随着数据量的增大,特别是百亿千亿规模的数据量级运算已经成为常态的背景下,使用更少的资源和更少的时间,更高效地得到数据的统计结果、计算去重汇总指标是非常频繁的业务需求之一。很多时候,我们不需要非常准确地得到具体的数字结果,而是从海量数据得到整体数据在不同维度上的趋势或者宏观描述性统计特征,就足以很好的指导决策、判断业务效果;因此围绕概率算法本身的研究成为当前一个热门的方向。接下来简单介绍两种非常有效的算法,来探讨一下非精确的算法在大数据开发中的一些场景应用!
1. 概述
在大数据计算的的池子里面,我们涌现了非常多的优秀方案,来解决庞大数据的统计问题;特别是对于类似UV这种去重指标的计算,一直让人非常头疼;研究算法的人,也一直期待用更高效的算法来提高计算的准确性和计算的效率。比如基于BitMap的精确去重,以及基于概率估计的HyperLogLog算法,早已在大数据领域得到成熟的应用。本文章谈到的两种算法,本质上也多多少少跟概率有些关系,在本文中介绍的两种算法,都是基于HASH算法慢慢演化出来的,所以HASH算法是基石,有兴趣的可以看看关于HASH算法的一些文章,本文不赘述。
布隆过滤器(BloomFilter)一直是在服务开发中常用的算法之一:比如来做恶意网页的过滤,做一些缓存设计,甚至在一些调度和引擎模型中均有所应用;
Count-min-Sketch是一个频次统计算法,在一些TOPK或者实时统计一些排名指标中,可以考虑选择。其实这些算法的目的就很简单,就是损失一些精度,但是在效率和存储上得到了很大的提升,也正是这样的特性,在庞大数据计算中,我们可以找到在满足业务需求的前提下,在计存和效率上取得平衡!
2. 谈谈BloomFilter
2.1 原理介绍
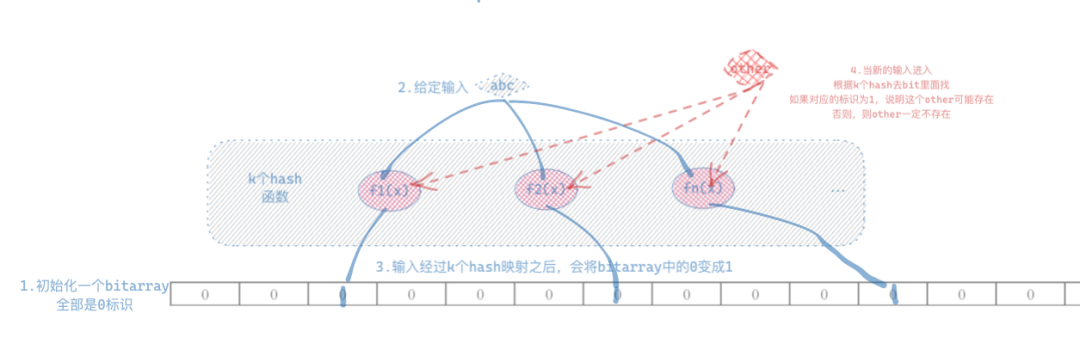
首先简单说下HASH算法:HASH算法简单说,就是找一个规则,将输入根据一定规则,散列成等长的位串,可理解为信息的有损压缩,因此会出现一定的误判,也就是常说的HASH冲突—不同的输入,得到相同的散列结果。BloomFilter是基于HASH这种特性演化出来的一种结构,一个空间极其高效的概率模型,就是很大的数据量,经过这一波HASH压缩,能用很小的存储结构来标识;利用该特性就可以用来判断输入的元素是否在集合里面。- 元素命中集合的,可能这个元素在里面,也可能不在里面;
- 被散列之后的数据一般较难还原成原始结果,这里面涉及到解密成明文,不是不可以,是计算成本比较高,特别是在经过多次HASH之后,还原出原始结果,是个吃力不讨好的事情,一般也不会这么干;
- 关于数据删除:目前存在一些可删除的BF算法,比如CBF算法,但是同样需要消耗巨大的存储来维护一个COUNTER结构,这里暂不讨论这种算法;
- 强大的压缩比,几百万的数据放到BF里面,可能就用几KB,几M就能表示了,因此很容易被加载到内存里面。
因此,可以利用第一个属性,在数据处理过程中,进行不同层面的优化和数据层面的处理。(这里说一下:记住这些特性就好了,算法研究不是数据研发的重点,熟悉原理,能灵活运用即可。)
之前说到BlooomFilter是信息有损的,那自然就不能保证100%正确,因此就会涉及到精确度的问题。大家简单从概率上大致理解就好了:就是在一个给定的盒子里面放给定数量的小球(小球是有编号的),有放回的随机抽样,抽到相同编号小球的概率,就可以理解为一次HASH冲突的碰撞概率!因此我们可以看到,如果我HASH寻找的空间足够长,损失的信息足够小,或者我多次使用不同的HASH操作,都可以降低出错的概率。因此HASH函数的选择,和使用多少次HASH函数,成为精确度控制的关键。这里有一篇文章HASH冲突的概率(https://blog.csdn.net/u012926924/article/details/50717407),有兴趣可以研究一下。大家不用太担心,在目前的BloomFilter实现中,一般都是可选的精度参数控制,可以根据待处理数据的大小和期望的精确度,根据数学概率计算反推需要选取具体多少位的HASH函数以及需要多少个HASH函数来逼近期望精度。而且,数据查找的速度,基本能维持在O(1)的复杂度。2.2 BloomFilter在去重指标计算场景中的运用
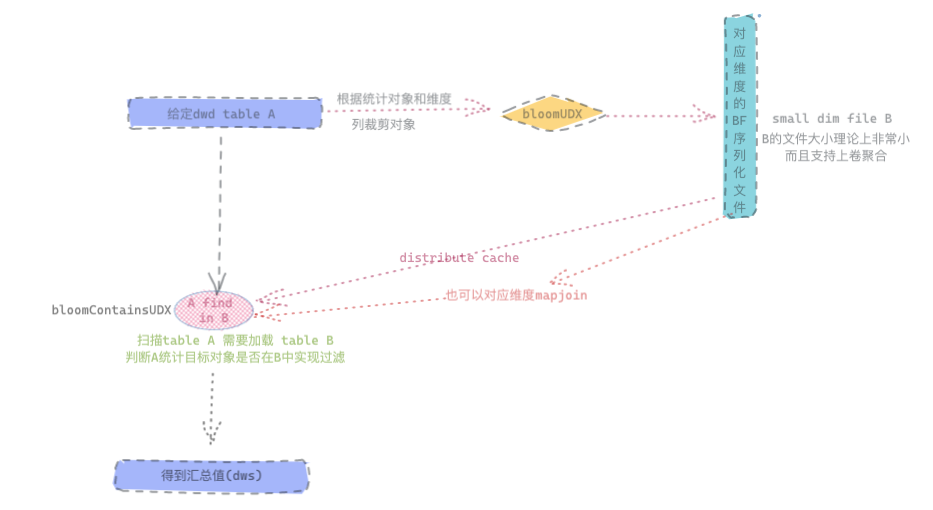
由于BloomFilter算法难以还原明文的,因此不能直接用来解析解聚合得到的结果值,所以离线中,使用起来稍微还是有点小麻烦的。
首先要得到被统计对象的全局映射结果;
然后基于映射结果,在不同维度上根据不存在集合的数据一定不存在(过滤掉),存在集合中的可能存在;
最后累积起来就是得到的去重指标结果,而且对数据类型没有限制。
同时,在目前的算法结构中,可以对BloomFilter的结构进行任意维度的AGG上卷操作,因此,在某些特定场景下,是可以考虑用来做非精确结果的统计。在HDFS文件存储中,比如ORC存储,就可以直接进行BloomFilter设置索引列,提高表查询的速度。
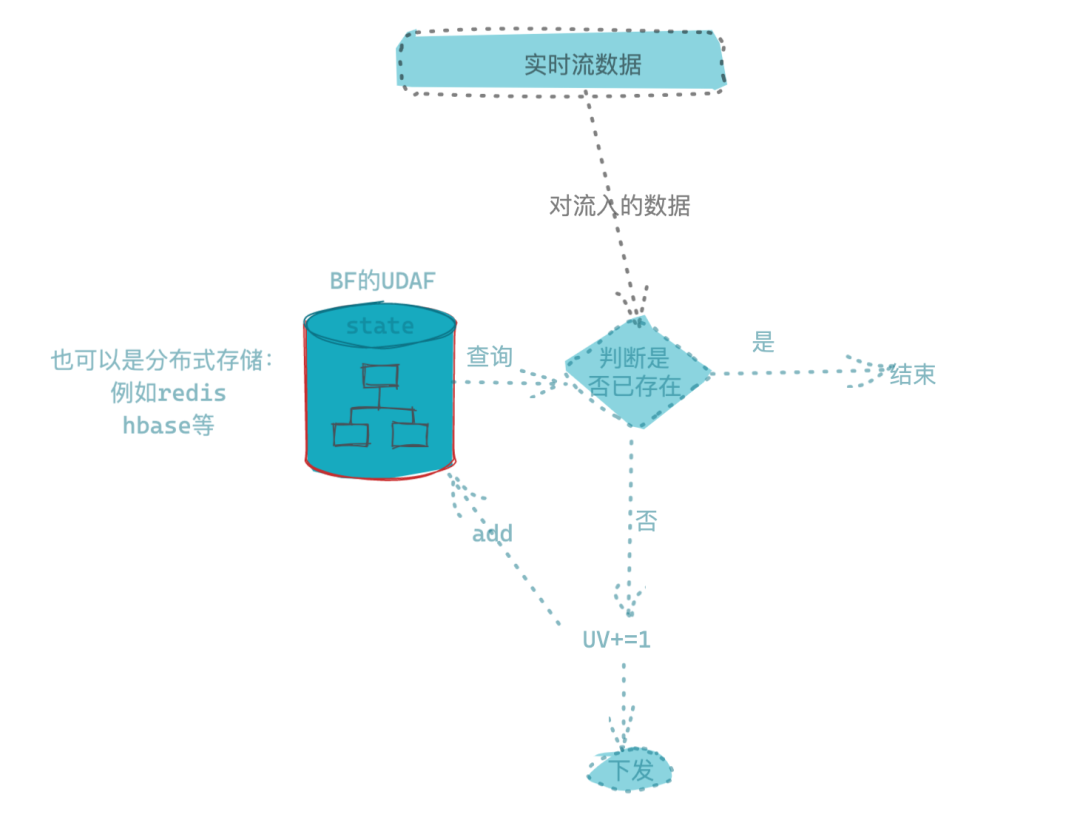
可以看到在离线里面使用这个玩意儿还是有些许的麻烦,并不像HyperLogLog算法和BitMap算法那么直观,而且需要先扫描一遍数据,其实可以直接将被统计对象列,全部聚合到序列化文件对象里面,而不需要按着维度进行聚合,而实际操作中,我们也是这么做的!当统计目标对象列被映射到BF结构里面去之后,就可以利用BF特性,对原始表进行不同维度上的去重计算。这里面需要完成一些UDF的开发和定制,实际上,HIVE和Spark都有内置的BF算法函数的不同实现,在HIVE的2.7版本之后,我们可以看到还有对BloomFilter算法的优化实现,在HIVE中有两种算法的实现,一个是标准的BloomFilter算法实现,一个是BloomKFilter实现。在能力构建的时候,也是直接使用了HIVE引擎当中BloomKFilter的实现,并将2.7版本的UDAF和UDF的实现完全拷贝出来复用了!当然,在开源实现中,也有很多现成的算法包可以使用,例如基于java实现的BF结构以及谷歌guava的实现等等。我们看到在离线下,使用BF结构进行指标维度的统计,整体上还是稍微有点麻烦一些,所以在离线数据模型建设中更多的还是直接用可以直接得到结果的方案,比如HLL结构,我只需要写好了定制的UDX函数,直接获取结果就好了,而不需要其余的操作。但并不绝对,还是要看具体的场景。而在实时的场景中,BF的应用可能就更多一些了,除了之前提到服务端缓存技术实现之外,实时数据建设过程中,也经常利用BF结构结合分布式缓存系统(或者HBASE)来进行指标的计算,在消息幂等过滤中也有的用到BloomFilter先行滤掉一部分数据;如果能预估数据的全集量级,那就更好了,可以直接将统计目标,退还成实时维表的方案,来计算一个误差允许范围内的统计目标结果。实时场景的去重计算,有比较成熟的行业应用,可以自定义一个UDAF实现,也可以借助分布式缓存服务来实现,感兴趣的可以自行百度一下。2.3 BloomFilter在JOIN场景的优化
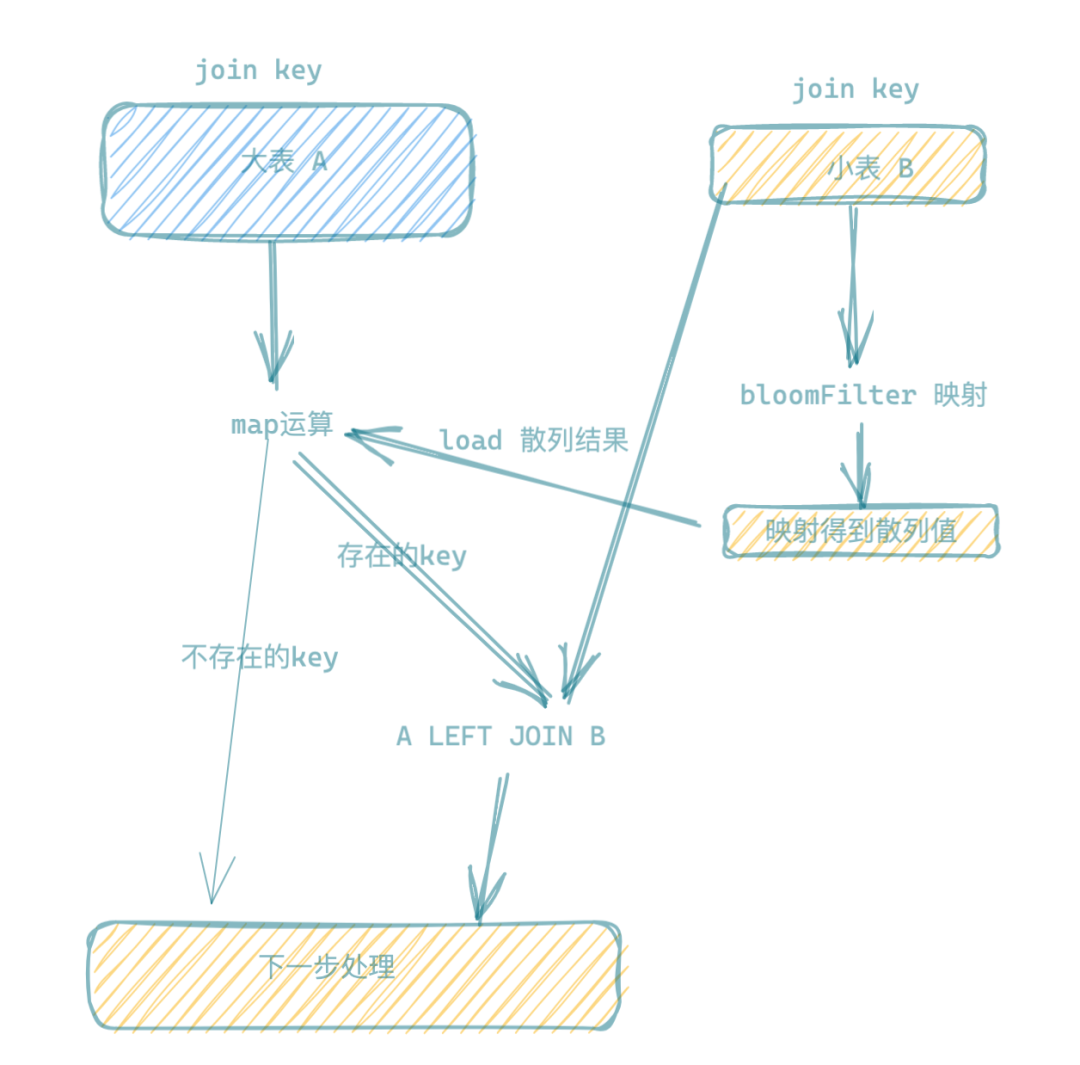
通过BF在去重指标计算的过程我们可以看到,特别是在离线场景的应用,其实BF可以用来对离线计算中JOIN算子的优化,在离线计算中,我们往往对于小的表走的是MAPJOIN或广播JOIN,但是有些场景,比如A LEFT JOIN B:
A表如果是500亿数据,B表也有20亿的数据,B表本身就很大,走MAPJOIN或者广播JOIN本身就存在风险和不确定性,如果A中存在大量JOIN KEY不在B中的情况,那么就需要消耗大量不必要的网络shuffle操作。
这个时候其实就可以基于BF做一些算子优化,优化方案很简单,如下图所示:
- 首先:基于B表JOIN KEY做一次BF序列初始化;
- 然后,基于A表过滤出命中的部分参与JOIN,没有命中的部分,直接MAP出去,做下一步的运算。
如果我们遇到类似的场景,可以基于现有UDF的能力,手动进行优化。3.1 原理介绍
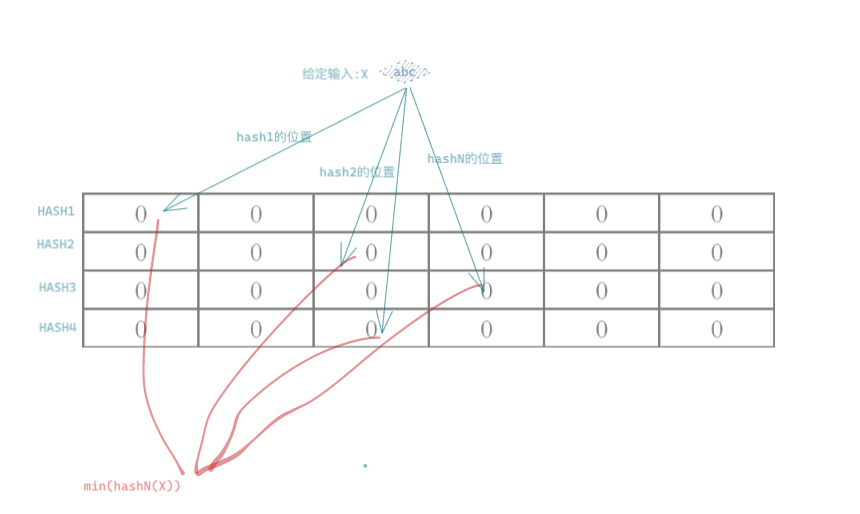
在了解了BloomFilter算法之后,我们就简单了解下Count-min Sketch 这个算法:本质上Sketch算法也是基于BloomFilter算法衍生出来的,依然是HASH算的法进一步异变。原理很简单,既然能将输入的数据,散列到HASH数组中,那么就可以根据连续不断的数据,记录每次散列到目标结果的次数,这个次数就是被统计目标的频率,由于存在HASH冲突,所以Count-min Sketch统计的结果会偏大。所以目前存在一些优化的算法—同样引入一组HASH函数,对同样的输入散列,得到一组多个结果,选取多个结果的最小值作为最终的结果(如下图所示),可以极大的提高准确率。- 每组HASH向量的长度w,使用的HASH函数的个数:d,消耗的存储就是每组HASH向量的存储之和。同样的也可以根据期望达到的精确度,来设置选取的w和d的大小!
3.2 应用场景
根据基本原理的简单介绍我们可以看到算法具有以下特性:
占用存储非常少,并且与数据量大小无关;假如每个计数单元占4B存储,几十万的数据,也就需要几十KB左右的存储就够了。
属于非精确概率计算;
统计的频率结果偏大;
运算速度快;
使用的场景:
- 在大数据量,能接受一定误差,快速获取TOP排名的情况,无论离线和实时,都可以使用;在一些看板,或者话题排名,以及投诉声音的统计上可以尝试运用。
4. 思考总结
- 文中介绍的两个算法是在日常的积累中,演化出来的一些想法,部分功能还有待进一步探讨验证;其中BloomFilter算法在很多存储引擎和分布式缓存系统设计中,都已经有了非常成熟的运用,而在数据研发领域,可以借鉴;特别是在实时数据无界流的计算场景下;
- 目前学术界对于以上两种算法有了纷繁复杂的研究和深化,虽然有些算法比较先进新奇,但是在工业环境中,依然还没有得到实践的验证,因此感兴趣,有时间的同学可以自行研究一下;
- 数据研发本身是一个极其综合的岗位,考虑更好的模型,更精简的链路,更合理的设计解决不同场景的问题,既要有业务视角,又要有技术视角,同样需要具备架构视角。