





SRAM 是静态存储器,只要处于通电状态,内部数据就可以保存,一旦断电数据就会丢失。一般被集成在CPU里用做高速缓存。
DRAM 是动态存储器,其中的存储单元使用电容保存电荷的方式开存储数据,电容会不断漏电,所以需要定时刷新充电才能保持数据不丢。一般被用作主内存。
L1 高速缓存:每个 CPU 核心都有一个属于自己的 L1 高速缓存,通常内置在CPU核心旁边,能存储 32 kb 的数据;存取需要 4 个CPU时钟周期。
L2 高速缓存:L2 同样也是每个核心都有的,离内核远一些,但是存储空间更大,能存储 256kb 的数据;存取需要 11 个CPU时钟周期。
L3 高速缓存:L3 一般是多个核心共享的高速缓存,能存储数个 MB 的数据;存取需要 39 个CPU时钟周期。
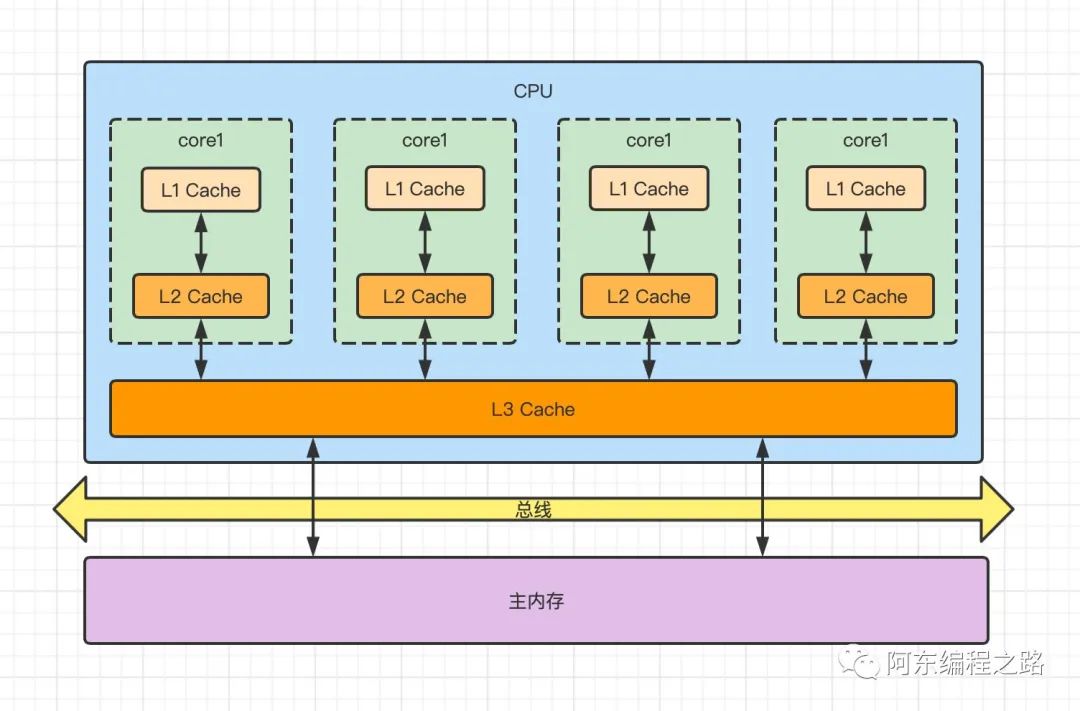
性能上:其实存储的数据小,寻址的速度更快,也就能更好的利用 SRAM 的性能;打个比方,高速缓存就像我们衣服上的口袋,主内存就像我们的背包,如果口袋特别大装的东西很多,我们就要花上不少时间去寻找,口袋的目的就是快速存取。
成本上:就一句话,SRAM 贵!
MESI 协议其实就是:当有 CPU 对某「缓存行」进行修改时,总线会嗅探到修改,并通知其他 CPU 核心将本地的高速缓存设置为失效状态,下次读缓存时,如果发现该缓存行已经失效,会直接从主内存读取数据;但是这个修改需要等待其他 CPU 将缓存设置为失效状态再写回主内存,性能比较差所以引入了 Store Buffer(写缓冲),有修改操作时会先写到 Store Buffer 然后直接返回,等待后续所有 CPU 中设置该缓存失效完成后将修改写回主内存,从而保证不同 CPU 核高速缓存之间数据的一致性。总之是种最终一致性的实现。
public class VolatileDemo {private static class NoVolatile {long a;}static NoVolatile[] array = new NoVolatile[2];static {array[0] = new NoVolatile();array[1] = new NoVolatile();}public static void main(String[] args) {int times = 100000000;Stopwatch write = Stopwatch.createStarted();for(int i = 0; i < times; i++) {array[0].a = i;}System.out.println(String.format("不使用 volatile,写%s次,耗时%sms",times, write.elapsed(TimeUnit.MILLISECONDS)));Stopwatch read = Stopwatch.createStarted();for(int i = 0; i < times; i++) {long temp = array[0].a;}System.out.println(String.format("不使用 volatile,读%s次,耗时%sms",times, read.elapsed(TimeUnit.MILLISECONDS)));}}
不使用 volatile,写100000000次,耗时128ms不使用 volatile,读100000000次,耗时44ms
public class VolatileDemo {private static class HasVolatile {volatile long a;}static HasVolatile[] array = new HasVolatile[2];static {array[0] = new HasVolatile();array[1] = new HasVolatile();}public static void main(String[] args) {int times = 100000000;Stopwatch write = Stopwatch.createStarted();for(int i = 0; i < times; i++) {array[0].a = i;}System.out.println(String.format("使用 volatile,写%s次,耗时%sms",times, write.elapsed(TimeUnit.MILLISECONDS)));Stopwatch read = Stopwatch.createStarted();for(int i = 0; i < times; i++) {long temp = array[0].a;}System.out.println(String.format("使用 volatile,读%s次,耗时%sms",times, read.elapsed(TimeUnit.MILLISECONDS)));}}
使用 volatile,写100000000次,耗时743ms使用 volatile,读100000000次,耗时155ms
public class Demo {private static class Node {volatile long l;}// 使用数组让两元素尽量处于同一缓存行中static Node[] array = new Node[2];static {array[0] = new Node();array[1] = new Node();}public static void main(String[] args) throws Exception {CountDownLatch count = new CountDownLatch(2);Stopwatch stopwatch = Stopwatch.createStarted();// 两个线程分别写入 1 亿次Thread write0 = new Thread(() -> {for (long i = 0; i < 100000000L; i++) {array[0].l = i;}count.countDown();});Thread write1 = new Thread(() -> {for (long i = 0; i < 100000000L; i++) {array[1].l = i;}count.countDown();});write0.start();write1.start();count.await();System.out.println(String.format("耗时={%s}ms",stopwatch.elapsed(TimeUnit.MILLISECONDS)));}}
耗时={1951}ms
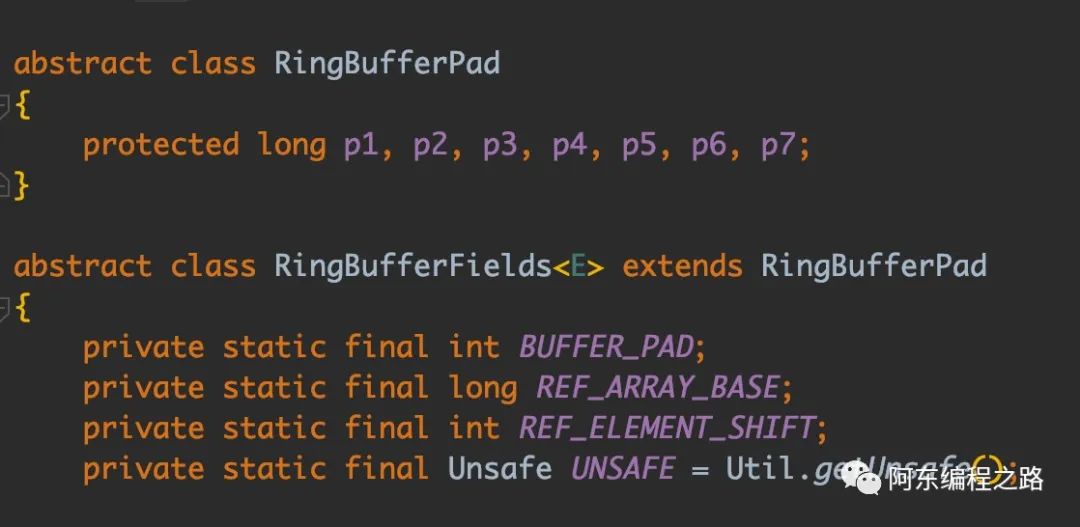
public class ContentDemo {private static class Pad {long l1, l2, l3, l4, l5, l6, l7;}private static class Node extends Pad {volatile long l;}static Node[] array = new Node[2];static {array[0] = new Node();array[1] = new Node();}public static void main(String[] args) throws Exception {CountDownLatch count = new CountDownLatch(2);Stopwatch stopwatch = Stopwatch.createStarted();// 两个线程分别写入 1 亿次Thread write0 = new Thread(() -> {for (long i = 0; i < 100000000L; i++) {array[0].l = i;}count.countDown();});Thread write1 = new Thread(() -> {for (long i = 0; i < 100000000L; i++) {array[1].l = i;}count.countDown();});write0.start();write1.start();count.await();System.out.println(String.format("耗时={%s}ms",stopwatch.elapsed(TimeUnit.MILLISECONDS)));}}
耗时={985}ms
 !
!
文章转载自阿东编程之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
