




gptransfer使用介绍
gptransfer迁移工具把Greenplum数据库元数据和数据从一个Greenplum数据库传输到另一个Greenplum数据库,允许用户迁移整个数据库的内容或者选中的表到另一个数据库。源数据库和目标数据库可以在相同或者不同的集群中。gptransfer在所有Segment间并行地移动数据,它使用gpfdist数据装载工具以获得最高的传输率。
数据交互流程如下:
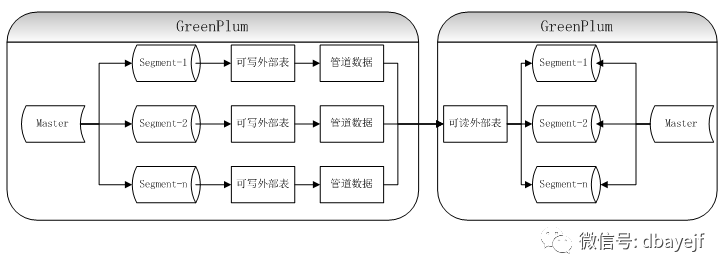
使用参数:
-a
不提示用户进行确认
--analyze
在非系统表上运行ANALYZE命令。默认是不运行
--base-port=
在源库上的gpfdist的基础端口。如果未指定,则默认是8000
--batch-size=
设置gptransfer并发传输表的数量。如果没有指定默认值是2,的最大的是10
-d
可以多次指定此选项将多个数据库复制到目标数据库。
如果源数据库不存在,则报错。如果目标数据库不存在,则创建数据库
--delimiter=
指定外部表的分隔符,默认是逗号(,)
如果--delimiter, --format, 和 --quote 没有设置,则用以下格式
FORMAT 'CSV' ( DELIMITER ',' QUOTE E'\001' )
--dest-database=
目标数据库名,如果没指定则跟源库同名
--dest-host=
目标库IP地址,默认127.0.0.1
--dest-port=
目录库端口,默认5432
--dest-user=
目标库用户,默认gpadmin
--drop
在目标库先删除表。
skip-existing, --truncate 和 --drop只有有一个选项
--dry-run
显示执行过程日志,但不进行数据库迁移
-f
指定迁移表的列表文件,对于视图和系统表无效,不能和--full、-d、-t参数共用
-F
不进行迁移表的列表文件
--format=[CSV | TEXT]
指定外部表的文件类型,如果指定的参数有--format=TEXT --delimiter=delim,那么外部表格式为
FORMAT 'TEXT' ( DELIMITER delim ESCAPE 'off' )
--full
完整迁移所有数据库对象,包括表、索引、所有用户定义的视图、用户、角色、函数和资源队列库。除了默认的数据库postgres、template0和template1。
如果一个数据库有很多表和数据时,不建议用这选项。
-l
指定日志目录,默认是 ~/gpAdminLogs
--max-line-length=
指定gpfdist的数据长度,默认是10MB,范围是32k到256MB
--no-final-count
禁用gptransfer之后执行的表行数验证,默认是验证
-q | --quiet
如果指定,则不打印日志消息,只发送到日志文件
--quote=
指定CSV格式的引号字符("csv"),默认是 \001
--schema-only
只迁移模式结构,不包括数据。
如果同时也指定了--full,那么则gptransfer会迁移数据库模式,包括所有表、索引、视图、用户定义源数据库的类型(UDT)和用户定义函数(UDF),但不传输任何数据。
如果同时指定了-t或-f选项,那么gptransfer只创建表和索引。没有传输任何数据。
不建议使用此模式迁移大量的表结构,因为占用太多资源了。
--skip-existing
如果指定此选项,则跳过从源数据库迁移的表在目标数据库中已经存在的表
--source-host=
源库IP地址,默认127.0.0.1
--source-map-file=
主机名和IP地址的配置文件,格式为:
sdw1,172.168.2.1
sdw2,172.168.2.2
sdw3,172.168.2.3
sdw4,172.168.2.4
--source-port=
源库端口,默认5432
--source-user=
源库用户,默认gpadmin
--sub-batch-size=
指定用于传输一个表的并行子进程的最大数目。默认值是25,最大值是50。
每个线程是一个Python进程并且会消耗内存,因此把这些值设置得太高可能会导致Python Out of Memory错误。
-t
指定需要的迁移的
数据库.模式名.表名
-T
指定不需要的迁移的
数据库.模式名.表名
--timeout
指定超时时间,默认300秒,范围是2秒到600秒。
--truncate
同步表时把目标库的表先truncate
--validate=
对表数据的验证方法,有两种:count 和 MD5。
如果对表的验证失败,则gptransfer将显示表并将文件名写入文件failed_migrated_tables_.txt
-v | --verbose
将日志记录级别设置为verbose,显示详细日志(包括执行命令)
--work-base-dir=
指定临时目录,默认是主目录
-x
在迁移过程中获取对表的排他锁以防止插入或更新。
如果-x没启用但--validate启用了,迁移过程中源数据有变动的话会导致迁移失败。
--version
显示版本信息
前提条件
两个集群中的每一台主机必须能够SSH免密连接到其他每一台主机。
两个集群中的Segment主机必须有网络连接彼此。
源和目的Greenplum集群必须为4.2及以上版本。
测试数据库环境信息
| 数据库 | 主机名 | IP |
|---|---|---|
| GP4 | sdw3 | 192.168.43.175 |
| GP5 | sdw4 | 192.168.43.176 |
修复GP4同步到GP5的gptransfer问题
创建source-map-file
配置文件
[gpadmin@sdw3 makedata]$ cat source_hosts
sdw3,192.168.43.175
GP4上生成数据
[gpadmin@sdw3 makedata]$ sh create_table_data.sh
create table test1
INSERT 0 100000
[gpadmin@sdw3 makedata]$ psql sdw3 -ac "select a,count(*) from test1 group by a;"
select a,count(*) from test1 group by a;
a | count
------+--------
sdw3 | 100000
(1 row)
在sdw3上执行,使用GP4的gptransfer同步到GP5
[gpadmin@sdw3 makedata]$ gptransfer -t sdw3.public.test1 --dest-host=sdw4 --source-map-file=source_hosts --truncate --dest-port=5555
20200318:13:32:17:046882 gptransfer:sdw3:gpadmin-[INFO]:-Starting gptransfer with args: -t sdw3.public.test1 --dest-host=sdw4 --source-map-file=source_hosts --truncate --dest-port=5555
20200318:13:32:17:046882 gptransfer:sdw3:gpadmin-[INFO]:-Validating options...
20200318:13:32:17:046882 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database...
20200318:13:32:17:046882 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database...
20200318:13:32:18:046882 gptransfer:sdw3:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist
LINE 2: ... SELECT dbid, content, status, unnest(san_mounts...
^
' in '
SELECT dbid, content, status, unnest(san_mounts)
FROM pg_catalog.gp_segment_configuration
WHERE content >= 0
ORDER BY content, dbid
'') exiting...
报错,因为GP4和5的系统表有变动,为了能够正常使用GP4的gptransfer,对源码脚本gparray.py
作修改。
原来代码
san_segs_rows = dbconn.execSQL(conn, '''
SELECT dbid, content, status, unnest(san_mounts)
FROM pg_catalog.gp_segment_configuration
WHERE content >= 0
ORDER BY content, dbid
''')
san_rows = dbconn.execSQL(conn, '''
SELECT mountid, active_host, san_type,
primary_host, primary_mountpoint, primary_device,
mirror_host, mirror_mountpoint, mirror_device
FROM pg_catalog.gp_san_configuration
ORDER BY mountid
''')
修改成
san_segs_rows = dbconn.execSQL(conn, '''
SELECT dbid, content, status,null-- unnest(san_mounts)
FROM pg_catalog.gp_segment_configuration
WHERE content >= 0
ORDER BY content, dbid
''')
# san_rows = dbconn.execSQL(conn, '''
# SELECT mountid, active_host, san_type,
# primary_host, primary_mountpoint, primary_device,
# mirror_host, mirror_mountpoint, mirror_device
# FROM pg_catalog.gp_san_configuration
# ORDER BY mountid
# ''')
san_rows = []
现在可以正常执行了,并且在GP5上自动创建数据库及模式
[gpadmin@sdw3 makedata]$ gptransfer -t sdw3.public.test1 --dest-host=sdw4 --source-map-file=source_hosts --truncate --dest-port=5555
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Starting gptransfer with args: -t sdw3.public.test1 --dest-host=sdw4 --source-map-file=source_hosts --truncate --dest-port=5555
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Validating options...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving source tables...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Checking for gptransfer schemas...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving list of destination tables...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Reading source host map file...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Building list of source tables to transfer...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Number of tables to transfer: 1
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-gptransfer will use "fast" mode for transfer.
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Validating source host map...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Validating transfer table set...
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Using batch size of 2
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Using sub-batch size of 2
20200318:13:34:11:047010 gptransfer:sdw3:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_47010'
20200318:13:34:12:047010 gptransfer:sdw3:gpadmin-[INFO]:-Creating database sdw3...
20200318:13:34:13:047010 gptransfer:sdw3:gpadmin-[INFO]:-Creating schema public in database sdw3...
20200318:13:34:13:047010 gptransfer:sdw3:gpadmin-[INFO]:-Starting transfer of sdw3.public.test1 to sdw3.public.test1...
20200318:13:34:13:047010 gptransfer:sdw3:gpadmin-[INFO]:-Creating target table sdw3.public.test1...
20200318:13:34:13:047010 gptransfer:sdw3:gpadmin-[INFO]:-Retrieving schema for table sdw3.public.test1...
20200318:13:34:15:047010 gptransfer:sdw3:gpadmin-[INFO]:-Transfering data sdw3.public.test1 -> sdw3.public.test1...
20200318:13:34:27:047010 gptransfer:sdw3:gpadmin-[INFO]:-Finished transferring table sdw3.public.test1, remaining 0 of 1 tables
20200318:13:34:27:047010 gptransfer:sdw3:gpadmin-[INFO]:-Running final table row count validation on destination tables...
20200318:13:34:28:047010 gptransfer:sdw3:gpadmin-[INFO]:-Validation of sdw3.public.test1 successful
20200318:13:34:28:047010 gptransfer:sdw3:gpadmin-[INFO]:-Removing work directories...
20200318:13:34:34:047010 gptransfer:sdw3:gpadmin-[INFO]:-Finished.
在GP5上验证表同步数据一致
[gpadmin@sdw4 makedata]$ psql sdw3 -ac "select a,count(*) from test1 group by a;"
select a,count(*) from test1 group by a;
a | count
------+--------
sdw3 | 100000
(1 row)
应用示例
1.从GP4同步表sdw3.public.test1到GP5
gptransfer -t sdw3.public.test1 \
--source-host=192.168.43.175 \
--source-port=5432 \
--dest-host=192.168.43.176 \
--dest-port=5555 \
--dest-database=sdw3 \
--source-map-file=source_hosts_sdw4 \
--drop -a
2.从GP5同步表sdw4.public.test1到GP4
gptransfer -t sdw4.public.test1 \
--source-host=192.168.43.176 \
--source-port=5555 \
--dest-host=192.168.43.175 \
--dest-port=5432 \
--dest-database=sdw4 \
--source-map-file=source_hosts_sdw4 \
--drop -a
3.从GP4同步sdw3、sdw4两个数据库到GP5
gptransfer -d sdw3 -d sdw4 \
--source-host=192.168.43.175 \
--source-port=5432 \
--dest-host=192.168.43.176 \
--dest-port=5555 \
--source-map-file=source_hosts_sdw3 \
--drop -a
-d "sdw/[3-4]*/" \
这种正则表达式也可以
4.GP5只迁移表结构,不包括数据到GP4
gptransfer -t sdw4.public.test1 \
--source-host=192.168.43.176 \
--source-port=5555 \
--dest-host=192.168.43.175 \
--dest-port=5432 \
--dest-database=sdw4 \
--source-map-file=source_hosts_sdw4 \
--drop -a \
--schema-only5.GP4批量迁移表到GP5
列表文件 sdw3_table.list
sdw3.public.test1
sdw3.public.test2
sdw3.public.test3
sdw3.public.test4
sdw3.public.test5执行命令
gptransfer -f sdw3_table.list \
--source-host=192.168.43.175 \
--source-port=5432 \
--dest-host=192.168.43.176 \
--dest-port=5555 \
--source-map-file=source_hosts_sdw3 \
--drop -a
最佳实践
注:以下内容转自《GreenPlum中文社区》
gptransfer创建一个允许以非常高速率传输大量数据的配置。不过,对于小表或者空表,gptransfer的设置和清除太过昂贵。最佳实践是对大型表使用gptransfer而用其他方法拷贝较小的表。
1. 在用户开始传输数据之前,从源集群复制模式到目标集群。不要使用带--full –schema-only选项的gptransfer。这里有一些选项可以拷贝模式:
使用gpsd(Greenplum统计信息转储)支持工具。这种方法会包括统计信息,因此要确保在目标集群上创建模式之后运行ANALYZE。
使用PostgreSQL的pg_dump或者pg_dumpall工具,并且加上–schema-only选项。
DDL脚本或者其他在目标数据库中重建模式的方法。
2. 把要传输的非空表根据用户自己的选择划分成大型和小型两种类别。例如,用户可以决定大型表拥有超过1百万行或者原始数据尺寸超过1GB。
3. 使用SQL的COPY命令为小型表传输数据。这可以消除使用gptransfer工具时在每个表上发生的预热/冷却时间。
可以选择编写或者重用现有的shell脚本来在要拷贝的表名列表上循环使用COPY命令。
4. 使用gptransfer以表批次的方式传输大型表数据。
最好是传输到相同尺寸的集群或者较大的集群,这样gptransfer会运行在快模式中。
如果存在索引,在开始传输过程之前删除它们。
使用gptransfer的表选项(-t)或者文件选项(-f)以批次执行迁移。不要使用完整模式运行gptransfer,模式和较小的表已经被传输过了。
在进行生产迁移之前,执行gptransfer处理的测试运行。这确保表可以被成功地传输。用户可以用--batch-size和--sub-batch-size选项进行实验以获得最大的并行性。为gptransfer的迭代运行确定正确的表批次。
包括--skip-existing选项,因为模式已经在目标集群上存在。
仅使用完全限定的表名。注意表名中的句点(.)、空白、引号(')以及双引号(")可能会导致问题。
如果用户决定使用--validation选项在传输后验证数据,确保也使用-x选项在源表上放置一个排他锁。
5. 在所有的表都被传输后,执行下列任务:
检查并且改正失败的传输。
重新创建在传输前被删除的索引。
确保角色、函数和资源队列在目标数据库中被创建。当用户使用gptransfer -t选项时,这些对象不会被传输。
从源集群拷贝postgres.conf和pg_hba.conf配置文件到目标集群。
在目标数据库中用gppkg安装需要的扩展。
