的数据回收,同时也进一步减少了报警的重复推送。
3.2.3 无效报警下线处理
在实现对报警状态追踪以及完整的报警处理反馈机制基础之上,基于沉淀、回收的数据,通过简单的数据扫描,很方便的就可以得出哪些报警持续在报、哪些报警长期无人响应,那这类报警就可以初步判定为是无效报警。至于最终是否可以被判定为无效报警,我们会把决定权交给业务。通过飞书治理通知的方式,定期将无效报警的预判结果推送给相关服务负责人。一但相关业务确认了该类型报警可以降权处理,在后台数据层面将对该类报警打上降权处理标识,当再次触发该类型报警时,将触发降权处理机制。目前的降权处理机制分两种:
针对基建类服务的基于预设的报警频率进行进一步压缩;
针对业务类服务的聚合后定时发送,例如一小时只发送一次。
通过对无效报警的降权处理,极大地降低了无效报警对正常报警的干扰。

3.2.4 梯度降权处理机制
既然对无效报警可以进行降权处理,那对高频输出的报警是否也可以进行类似处理?降权处理本质上是在保证不漏报的前提下,尽可能降低报警的推送频率,减少对其他报警的干扰,这点对高频输出的报警也同样适用。
梯度降权处理主要是在接收到报警请求时,过滤掉不必要的报警。例如,依照报警收敛规则,一个报警项的第1次、第2次、第10次、第30次连续报警值得关注,就可以设置收敛表达式为1、2、10、30,那么在报警请求生成时对于第3,4...9,11...29次报警可以忽略,因为反复通知的意义不大。这个规则可以按需要达到自动收敛,也可以在同一报警项的多个实例同时发生异常报警的情况下,按规则合并成一条报警,这些规则可以按具体情况去实现,最终的目的是以最简洁的方式暴露最值得关注的报警。
3.3 运营动作
借力稳定性专项运营小组,开展了报警配置非标接入、报警时效性、有效度的专项治理。本文暂不讨论。
4. 报警聚合收敛
报警风暴的治理,本质上也是为了提升报警有效度。但有效度的提升,绝不仅仅只是报警风暴的治理。报警风暴的治理只是解决了报警量的问题。在解决了量的问题之后,需要依靠报警的聚合收敛来提升有效度的质变。
4.1 跨服务跨资源多维聚合
随着业务发展,模块间的关系愈加复杂。通过单一对象的指标反映的状态已不能满足业务监控需求,这种状况伴生了两大痛点,一是报警量大,二是分析耗时长。报警有一条很重要的准则是”报警是供人而不是计算机阅读的“,报警除了暴露问题之外还需要能够辅助人定位问题,这个很关键。
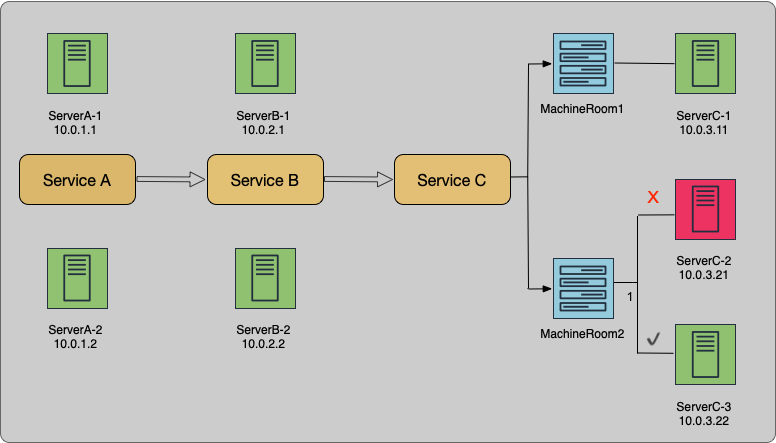
用A、B和C这三个业务模块来说明上述问题:这三个模块的调用关系为A调用B,B调用C,C根据机房划分为C1和C2两个子模块。A模块下有2台机器(10.0.1.1和10.0.1.2),B下有2台机器(10.0.2.1、10.0.2.2),C1下有1台机器(10.0.3.11),C2下有2台机器(10.0.3.21和10.0.3.22)。
假设C模块下的机器负载已饱和,也就是说如果其中有一台机器异常,则提供有损服务,影响B和A的成功率。如果C2模块下的10.0.3.21机器异常,则会触发10.0.3.21机器告警及A和B下的4台机器告警,总共有5个对象产生告警。而通过跨应用、跨资源的报警聚合可以将5条告警聚合为一条报警,即:机器10.0.3.21故障导致服务A、服务B成功率下降,请及时修复。
4.2 报警时间点的事件拟合
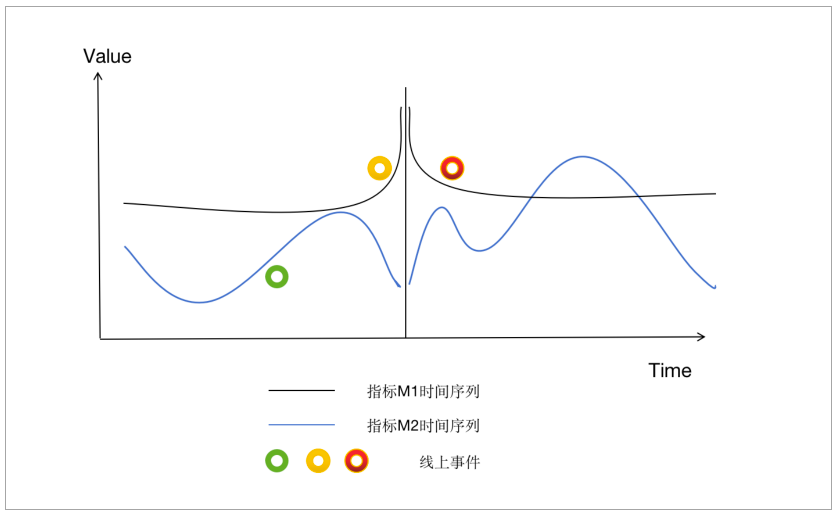
在报警的时间点上发生了什么?这是收到重大监控报警后大多数人的第一反应。我们可以把运维事件、变更事件、运营事件通过事件中心尽可能的收集起来。将这些事件的散点图和监测报警的时序图结合起来,就能看出问题。如果程序自动完成,就是将事件发生的时间点也按相同的方式归一化到固定周期的时间点,检查与报警时间点是否吻合,那么就可以拟合生产事件、报警事件的序列图,进一步提升问题定位效率。
5. 小结
报警平台建设必须要回答的一个关键问题是:究竟,什么样的报警才是一个合理的报警?
Google SRE手册给出的答案是单服务报警数量一周不超过10条。
阿里的Goldeneye的解释则更加侧重于报警的有效性,以“Actionable alerts are the only alerts”为宗旨,信奉“需要处理的告警才发出来,发出来的告警必须得到处理”。
两者表述不同,但根本上都是以报警的有效度和处理时效为核心。两者相辅相成,高效的报警必定能带来高效的处理。相反,很难要求一个日均收到上百+不同类型报警的研发、运维人员去做到及时响应。
秉承着这样的一个准则,严选报警平台的架构演进重点围绕报警时效展开。涵盖报警的全生命周期追踪、处理反馈机制、降权处理手段以及同步在推进的无效报警治理措施等等。同时在这一过程中我们也逐步发现,报警风暴的治理是个全链路的工程。从非标报警接入的改造到无效报警的治理,都离不开业务开发人员的支持与协作,这就意味着,要想有效地解决报警风暴问题,需要平台与业务方协同联手,也只有这样,才能做到在源头上杜绝、在传播中管控、最终达成报警的"合理"输出。
本文由作者授权严选技术团队发布


