




点亮 ⭐️ Star · 照亮开源之路



汪洋 Shopee 数据基础架构团队
Spark 应用程序开发专家
在 Apache SeaTunnel (Incubating) & Shopee 联合 Meetup 期间,Shopee 数据基础架构团队 Spark 应用程序开发专家 汪洋讨论了 Shopee 其为何选择 Apache SeaTunnel 作为他们的新数据集成框架以及如何将 SeaTunnel 集成到他们的数据管道中。
01
我们面临的问题

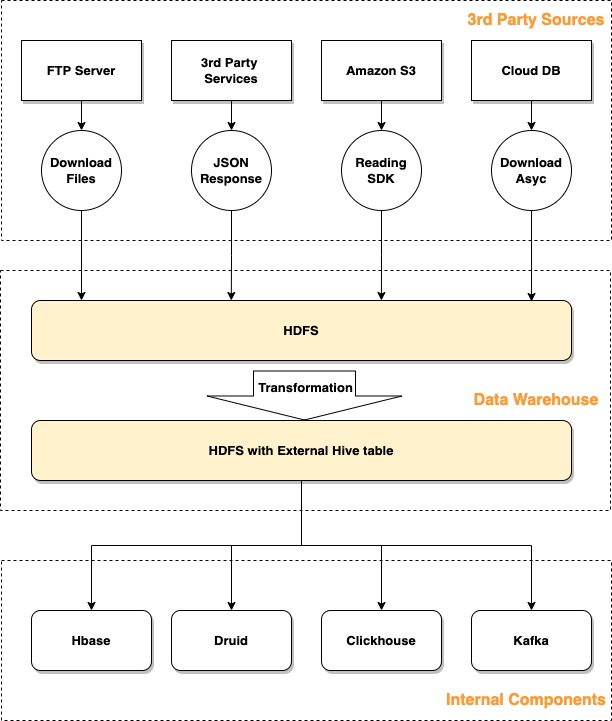
对用户不友好 维护过程不透明 需要长时间等待请求完成 目标表需要用户手动请求和创建,数据存储之间的数据转换需要具有开发能力的用户手动完成。 对于开发人员来说效率不高 自建数据转换管道不可复现、耗时长且难以调试 维护工作量大 其他问题 数据处理工作量大,BI 团队无法在短时间内建立数据仓库,导致 BI 团队仍在使用原始数据 以非标准方式处理每个任务数据,缺乏统一的数据指标管理
02
为什么选择 Apache SeaTunnel
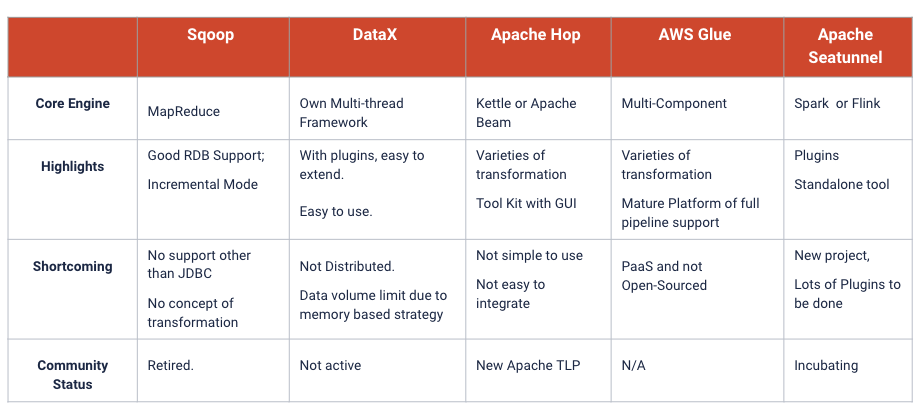

易于编辑配置并开箱即用地运行作业。 支持 Spark 或 Flink 引擎。 可以添加和更新 Source/ Sink Connector。 社区非常活跃。
03
使用内部 SeaTunnel 版本进行重构
一个上传 SeaTunnel jar 文件的地方,且部署前必须经过测试。 在测试期间,用户需要创建并更新 SeaTunnel 的应用程序配置文件。 此外,团队合作和管理很重要,用户应该能够与团队成员分享他们的工作。
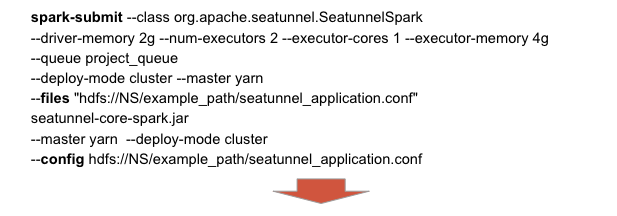
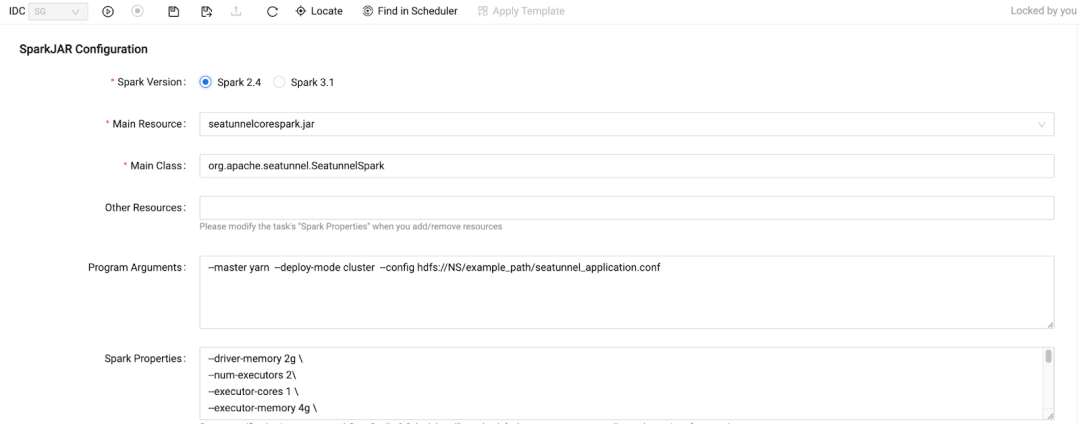
许多终端用户不熟悉 Linux 命令行,运行和调试可能是一场噩梦; 每个成员只能访问自己的目录,团队成员合作是不可行的; 在 Spark Driver 中很难对 yarn queue 等设置进行权限控制。
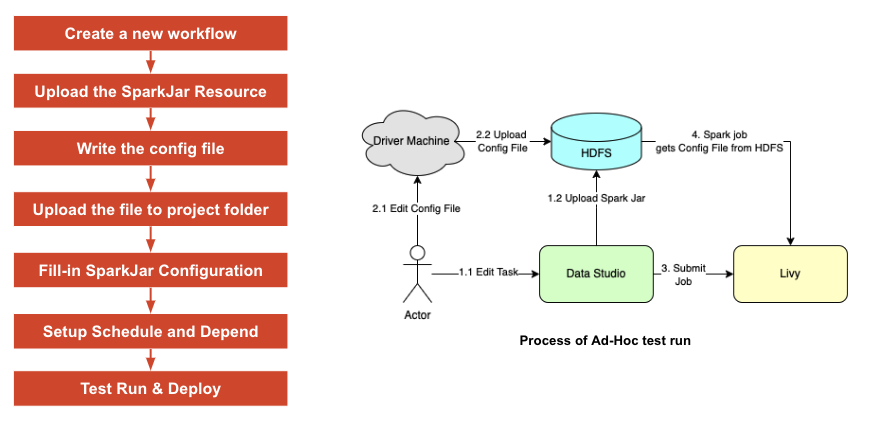
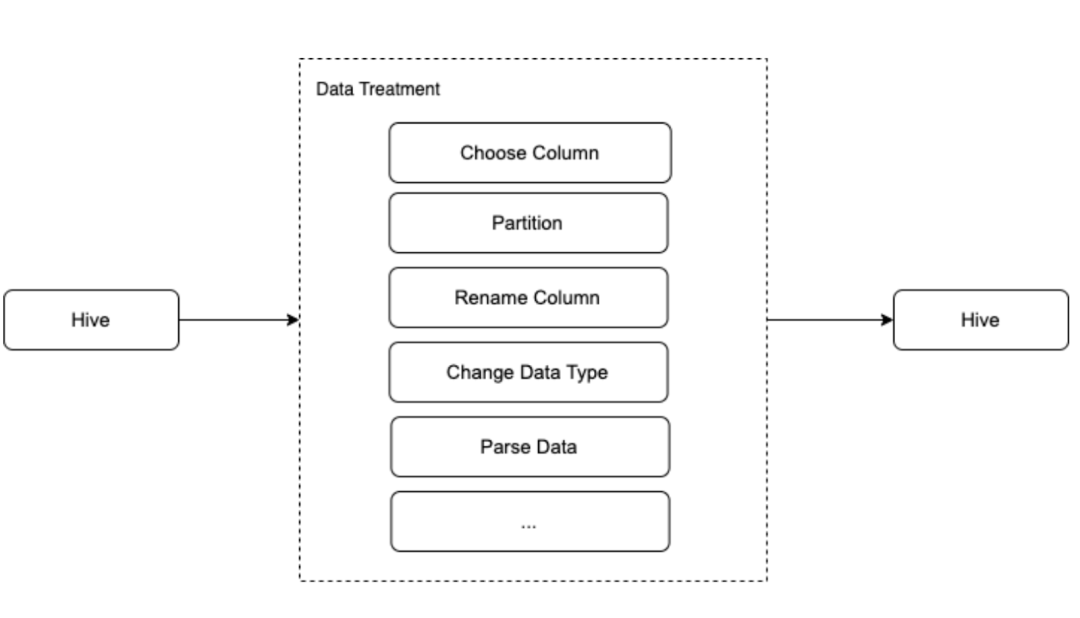
问题 1 DataStudio 仅支持上传小于 200MB 的 jar。 降低下载和上传负担。 解决方案 通过排除不必要的连接器和依赖项,尽可能多地构建更小的 jar。 问题 2 内部组件版本与 SeaTunnel 官方支持版本不同,如 Elastic-Search 和 HBase 解决方案 更新相关的 POM 依赖并重新编译。 问题 3 我们的 HDFS 路径在数据管理下,用户只能在特定路径上创建外部 Hive 表。 Hive sink 只会在默认路径下创建托管 Hive 表。 解决方案 从 HDFS Spark sink 扩展一个名为 HdfsHiveTable Extended 的新 Spark sink connector。 问题 4 一些用户无法访问驱动程序机器,无法将配置文件上传到 HDFS 解决方案: 提供了一种管理应用程序配置的新方法,使用户能够直接在 DatatStudio 中上传 JSON 字符串,而不是配置文件。
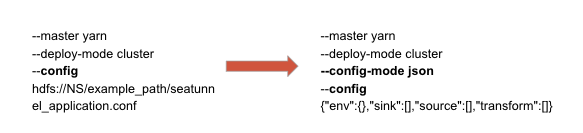
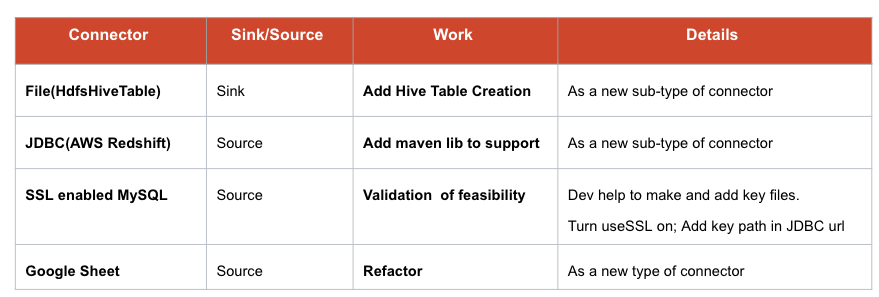
重用 config 变量:如果 config mode 是 json,那么可以用一个小型离线工具将 config 解析为 json 字符串,而不是 config 文件的路径。对于旧版本的 SeaTunnel,这似乎是唯一可行的方法。在最新版本中,SeaTunnel 提供了一种解析此配置变量的新方法。 问题 5 用户需要更多类型的 connector 解决方案 部署 File、JDBC(AWS Redshift)、SSL enabled MySQL、Google sheet等。

使用 SeaTunnel 重新部署原来的传输组件。 重构相关服务以降低复杂性。 迁移历史作业
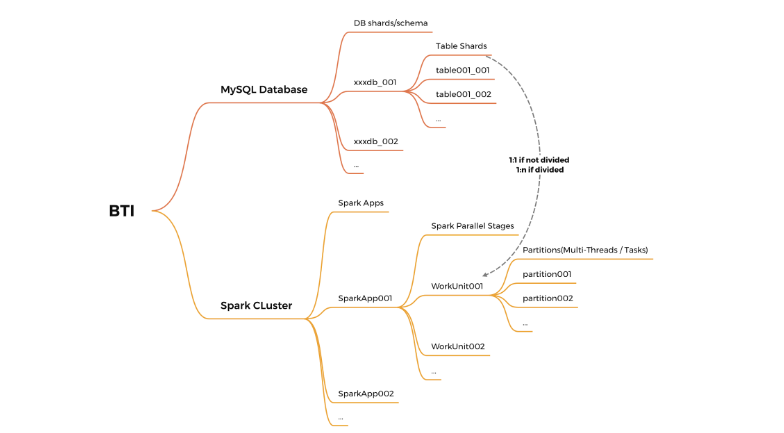
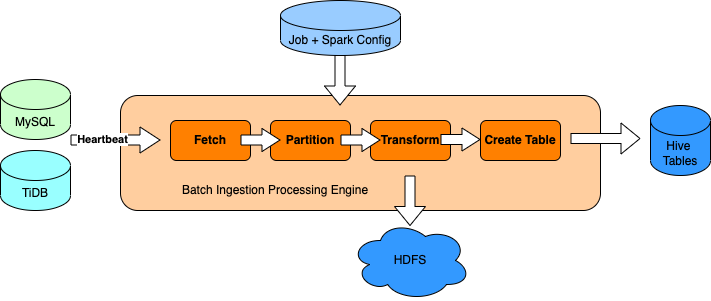
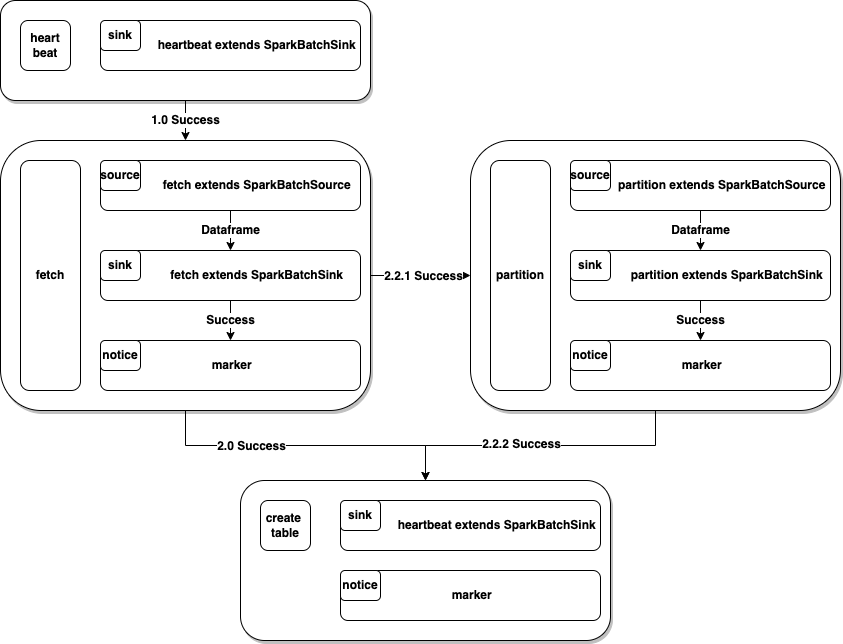


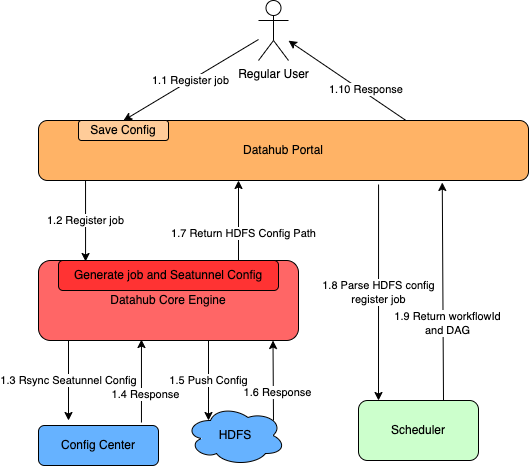
04
基于 SeaTunnel 构建 ETL 产品
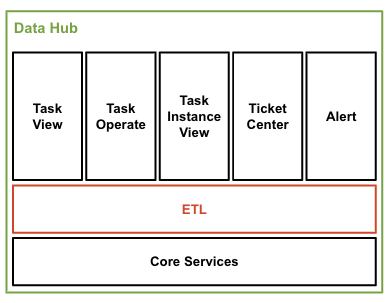

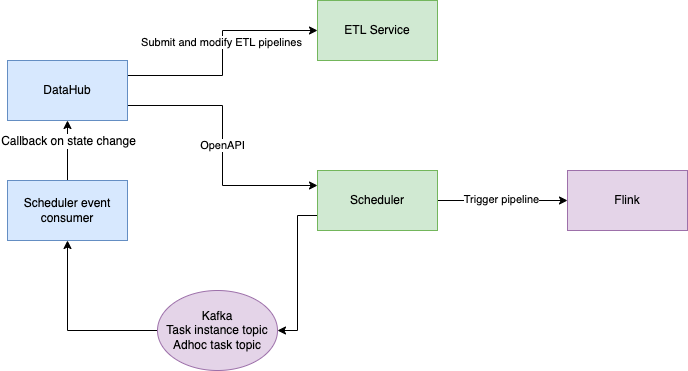

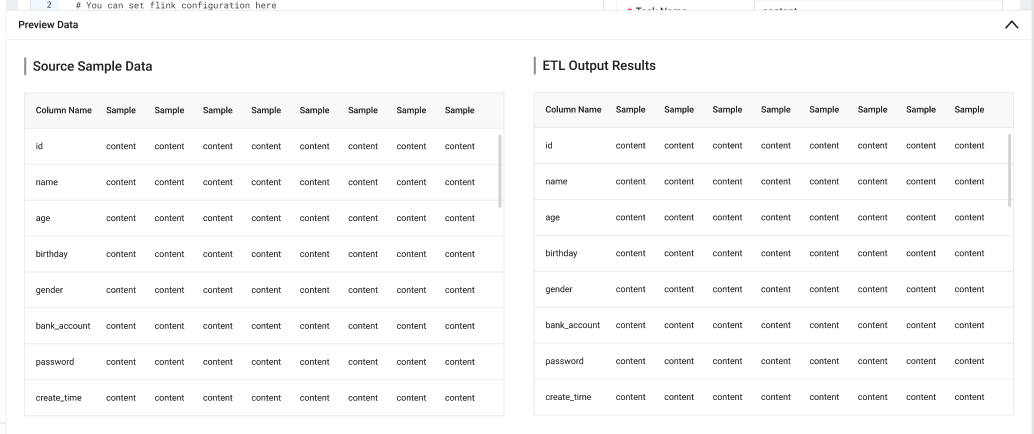

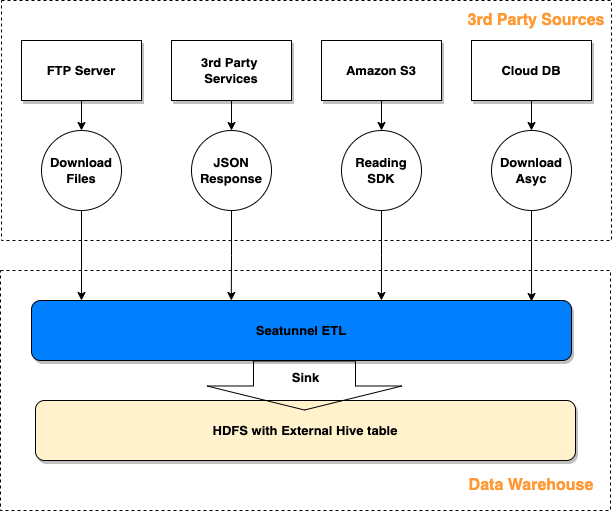




06
总结
在短期内: 可以很快解决我们遇到的问题 长期来看: 从开发人员的角度来看:它们应该可以减轻并加速管理各种获取请求的负担。 从用户的角度来看,它们应该提供新的和易于使用的功能。
Apache SeaTunnel

往期推荐
点击“阅读原文”参与活动

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
