





本地生成,无网络消耗,性能较强。
存储空间占用大:UUID 比较长,通常会以 36 长度的字符串表示; 信息不安全:主流的基于 MAC 地址生成的 UUID 会暴露 MAC 地址。 无序性:无序不适合作为 MySQL 的主键和索引,因为 MySQL 的索引是通过 B+ 树实现,无序的索引数据插入会造成整体树结构频繁变动,影响性能。
优点:自增,不会重复,使用简单。 缺点:强依赖数据库,且性能较差。
优点:使用简单,性能较强,自增且不会重复。 缺点:强依赖 Redis,如果 Redis 出现故障或发生内存淘汰可能会出现问题。
优点:性能强,趋势自增,不会重复。 缺点:还是需要依赖数据库。

优点:性能强,趋势自增,不会重复。 缺点:强依赖时间戳,如果发生时间回拨或闰秒会出现重复。
保证全局唯一不重复;
全局趋势递增,保证数据库索引的性能;
尽量减少外部依赖或是外部依赖的时间;
高可用,要有熔断降级的策略来保证出现异常也能对外提供服务;
高性能,ID 生成尽量基于内存;
高并发,在高并发场景下不会有线程安全问题。
刚刚上面提到了雪花算法是由 64 位 long 型存储(最高位存储 0 代表正数,41 位存储时间戳,10 位存储机器码,12 位存储序列号),所以保证机器号唯一即可实现分布式下的唯一 ID。业界主流的做法是注册到 zookeeper 上返回顺序节点号当作机器号,这种做法没什么问题,但是时间回拨的解决比较麻烦,每隔三秒需要上报一次系统时间,启动时判断下,如果「当前时间」小于「上次上报时间」超过阈值就只是启动失败并告警。
发生前:有种解决方案是关闭操作系统的ntp服务(时间同步服务),但这种方式不太可控,如果一直不更新时间,本地时间跟正确时间相差就越来越大。
发生后:换种思路,只要最终 ID 不重复就算重启时发生时间回拨也没关系,所以如果发生了时间回拨,我们可以选择重新注册一个新机器号,这个机器号一定得避开上次注册的,这样就可以防止 ID 重复。
随机生成策略:随机生成一个机器号(默认0~1023的随机数)注册到Redis上,如果返回false或异常,再次生成随机数去注册,循环往复,这个循环次数也需要限制,否则可能会造成死循环。
顺序生成策略:从 0 开始向Redis注册机器号,失败进行递增,直到递增至1024。
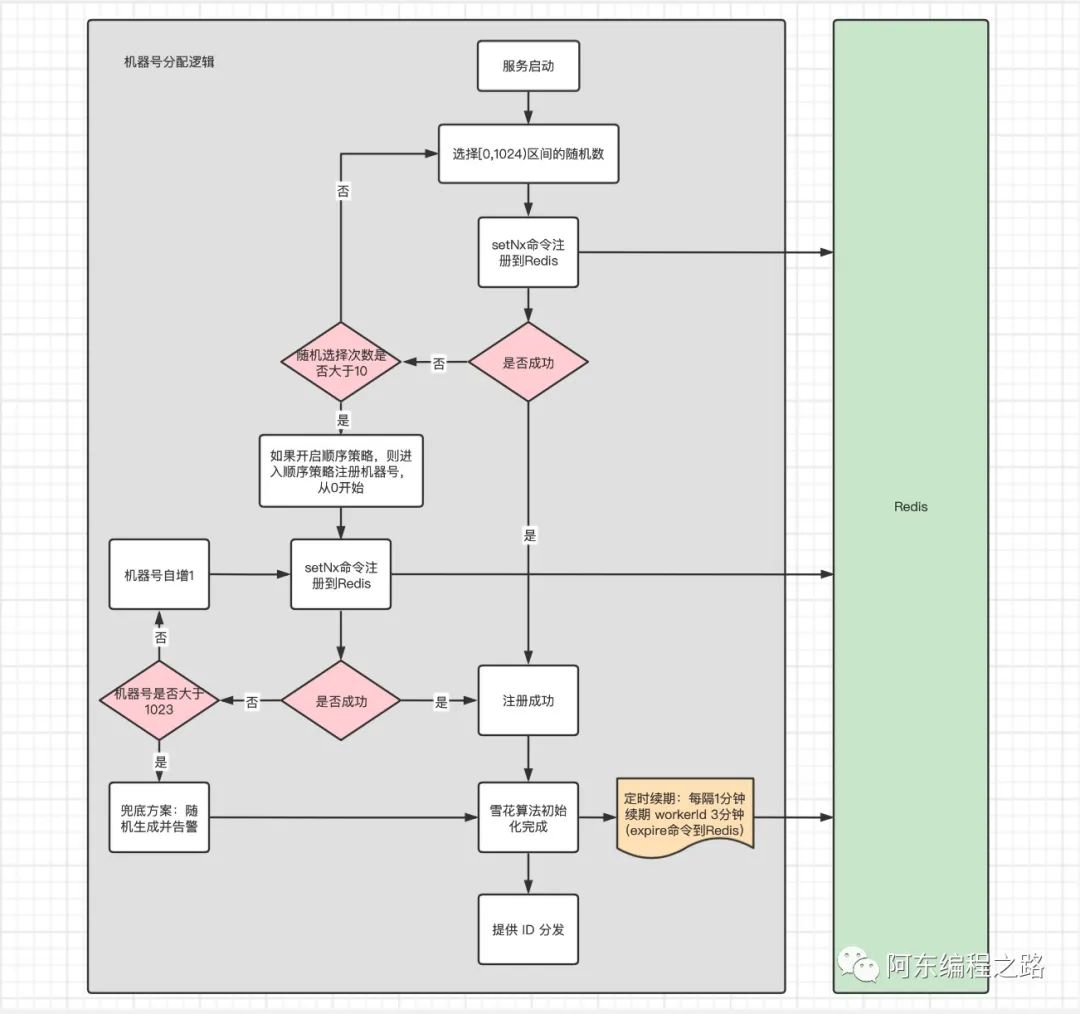
package com.adong.fingermark.core;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.data.redis.core.RedisTemplate;import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.ThreadLocalRandom;import java.util.concurrent.TimeUnit;/*** @author ADong* @Description WorkerId 管理,{@link SnowFlakeId#workerId}* @Date 2022-08-15 11:45 AM*/public class WorkerIdManager {private static final Logger log = LoggerFactory.getLogger(WorkerIdManager.class);private final RedisTemplate redisTemplate;/** 区分业务 **/private final String appKey;/** workerId 阈值 **/private final long maxWorkerId;/** 是否开启顺序策略 **/private final boolean openSequenceSetWorkerId;/** 续期任务线程池 **/private final ScheduledExecutorService service;/** 续期时间, 单位s **/private final long renewalTime;/** 续期任务间隔, 单位s **/private final long renewalIntervalTime;private final Thread shutdownHook;/** 机器号 **/private volatile Long workerId;public WorkerIdManager(RedisTemplate redisTemplate,boolean openSequenceSetWorkerId,String appKey,long maxWorkerId,long renewalTime,long renewalIntervalTime) {this.redisTemplate = redisTemplate;this.openSequenceSetWorkerId = openSequenceSetWorkerId;this.appKey = appKey;this.maxWorkerId = maxWorkerId;this.renewalTime = renewalTime;this.renewalIntervalTime = renewalIntervalTime;this.service = Executors.newSingleThreadScheduledExecutor();// 钩子函数优雅关闭线程池this.shutdownHook = new Thread(() -> destroy());Runtime.getRuntime().addShutdownHook(shutdownHook);// 续期任务renewalWorkerId();}/*** 获取 workerId* 先采用随机策略,失败再采用顺序策略,上游给出降级方案* @return*/public synchronized Long registerAndGetWorkerId() {workerId = null;randomSetWorkerId();if (openSequenceSetWorkerId && workerId == null) {sequenceSetWorkerId();}return workerId;}/*** 随机策略* 取 0~1023 随机数* 终止条件:workerId 分配完成 或 或自旋次数大于 10*/private void randomSetWorkerId() {int times = 0;while (workerId == null && times ++ < 10) {long random = ThreadLocalRandom.current().nextLong(0, maxWorkerId);workerId = register(random);}}/*** 顺序策略* 从0开始分配,失败后自增1* 终止条件:workerId 分配完成 或 workerId 分配完*/private void sequenceSetWorkerId() {long preWorkId = 0;while (workerId == null) {workerId = register(preWorkId);// 如果机器号分配10位,workerId 分配范围 [0,1024)if (++ preWorkId >= maxWorkerId) {log.error("无可用 workerId!!!");return;}}}/*** 到 Redis 中注册 workId* @return 如果失败返回 null,成功直接将 workerId 返回*/private Long register(long workerId) {String key = buildSnowFlakeWorkerIdKey(appKey, workerId);try {if (redisTemplate.opsForValue().setIfAbsent(key, "1", renewalTime, TimeUnit.SECONDS)) {log.info("WorkerId={} register success", workerId);return workerId;}} catch (Exception e) {log.error("WorkerId register error", e);}return null;}/*** 续期 workerId*/private void renewalWorkerId() {service.scheduleWithFixedDelay(() -> {if (workerId != null) {String key = buildSnowFlakeWorkerIdKey(appKey, workerId);// 续期时再次set防止被Redis内存淘汰机制清理if (!redisTemplate.opsForValue().setIfAbsent(key, "1", renewalTime, TimeUnit.SECONDS)) {redisTemplate.expire(key, renewalTime, TimeUnit.SECONDS);}log.info("workerId={} 续期成功", workerId);}}, 3L, renewalIntervalTime, TimeUnit.SECONDS);}private String buildSnowFlakeWorkerIdKey(String appKey, Long workerId) {return String.format("snow_flake_worker_%s_%s", appKey, workerId);}/*** 删除机器号* 一般发生时间回拨且集群规模较大的情况下,机器号进行切换后考虑删除上一个机器号* @param workerId*/public void delWorkerId(Long workerId) {String key = buildSnowFlakeWorkerIdKey(appKey, workerId);redisTemplate.delete(key);}/*** 关闭线程池*/public void destroy() {service.shutdown();log.info("续期线程池关闭");// 这里不删除上报机器号防止重启时时间回退造成唯一id发放重复// 但是需要保证重启时间小于 renewalTime - renewalIntervalTime// 如果后期项目重启时间过长可以适当调大有效期}public String getAppKey() {return appKey;}public Long getWorkerId() {return workerId;}}
如果「上次时间戳」-「最新时间戳」大于 0 且小于等于 5 ms:Object.wait(两倍offset),等待一会再获取 ID; 如果「上次时间戳」-「最新时间戳」大于 5 ms:重新注册新机器号,再生成ID,即可保证ID不重复(熔断降级)。
package com.adong.fingermark.core;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.Objects;import java.util.concurrent.ThreadLocalRandom;/*** @author ADong* @Description 参考雪花算法实现分布式id* 1位正负位 + 41位时间戳 + 10位机器号 + 12位随机序列* 通过 Redis {@link WorkerIdManager#renewalWorkerId()}* 续期逻辑保证重启时不会注册上一个机器号来防止重启时的时间回拨问题* @Date 2022-08-15 4:24 PM*/public class SnowFlakeId implements IdGen {private static final Logger log = LoggerFactory.getLogger(SnowFlakeId.class);// 记录上次时间戳 41位private long lastTime = timeGen();// 机房机器ID 10位private long workerId = 0;private long workerIdShift = 10;// 随机数 12位private long random = 0;private long randomShift = 12;// 随机数的最大值private long maxRandom = (long) Math.pow(2, randomShift);private WorkerIdManager workerIdManager;public SnowFlakeId() {}public SnowFlakeId(long workerId, long workerIdShift, WorkerIdManager workerIdManager){if (workerIdShift < 0 || workerIdShift > 22) {throw new IllegalArgumentException("workerIdShift set error!");}this.workerId = workerId;this.workerIdShift = workerIdShift;this.randomShift = 22 - workerIdShift;this.maxRandom = (long) Math.pow(2, randomShift);this.workerIdManager = workerIdManager;log.info("SnowFlakeId init success, workerId={}", workerId);}// 通过位运算拼接获取 IDprivate long getId() {return lastTime << (workerIdShift + randomShift) |workerId << randomShift |random;}// 降级方案获取 idprivate long getBadId(long badRandom) {return lastTime << (workerIdShift + randomShift) |badRandom;}// 生成新 ID@Overridepublic synchronized long nextId() {long now = timeGen();//如果当前时间大于上次时间,直接返回if (now > lastTime) {lastTime = now;random = getRandom(100);return getId();}// 如果当前时间等于上次时间且random小于最大值随机序列if (now == lastTime && ++ random < maxRandom) {return getId();}// 判断如果回拨时间小于5ms或大于等于最大序列值就进行等待,否则进行降级方案long offset = lastTime - now == 0 ? 1 : lastTime - now;if (offset <= 5) {try {// 等待两倍offsetwait(offset << 1);} catch (InterruptedException e) {log.error("nextId wait interrupted");return getBadId(getBadMaxRandom());}} else {// 发生时间回拨切换机器号,失败兜底if (!changeWorkerId()) {return getBadId(getBadMaxRandom());}}now = timeGen();// 再次判断,如果时间还不符合进行降级方案if (now < lastTime) {return getBadId(getBadMaxRandom());} else {now = tilNextMillis(lastTime);}lastTime = now;random = getRandom(100);return getId();}private long tilNextMillis(long lastTime) {long now = timeGen();while (now <= lastTime) {now = timeGen();}return now;}/*** 如果发生时间回拨,重新注册机器号* 如果集群规模较大,机器号进行切换后考虑删除上一个机器号 {@link WorkerIdManager#delWorkerId(Long)}* @return 是否切换成功*/private boolean changeWorkerId() {if (!Objects.isNull(workerIdManager)) {Long changeWorkerId = workerIdManager.registerAndGetWorkerId();if (changeWorkerId != null) {workerId = changeWorkerId;lastTime = timeGen();// TODO 考虑是否清空上个机器号return true;}}return false;}// 降级方案获取最大随机序列位数private long getBadMaxRandom() {return getRandom((long) Math.pow(2, randomShift + workerIdShift));}// 根据最大限制获取随机序列private long getRandom(long bound) {return ThreadLocalRandom.current().nextLong(bound);}// 生成当前时间private long timeGen() {return System.currentTimeMillis();}@Overridepublic void destory() {if (!Objects.isNull(workerIdManager)) {workerIdManager.destroy();}}}
@Testpublic void testSerialUUID() {List<String> list = new ArrayList<>();Stopwatch stopwatch = Stopwatch.createStarted();for (int i = 0; i < 1000000; i++) {try {list.add(UUID.randomUUID().toString());} catch (Exception e) {log.error("get id error", e);}}log.info("set size={}, 耗时={}ms", new HashSet<>(list).size(), stopwatch.elapsed(TimeUnit.MILLISECONDS));}
set size=1000000, 耗时=3171ms
@Testpublic void testSerialSnowFlakeId() {List<Long> list = new ArrayList<>();Stopwatch stopwatch = Stopwatch.createStarted();for (int i = 0; i < 1000000; i++) {try {list.add(idGenManager.getId());} catch (Exception e) {log.error("get id error", e);}}log.info("set size={}, 耗时={}ms", new HashSet<>(list).size(), stopwatch.elapsed(TimeUnit.MILLISECONDS));}
set size=1000000, 耗时=701ms
 !
!
文章转载自阿东编程之路,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
