




安装规划
架构图
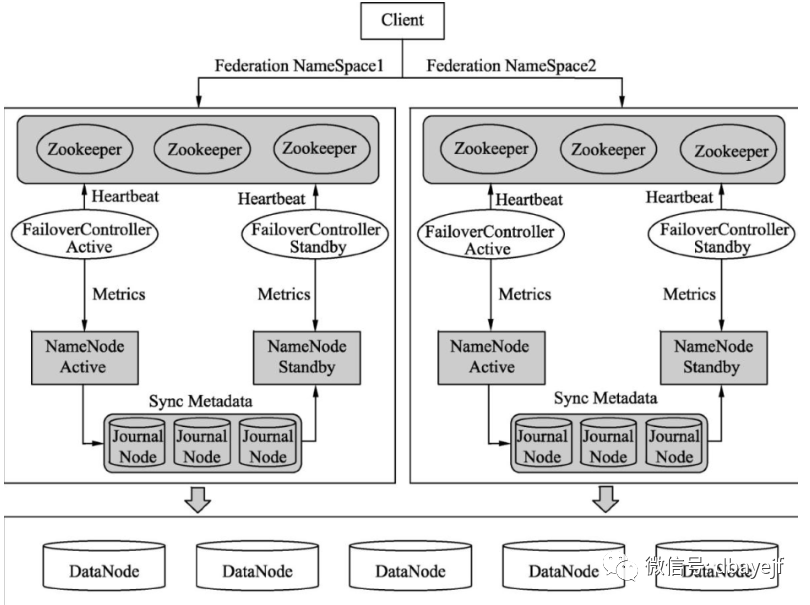
在任一时刻,只有一个NameNode处于active状态,另一个处于standby状态。其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。
为了确保快速切换,standby状态的NameNode有必要知道集群中所有数据块的位置。为了做到这点,所有的datanodes必须配置两个NameNode的地址,发送数据块位置信息和心跳给他们两个。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs必须确保同一时刻只有一个NameNode可以向自己写数据。
主机信息
| 主机名(ip) | 角色 | 内存 | CPU | 操作系统 |
|---|---|---|---|---|
| nna(192.168.43.128) | NameNode Active | 2GB | 2核 | redhat7.5 |
| nns(192.168.43.129) | NameNode Standby | 2GB | 2核 | redhat7.5 |
| dn1(192.168.43.130) | DataNode | 1GB | 1核 | redhat7.5 |
| dn2(192.168.43.131) | DataNode | 1GB | 1核 | redhat7.5 |
| dn3(192.168.43.132) | DataNode | 1GB | 1核 | redhat7.5 |
基础环境配置
配置hosts文件
192.168.43.128 nna
192.168.43.129 nns
192.168.43.130 dn1
192.168.43.131 dn2
192.168.43.132 dn3
安装jdk
下载地址
https://www.oracle.com/java/technologies/javase-downloads.html
查看系统是否有安装java依赖库,有就先删除
rpm -qa|grep java
解压包
jdk1.8.0_102.gz
到/usr/local/jdk1.8.0_102
,添加环境全局环境变量
# cat /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_102
export PATH=$PATH:$JAVA_HOME/bin
验证java安装是否成功
[hadoop@nna jdk1.8.0_102]$ java -version
java version "1.8.0_102"
Java(TM) SE Runtime Environment (build 1.8.0_102-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.102-b14, mixed mode)
同步java安装目录及环境变量到各台服务器
创建hadoop用户及配置互信
创建hadoop用户 (过程略)
为hadoop用户配置互信免密(过程略)
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
修改时区
[root@nna ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
[root@nna ~]# date -R
Wed, 27 Jan 2021 09:50:24 +0800
Zookeeper部署
官网下载
https://zookeeper.apache.org/releases.html
这里使用的版本是zookeeper-3.4.5.tar.gz
,解压到/usr/local/zookeeper-3.4.5
,并添加环境变量
# cat /etc/profile
ZK_HOME=/usr/local/zookeeper-3.4.5
export PATH=$PATH:$ZK_HOME/bin
配置zoo.cfg文件 ,服务端口设置2181,服务节点使用datanode节点,即dn1、dn2、dn3
cp /usr/local/zookeeper-3.4.5/conf/zoo_sample.cfg
#vi zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zkdata
clientPort=2181
server.1=dn1:2888:3888
server.2=dn2:2888:3888
server.3=dn3:2888:3888
在各服务节点创建对应的数据目录/data/zkdata
,而且需要在配置的dataDir
目录下面创建一个myid文件,写入一个0~255之间的整数,实际如下:
[root@dn1 zkdata]# cat myid
1
[root@dn2 zkdata]# cat myid
2
[root@dn3 zkdata]# cat myid
3
同步zookeeper安装目录及环境变量到各台服务器然后在不同节点上启动zookeeper服务
[hadoop@dn1 ~]$ zkServer.sh start
[hadoop@dn2 ~]$ zkServer.sh start
[hadoop@dn3 ~]$ zkServer.sh start
验证zookeeper运行
jps命令显示QuorumPeerMain
进程
[hadoop@dn1 ~]$ jps
37425 Jps
29736 QuorumPeerMain
在zookeeper集群运行正常情况下,3个节点中会选举出一个leader和两个follower
[hadoop@dn1 ~]$ zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
[hadoop@dn2 ~]$ zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: leader
[hadoop@dn3 ~]$ zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.5/bin/../conf/zoo.cfg
Mode: follower
hadoop部署
官网下载
https://hadoop.apache.org/releases.html
这里使用版本hadoop-2.7.4.tar.gz
解压到/usr/local/hadoop-2.7.4
,并修改环境变量
# cat /etc/profile
HADOOP_HOME=/usr/local/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置核心文件
在目录$HADOOP_HOME/etc/hadoop
下,主要是有以下几个:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
yarn-env.sh
core-site.xml
用于配置hadoop临时目录,服务地址,序列文件缓冲区大小等属性
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定分布式文件存储系统(HDFS)的NameService为cluster1,是NameNode的URI -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<!-- 用于序列文件缓冲区的大小,这个缓冲区的大小可能是硬件页面大小的倍数,它决定了在读写 操作期间缓冲了多少数据 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!--指定可以在任何IP访问 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!--指定所有账号可以访问 -->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<!-- 指定ZooKeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
hdfs-site.xml
用于配置hadoop集群分布式文件系统别名、通信地址、端口信息,以及访问集群健康状态,文件存储详情页面地址等属性
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定HDFS的NameService为cluster1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!-- cluster1下面有两个NameNode,分别是nna节点和nns节点 -->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nna,nns</value>
</property>
<!-- nna节点的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nna</name>
<value>nna:9000</value>
</property>
<!-- nns节点的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nns</name>
<value>nns:9000</value>
</property>
<!-- nna节点的HTTP通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nna</name>
<value>nna:50070</value>
</property>
<!-- nns节点的HTTP通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nns</name>
<value>nns:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>
qjournal://dn1:8485;dn2:8485;dn3:8485/cluster1
</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免密码登录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/tmp/journal</value>
</property>
<!--指定支持高可用自动切换机制 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定NameNode名称空间的存储地址 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/dfs/name</value>
</property>
<!--指定DataNode数据存储地址 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dfs/data</value>
</property>
<!-- 指定数据冗余份数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定可以通过Web访问HDFS目录 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 保证数据恢复,通过0.0.0.0来保证既可以内网地址访问,也可以外网地址访问 -->
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<!-- 通过ZKFailoverController来实现自动故障切换 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
mapred-site.xml
用于配置hadoop计算任务的构架名称,历史任务访问地址等信息
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 计算任务托管的资源框架名称 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置 MapReduce JobHistory Server 地址,默认端口10020 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 配置 MapReduce JobHistory Server Web 地址,默认端口19888 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
yarn-site.xml
用于hadoop集群的资源管的分配、作业的调度与监控及数据共享等
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- RM(Resource Manager)失联后重新连接的时间 -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!-- 开启Resource Manager HA,默认为false -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 配置Resource Manager -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!-- 开启故障自动切换 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- rm1配置开始 -->
<!-- 配置Resource Manager主机别名rm1角色为NameNode Active-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nna</value>
</property>
<!-- 配置Resource Manager主机别名rm2角色为NameNode Standby-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nns</value>
</property>
<!-- 在nna上配置rm1,在nns上配置rm2,将配置好的文件同步到其他节点上,但在yarn的另一个机器上一定要修改 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 开启自动恢复功能 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置与zookeeper的连接地址 -->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!--用于持久化RM(Resource Manager的简称)状态存储,基于Zookeeper实现 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
</value>
</property>
<!-- Zookeeper地址用于RM实现状态存储,以及HA的设置-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!-- 集群ID标识 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1-yarn</value>
</property>
<!-- schelduler失联等待连接时间 -->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- 配置rm1,其应用访问管理接口 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nna:8132</value>
</property>
<!-- 调度接口地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nna:8130</value>
</property>
<!-- RM的Web访问地址 -->
<property>
<name>
yarn.resourcemanager.webapp.address.rm1
</name>
<value>nna:8188</value>
</property>
<property>
<name>
yarn.resourcemanager.resource-tracker.address.rm1
</name>
<value>nna:8131</value>
</property>
<!-- RM管理员接口地址 -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nna:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>nna:23142</value>
</property>
<!-- rm1配置结束 -->
<!-- 配置rm2,与rm1配置一致,只是将nna节点名称换成nns节点名称 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nns:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nns:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nns:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nns:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nns:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>nns:23142</value>
</property>
<!-- rm2配置结束 -->
<!-- NM(NodeManager的简称)的附属服务,需要设置成mapreduce_shuffle才能运行 MapReduce任务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置shuffle处理类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- NM本地文件路径 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<!-- NM日志存放路径 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/log/yarn</value>
</property>
<!-- ShuffleHandler运行服务端口,用于Map结果输出到请求Reducer -->
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!-- 故障处理类 -->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>
org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
</value>
</property>
<!-- 故障自动转移的zookeeper路径地址 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
<!-- 查看任务调度进度,在nns节点上需要将访问地址修改为http://nns:9001 -->
<property>
<name>mapreduce.jobtracker.address</name>
<value>http://nna:9001</value>
</property>
<!--启动聚合操作日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--指定日志在HDFS上的路径 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<!-- 指定日志在HDFS上的路径 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<!-- 聚合后的日志在HDFS上保存多长时间,单位为秒,这里保存72小时 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>259200</value>
</property>
<!-- 删除任务在HDFS上执行的间隔,执行时候将满足条件的日志删除 -->
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
</property>
<!--RM浏览器代理端口 -->
<property>
<name>yarn.web-proxy.address</name>
<value>nna:8090</value>
</property>
<!-- 配置Fair调度策略指定类
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
</value>
</property>
-->
<!-- 启用RM系统监控 -->
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<!-- 物理内存和虚拟内存比率 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.2</value>
</property>
</configuration>
hadoop-env.sh
和yarn-env.sh
文件添加JAVA_HOME的路径
JAVA_HOME=/usr/local/jdk1.8.0_102
尽管文件内容有JAVA_HOME=$JAVA_HOME也需要添加
编辑slaves文件
添加DataNode节点的主机名
[root@nna hadoop]# cat slaves
dn1
dn2
dn3
同步安装目录及配置
把修改的环境变量和安装目录同步到其它服务器
[hadoop@nna ~]$ scp -r /usr/local/hadoop-2.7.4 xxx@/usr/local/
启动集群
修改所安装的软件用户组和主用户为hadoop,使用hadoop用户启动集群。
初次启动
启动Zookeeper服务(前面已启动)
启动
journalnode
进程#在NameNode节点上执行
[hadoop@nna ~] hadoop-daemons.sh start journalnode
#或在DataNode节点上执行
[hadoop@dn1 ~] hadoop-daemon.sh start journalnode
[hadoop@dn2 ~] hadoop-daemon.sh start journalnode
[hadoop@dn3] hadoop-daemon.sh start journalnode格式化NameNode节点 (初次启动时需要格式化)
[hadoop@nna ~] hdfs namenode -format向zookeeper注册ZNode
[hadoop@nna ~] hdfs zkfc -formatZK启动分布式文件系统(HDFS)
[hadoop@nna ~] start-hdfs.sh启动yarn服务进程
[hadoop@nna ~] start-yarn.sh在nns节点上同步nna节点的元数据信息
[hadoop@nns ~] hdfs namenode -bootstraStandby启动nns节点上的NameNode和ResourceManager进程
[hadoop@nns ~] hadoop-daemon.sh start namenode
[hadoop@nns ~] yarn-daemon.sh start resourcemanager
hadoop访问地址:
http://192.168.43.128:50070/

yarn(资源管理调度)访问地址:
http://192.168.43.128:8188
日常启停
平时启动时,只需要在NameNode上执行命令启动即可
# 分别启停hdfs和yarn
[hadoop@nna ~]$ start-dfs.sh
[hadoop@nna ~]$ start-yarn.sh
[hadoop@nna ~]$ stop-dfs.sh
[hadoop@nna ~]$ stop-yarn.sh
#或者同时启动
[hadoop@nna ~]$ start-all.sh
[hadoop@nna ~]$ stop-all.sh
启动日志
[hadoop@nna ~]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [nna nns]
nna: starting namenode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-namenode-nna.out
nns: starting namenode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-namenode-nns.out
dn1: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-datanode-dn1.out
dn3: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-datanode-dn3.out
dn2: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-datanode-dn2.out
Starting journal nodes [dn1 dn2 dn3]
dn1: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-journalnode-dn1.out
dn2: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-journalnode-dn2.out
dn3: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-journalnode-dn3.out
Starting ZK Failover Controllers on NN hosts [nna nns]
nna: starting zkfc, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-zkfc-nna.out
nns: starting zkfc, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-zkfc-nns.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-hadoop-resourcemanager-nna.out
dn3: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-hadoop-nodemanager-dn3.out
dn2: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-hadoop-nodemanager-dn2.out
dn1: starting nodemanager, logging to /usr/local/hadoop-2.7.4/logs/yarn-hadoop-nodemanager-dn1.out
停止日志
[hadoop@nna ~]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [nna nns]
nna: stopping namenode
nns: stopping namenode
dn1: stopping datanode
dn3: stopping datanode
dn2: stopping datanode
Stopping journal nodes [dn1 dn2 dn3]
dn1: stopping journalnode
dn3: stopping journalnode
dn2: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [nna nns]
nna: stopping zkfc
nns: stopping zkfc
stopping yarn daemons
stopping resourcemanager
dn3: stopping nodemanager
dn1: stopping nodemanager
dn2: stopping nodemanager
no proxyserver to stop
集群验证
常用命令验证
[hadoop@nna ~]$ echo test >text.tmp
[hadoop@nna ~]$ hdfs dfs -mkdir /test
[hadoop@nna ~]$ hdfs dfs -put text.tmp /test
[hadoop@nna ~]$ hdfs dfs -cat /test/text.tmp
test
[hadoop@nna ~]$ hdfs dfs -ls /test/
Found 1 items
-rw-r--r-- 2 hadoop supergroup 5 2021-01-27 11:13 /test/text.tmp
[hadoop@nna ~]$ hdfs dfs -get /test/text.tmp
get: `text.tmp': File exists
[hadoop@nna ~]$ rm text.tmp
[hadoop@nna ~]$ hdfs dfs -get /test/text.tmp
[hadoop@nna ~]$ hdfs dfs -rm /test/text.tmp
21/01/27 11:14:38 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /test/text.tmp
HA验证
查看节点的状态
[hadoop@nna ~]$ hdfs haadmin -getServiceState nna
active
[hadoop@nna ~]$ hdfs haadmin -getServiceState nns
standby
在nna节点上杀掉服务进程
[hadoop@nna ~]$ jps
24179 ResourceManager
24084 DFSZKFailoverController
24984 Jps
23773 NameNode
[hadoop@nna ~]$ kill -9 23773
再次查看状态,nns节点已变成active
[hadoop@nna ~]$ hdfs haadmin -getServiceState nna
21/01/27 11:17:03 INFO ipc.Client: Retrying connect to server: nna/192.168.43.128:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From nna/192.168.43.128 to nna:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[hadoop@nna ~]$ hdfs haadmin -getServiceState nns
active
再验证集群,还可以正常使用
[hadoop@nna ~]$ hdfs dfs -put text.tmp /test
[hadoop@nna ~]$ hdfs dfs -ls /test
Found 1 items
-rw-r--r-- 2 hadoop supergroup 5 2021-01-27 11:18 /test/text.tmp
再次启动nna的namdnode服务后,变成standby状态
[hadoop@nna ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-hadoop-namenode-nna.out
[hadoop@nna ~]$ hdfs haadmin -getServiceState nna
standby
YARN验证
workcount例子
hdfs上的文本数据
[hadoop@nna ~]$ hdfs dfs -cat /tmp/work.txt
a b c d
a b c
a b
abcd
运行日志
[hadoop@nna ~]$ hadoop jar /usr/local/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar wordcount /tmp/work.txt /out
21/01/27 15:55:06 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
21/01/27 15:55:06 INFO input.FileInputFormat: Total input paths to process : 1
21/01/27 15:55:06 INFO mapreduce.JobSubmitter: number of splits:1
21/01/27 15:55:06 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1611715839374_0001
21/01/27 15:55:07 INFO impl.YarnClientImpl: Submitted application application_1611715839374_0001
21/01/27 15:55:07 INFO mapreduce.Job: The url to track the job: http://nna:8090/proxy/application_1611715839374_0001/
21/01/27 15:55:07 INFO mapreduce.Job: Running job: job_1611715839374_0001
21/01/27 15:55:19 INFO mapreduce.Job: Job job_1611715839374_0001 running in uber mode : false
21/01/27 15:55:19 INFO mapreduce.Job: map 0% reduce 0%
21/01/27 15:55:28 INFO mapreduce.Job: map 100% reduce 0%
21/01/27 15:55:38 INFO mapreduce.Job: map 100% reduce 100%
21/01/27 15:55:39 INFO mapreduce.Job: Job job_1611715839374_0001 completed successfully
21/01/27 15:55:39 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=49
FILE: Number of bytes written=252023
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=118
HDFS: Number of bytes written=23
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7461
Total time spent by all reduces in occupied slots (ms)=6547
Total time spent by all map tasks (ms)=7461
Total time spent by all reduce tasks (ms)=6547
Total vcore-milliseconds taken by all map tasks=7461
Total vcore-milliseconds taken by all reduce tasks=6547
Total megabyte-milliseconds taken by all map tasks=7640064
Total megabyte-milliseconds taken by all reduce tasks=6704128
Map-Reduce Framework
Map input records=6
Map output records=10
Map output bytes=63
Map output materialized bytes=49
Input split bytes=93
Combine input records=10
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=49
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=168
CPU time spent (ms)=1300
Physical memory (bytes) snapshot=283291648
Virtual memory (bytes) snapshot=4158140416
Total committed heap usage (bytes)=143081472
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=25
File Output Format Counters
Bytes Written=23
运行结果
[hadoop@nna mapreduce]$ hdfs dfs -ls /out
Found 2 items
-rw-r--r-- 2 hadoop supergroup 0 2021-01-27 15:55 /out/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 23 2021-01-27 15:55 /out/part-r-00000
[hadoop@nna mapreduce]$ hdfs dfs -cat /out/part-r-00000
a 3
abcd 1
b 3
c 2
d 1
安装过程中遇到的问题及解决
HA验证时,切换Namenode报错
tail -100 /usr/local/hadoop-2.7.4/logs hadoop-hadoop-zkfc-nns.log
2018-08-04 22:48:35,127 ERROR org.apache.hadoop.ha.NodeFencer: Unable to fence service by any configured method.
解决方法:
安装psmisc
yum install psmisc
nns启动resourcemanager服务报错
yarn-daemon.sh start resourcemanager
tail -100 /usr/local/hadoop-2.7.4/logs/yarn-hadoop-resourcemanager-nns.log
...
2021-01-26 00:10:18,547 INFO org.apache.hadoop.service.AbstractService: Service ResourceManager failed in state STARTED; cause: org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server
...
Caused by: java.net.BindException: Port in use: nna:8188
解决方法:
修改配置文件yarn-site.xml
<!-- 在nna上配置rm1,在nns上配置rm2,将配置好的文件同步到其他节点上,但在yarn的另一个机器上一定要修改 -->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
上传文件报错
hadoop-hadoop-namenode-nna.log:java.io.IOException: File /tmp._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
原因:
namenodee有多次的格式化
解决方法:
删除namenode配置的存储文件
[hadoop@nna ~]$ rm -rf /data/hadoop/dfs/name/*
[hadoop@nns ~]$ rm -rf /data/hadoop/dfs/name/*
然后重新格式化,就可以正常使用hdfs了
