




一、说在前面
根据当时报错分析,事故原因应该是数据库意外断电,导致CKPT进程来不及更新文件头SCN号,从而造成文件头和文件块SCN号不一致,重启时Media Recovery恢复数据库,又因为DG缺失后续日志,从而报错(后面证明还有后半段原理没有搞清楚)。
但是对为何要把归档追至与主库一致才能开启数据库的原因一知半解,本次又出现了这个问题,借此打算弄的更加明白。
二、事情现场
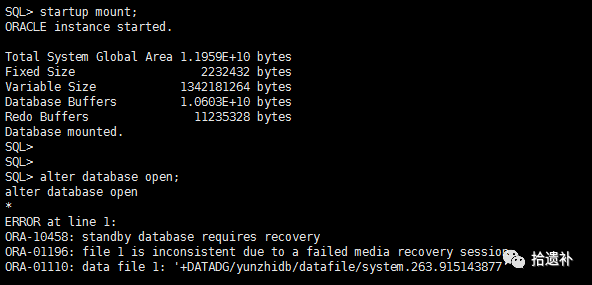
三、解决之道
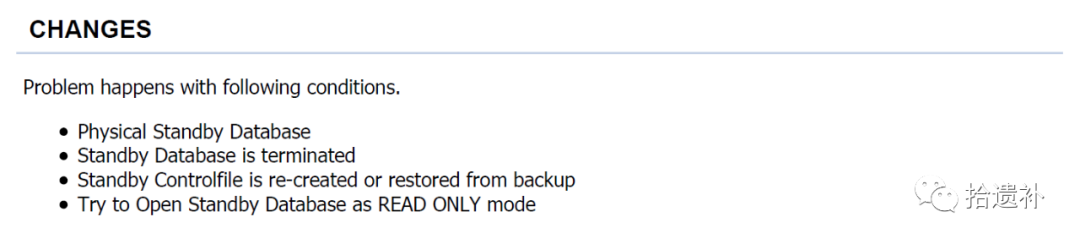
文档分析成因如下:

文档提供解决方案如下:

第一步,开启日志应用,确保MRP进程正常应用归档。
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
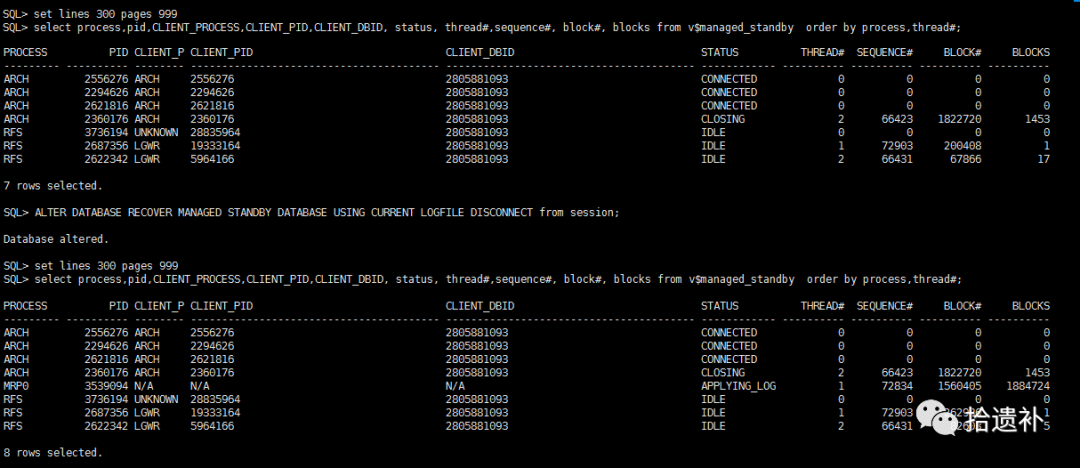
第二步,等待从库归档应用追平主库。(从库Alert log归档后出现in transit即为应用的归档为主库Redo中正在产生的)

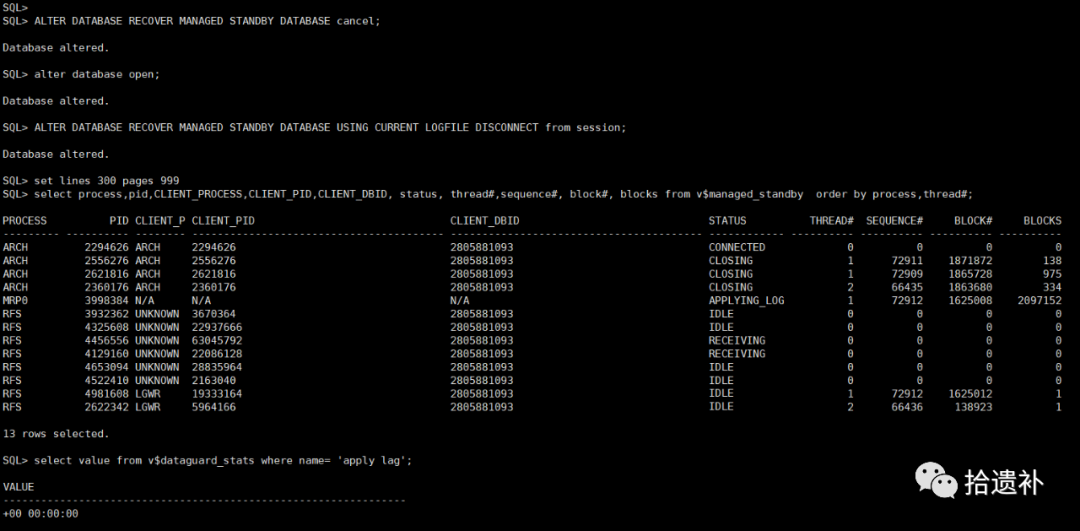
第三步,停止从库日志应用,开启数据库,然后恢复实时应用,拉起ADG。
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
SQL> ALTER DATABASE OPEN;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION;
四、更深层次的复盘
ORA-10458,ORA-01196,ORA-01110问题形成的原因是由于物理备库异常关闭,导致CKPT进程来不及更新文件头的SCN号,数据库Down的时候一部分文件头的Fuzzy bit状态仍为Open。当重新启动备库至Read Only状态的时候,对比SCN号后发现数据库需要Media Recovery,但是由于归档的缺失,Media Recovery失败,文件头的Fuzzy状态无法变更为No,故无法开启数据库。
Fuzzy标记位于数据文件头块Offset 138中。可以使用bbed进行查询,0x04表示Fuzzy为Yes,0x00表示Fuzzy为No。如果Fuzzy为Yes,那么说明数据块中的SCN大于数据文件头的SCN,此时就说明数据库异常关闭或者在Open状态,执行完Recover后,Fuzzy变为No,那么说明数据库应用日志后,数据文件头部的SCN应用日志后增长,此时数据文件头部SCN大于数据块中SCN,Fuzzy为No。
以下Alter日志证实了以上观点
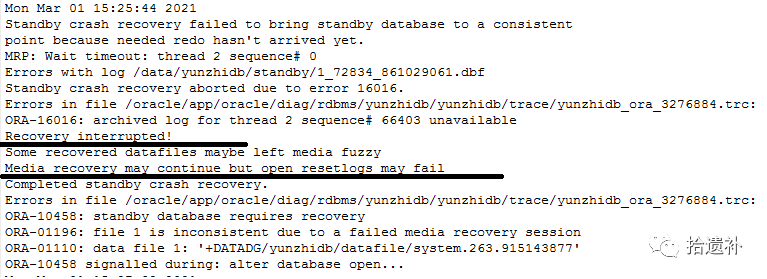
明白发生原理后,后面的操作的目地其实就一目了然了。开启日志应用是为了推进各文件头的SCN号,那什么时候将SCN号统一呢,结论出乎我的意料,SCN号统一状态的更改居然是停止日志应用操作触发的,如下图。
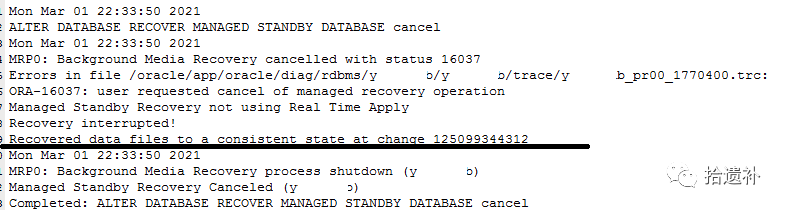
之后的Open操作触发的“SMON:enabling cache recovery”其实也很有意思。
在数据库正式Open前需要对字典缓存进行恢复,这个步骤被称为Cache Recovery,其实是Row Cache Recovery,与官方文档中描述的Cache Recovery不同,Row Cache Recovery应当是Oracle Internal的叫法。
同时实际执行Row Cache Recovery的不是SMON进程,而是启动实例的服务进程。在恢复完字典缓存后数据库即正常开启。

至此,研究结束,我满意了。
PS:在这篇文章求证阶段,借鉴了很多前辈的研究成果。一方面感叹老一辈DBA们的精益求精,一方面更加坚定了分享知识的念头,独木不成林,太阳底下无新鲜事,要努力。
