大数据 / 人工智能 / 区块链 / 数据库 / 热点 随着技术迭代,传统的基于CPU的数据库逐渐遭遇性能瓶颈,异构计算应运而生。本文为您盘点数据库异构计算的现状,并预测其未来发展方向。
随着技术迭代,传统的基于CPU的数据库逐渐遭遇性能瓶颈,异构计算应运而生。本文为您盘点数据库异构计算的现状,并预测其未来发展方向。 
王文娟 | 文
© 中兴数据智能(ZTE-DI)出品
异构计算的前世:同构计算
异构计算的英文名称是Heterogeneous Computing,主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU等协处理器、DSP、ASIC、FPGA等。异构计算的前世是同构计算:中央处理器(CPU,Central Processing Unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元;传统CPU芯片(主流的包括X86、ARM)计算可以叫同构计算,也可以叫通用计算,设计之初,更多的是注重控制。基于CPU开发的数据库系统就是传统的数据库同构计算。然而随着时代变迁、技术迭代,传统的基于CPU的数据库逐渐遭遇到了性能瓶颈。
近些年来,国内外不少数据库厂商已经开始尝试使用数据库异构计算来解决性能瓶颈的问题。我们一起来看看都有哪些。阿里采用 FPGA加速数据库
X-Engine 是阿里研发的新一代存储引擎,是新一代分布式数据库X-DB的根基。Compaction是阿里设计的X-Engine引擎中的一个compare & merge的过程,非常消耗CPU和存储IO,在高吞吐的写入情形下,大量的Compaction操作占用大量系统资源,必然带来整个系统性能断崖式下跌,对应用系统产生巨大影响。在传统的基于LSM-tree的存储引擎中,CPU不仅要处理正常的用户请求,还要负责Compaction任务的调度和执行,即对于Compaction任务而言,CPU既是生产者,也是消费者,对于CPU-FPGA混合存储引擎而言,CPU只负责Compaction任务的生产和调度,而Compaction任务的实际执行,则被offload到专用硬件FPGA上。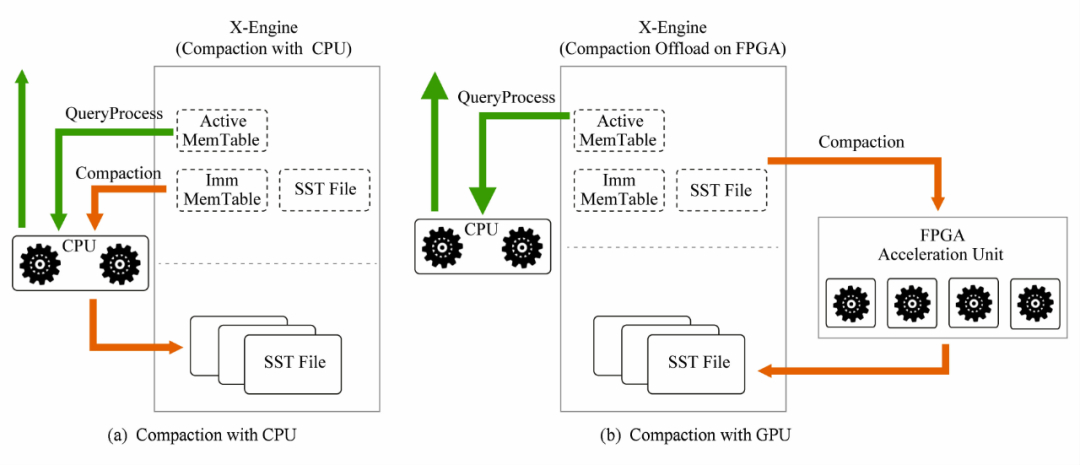
▲ 图片来源:《X-DB:软硬一体的新型数据库系统》
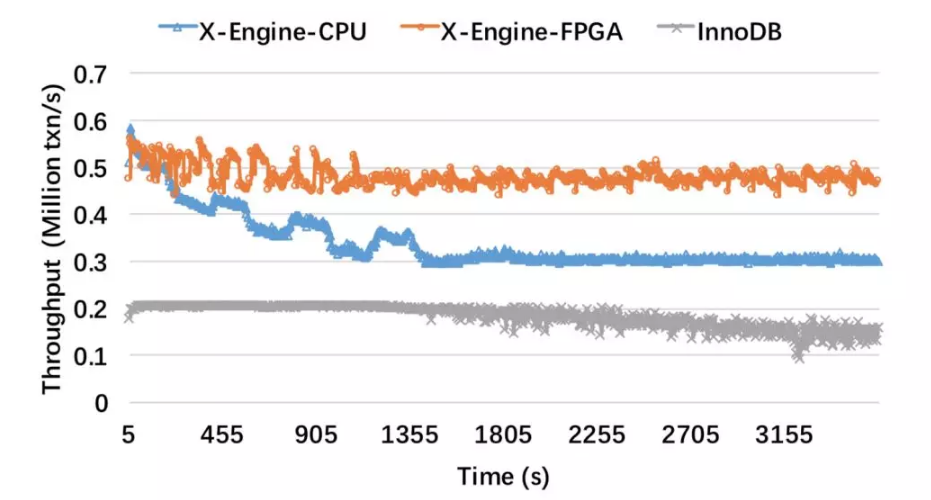
▲ 图片来源:https://developer.aliyun.com/article/578308 如上图所示,带有FPGA加速的X-Engine存储引擎,对于KV接口有着50%的性能提升,对于SQL接口获得了40%的性能提升。随着读写比的降低,FPGA加速的效果越明显,这也说明了FPGA Compaction加速适用于写密集的workload。
中兴通讯DBPlat A及DBPlat T采用FPGA加速数据库
DBPlat A及DBPlat T这两款数据库充分利用了FPGA特有的高并行处理、可编程特性、MISD特性等特点,将数据库内核架构做了相应适配,把数据库逻辑(比如压缩解压缩)进行抽象整合成独立的kernel,整合到XRM上进行计算,大大缩短了数据路径,提高了数据库的性能。Kinetica采用GPU加速数据库
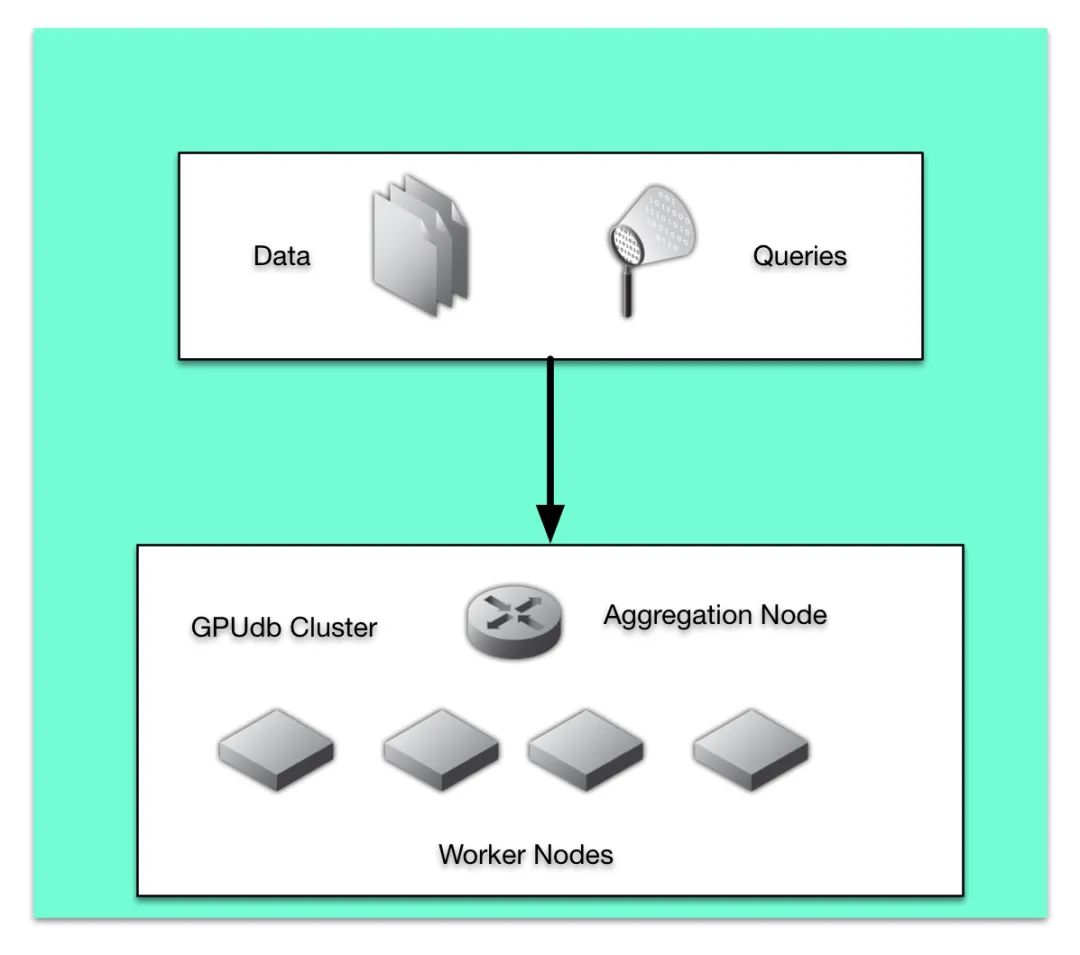
▲ 图片来源:https://www.kinetica.com/docs/overview/arch.htmlKinetica 是一款商业数据库。据 Kinetica 的创立者称,2010 年美国陆军情报和安全指挥中心(US Army Intelligence and Security Command) 希望处理 200 个实时数据流,包括手机、无人机、社交网络和 Web 访问,每小时 2 千亿条记录,为分析师和开发者们提供接口,来结合时间和地理位置监控危险信号。他们尝试了 HBase,、Cassandra 和 MongoDB, 但一直未能解决同样的问题:能支持的查询极为有限,索引越来越多,越来越复杂,并一直需要增加硬件。得到结果的速度越来越慢,开始是 1 个小时,随着索引越来越复杂,逐渐需要 1 天,后来发展到一个星期。利用两年时间,他们开发了基于 GPU 的系统才彻底解决了该问题——用 HBase 作为永久存储,用 GPU 数据库提供实时加载、实时查询。多个实时流可以从多个 Head 节点,多线程加载,可处理每分钟 14 亿条。
▲ 图片来源:https://docs.sqream.com/en/latest/guides/architecture/internals_architecture.htmlSQream DB是一款由SQream公司提供、能够支撑海量数据高速分析的业内领先的GPU数据库。通过将计算密集型操作offload到GPU上,与业界的解决方案相比,SQream DB能够将数据采集和分析速度提高数十倍。存储海量数据的同时,能够利用GPU加速计算,以极低的硬件成本、高效的计算能力,使得中小企业客户都可以近乎实时地存储和分析巨大的数据集。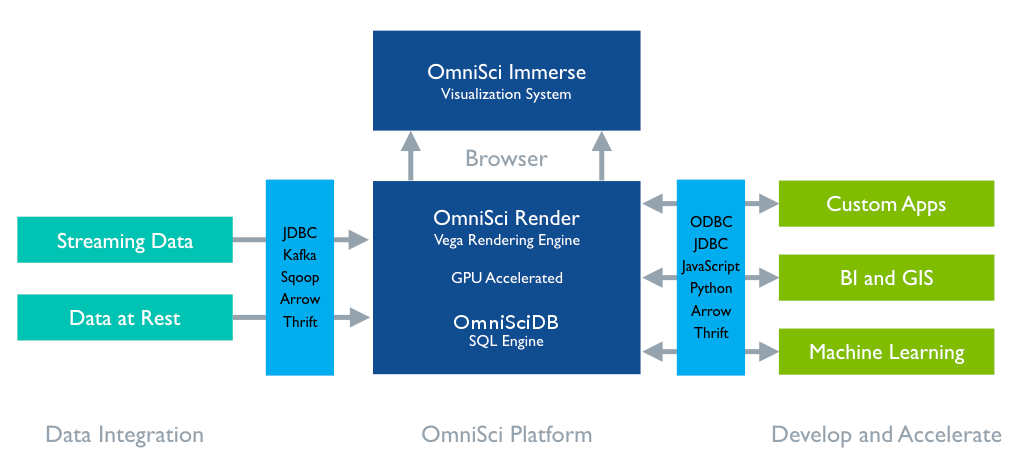
▲ 图片来源:http://docs.mapd.com/latest/1_overview.htmlOmniSciDB是使用GPU进行加速的数据库,它是以毫秒为单位分析数十亿行数据的先驱,比传统的基于CPU的数据库快几个数量级。该数据库已Apache 2.0开源。OmniSciDB最主要的改进是使用构建在LLVM上的JIT(即时)编译框架来替代查询解释器。PG-Strom是PostgreSQL的扩展模块,是连接PostgreSQL和GPU的桥梁,它将CPU的密集型工作转移到GPU处理,利用GPU强大的并行执行能力完成数据任务。主要支持SCAN、JOIN和GROUP BY等操作。异构计算的未来:你准备好了吗?
使用专用硬件FPGA/GPU/NPU等解决传统数据库的性能瓶颈已经成为了一个趋势。数据库不再是仅仅运行在CPU和内存中的二进制代码,也不再是高端硬件的简单堆叠,关键软硬件必须在设计阶段就要针对数据库特性做深度定制和优化,借用Alan Kay的名言:People who are really serious about software should make their own hardware.未来几年,将有越来越多的数据库厂商支持异构计算,并且涉及的场景也越来越多:- 数据库内部将根据不同场景应用不同的XPU专用计算硬件进行加速,比如压缩、加密、归并等采用FPGA,扫描、排序、JOIN等统计分析运算采用GPU加速,AI相关算法采用NPU加速,等等。
- 针对某些厂家的特定数据库,FPGA/GPU/NPU等通用XPU逐渐演化成专用ASIC,甚至与通用CPU整合成一个专用SoC。
- AI-Native数据库应用NPU加速AI算法处理,实现自运维、自管理、自调优、故障自诊断和自愈等功能。
- 在云原生数据库上应用异构计算,实现超高性能云数据库。
- 缩短大规模数据查询分析时长,实现更复杂的统计分析场景。
- 实现数据库智能运维,代替人工DBA,节省人力成本。
异构计算XPU具有更多的核数和并行技术能力,理论上可以提高数据库的性能。但实践中极具挑战,还需要进一步的探索:
参考文献:
https://yq.aliyun.com/articles/578308
https://blog.csdn.net/Han_L/article/details/88814664
https://docs.sqream.com/en/latest/guides/internals_architecture.html
https://www.kinetica.com/docs/overview/arch.html#how-it-works
《X-DB:软硬一体的新型数据库系统》作者:张铁赢等
http://docs.mapd.com/latest/
* 本文为中兴数据智能原创文章,转载请留言或评论获取授权。








