




HDFS安装配置
一、准备知识
此处先分别是介绍HDFS的三种安装模式,接着介绍什么是集群的纵向配置和横向配置,最后介绍安装配置文件的目录结构。
1.1 HDFS的三种安装模式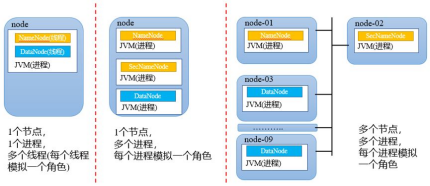
本地模式,所有的功能都在一个JVM里面实现,以线程方式模拟角色,一般用于调试和测试MapReduce程序。
伪分布式模式,每个角色对应一个进程,所有进程都在一个物理节点上,多个进程模拟分布式环境。
全分布式模式,每个角色对应一个进程,并且这些角色分布在集群中不同的物理节点上。
三种不同模式对应的安装与配置有所差异,后续会详细讨论。
1.2 纵向配置和横向配置
Hadoop1.x的系统栈,HDFS包含NameNode和DataNode等角色,MapReduce框架包含JobTracker、TaskTracker、MapTask和ReduceTask等角色。
在系统栈的纵向方向中,底层为上层提供服务,例如HDFS的进程都运行在JVM(java虚拟机)之上,依赖JVM。同时HDFS为MapReduce的守护进程和任务提供统一的存储空间。如何确保下层为上层提供服务要进行相关的配置。
在系统栈的横向方向中,以HDFS为例,NameNode与DataNode之间,DataNode与DataNode之间要进行交互,交互式的方式就是网络,需要配置各物理节点的IP和端口。同样,JobTacker与TaskTracker之间,MapTask和ReduceTask之间都需要通过网络进行交互。
总结一下,纵向配置主要涉及操作系统的环境变量,用来支持底层组件为上层提供服务;横向配置主要用于不同节点间组件的相互协调。
1.3 Hadoop的目录结构
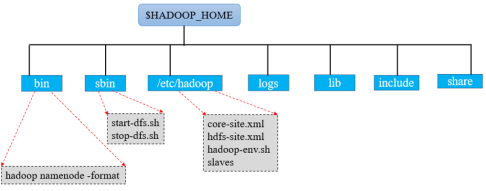
表安装配置HDFS涉及的几个配置文件;
“Hadoop namenode -format”命令用于对集群进行初始化;
“start-dfs.sh”和“stop-dfs.sh”为启动和停止集群的脚本。
其余目录的介绍如下:
$HADOOP_HOME/bin;用于执行hadoop脚本命令,被hadoop-daemon.sh调用执行,也可以单独执行,一切命令的核心。
$HADOOP_HOME/sbin;用于启动停止相关组件如HDFS、MapReduce和Yarn,启动这些组件对应的守护进程。
$HADOOP_HOME/etc/hadoop;Hadoop全局和各个组件的配置文件,这些配置文件和配置项决定了组件的工作机制。
$HADOOP_HOME/logs目录;该目录存放的是Hadoop运行的日志,查看日志对寻找Hadoop运行错误非常有帮助。
$HADOOP_HOME/include目录;对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
$HADOOP_HOME/lib目录;该目录下存放的是Hadoop运行时依赖的jar包,Hadoop在执行时会把lib目录下面的jar全部加到classpath中。
$HADOOP_HOME/libexec目录;各个服务对应的shell配置文件所在的目录,可用于配置日志输出、启动参数(比如JVM参数)等基本信息。
二、集群规划
集群的规划有助于读者从宏观上把握安装配置运维的脉络,有助于培养良好的文档习惯和思维方式。集群的规划要确定以下几个问题:(1)集群有多少个节点,每个节点的资源(CPU核数、内存、磁盘大小);(2)每个节点的机器名和IP地址是什么;(3)NameNode和DataNode分别有几个,每个节点打算部署成什么角色。
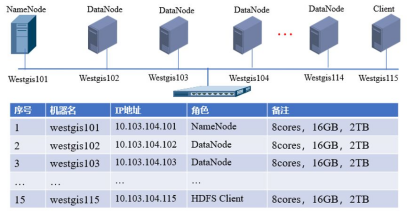
图1-4 集群规划示意图
图1-4描述了集群的规划示意图,在该规划中待配置的HDFS集群有15个节点,每个节点的配置均为(8个core,16GB内存,2TB磁盘空间);每个节点的机器名分别为westgis101~westgis115,IP地址为10.103.104.101~115;其中westgis101为集群的NameNode,westgis102~ westgis114等13个节点为DataNode节点,westgis115为Client角色。
集群的规划是一个复杂的问题,在实际工作环境中有两个问题需要充分考虑:
(1)混合部署,一个集群里面可能要同时部署Hadoop、HBase和Spark,这些大数据组件对应的守护进程运行在同一个物理节点,需要根据应用程序的特征来考虑资源分配的问题。
(2)异构问题,集群中的服务器很可能不是同一批购置,硬件参数如CPU、内存和磁盘大小不一,型号不一,有些节点可能配置GPU等。节点的异构问题也会影响集群的规划。
二、安装配置概述
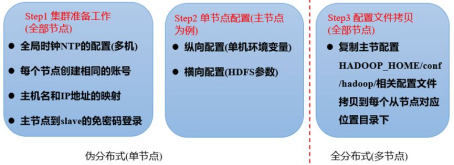
图1-5 安装配置步骤
集群的安装部署可以分为三大步:
(1)集群的准备工作, 涉及全部节点。分别是:集群的全局时钟配置,账号和权限和节点存储路径,配置主机名和IP地址的映射,主节点到所有从节点的免密码登录。
(2)单节点的配置,以主节点为例。分别是:集群的纵向配置和横向配置,前者主要是单机环境变量配置(如java安装路径和Hadoop安装路径),后者是HDFS相关参数的配置(如主节点IP地址和端口号)。
(3)配置文件的拷贝,涉及所有从节点。将主节点上的横向配置和纵向配置拷贝到每一个从节点。此处可以用脚本的方式自动完成拷贝功能。
总结一下,篇幅太长读的很辛苦,后续博文会详细讲解具体的每一步配置。初学计算机要像学英文一样,注重阅读和记忆。
安装配置详细过程
上一篇讲述了预备知识和安装配置的概述,这一篇讲解详细的安装配置过程。

图1-1 详细的安装过程
此处实验环境同上一篇涉及的15台服务器,操作系统为centos7.6,jdk的版本为1.8,Hadoop的版本为2.7.0
一、Step1 集群准备工作(全部节点)
1.1 全局时钟NTP的配置
全局时钟是使计算机时间同步化的一种协议,如果集群中节点的时间不同步,很多分布式系统无法正常工作。
在上一篇的集群规划中描述了15个节点,分别是westgis101~westgis115。我们将westgis101当成NTP的服务器,其它14个节点与NTP服务器进行时间同步。需要注意的是,如果集群中每台服务器都可以连接互联网,我们也可以选择互联网上的NTP服务器。但是,考虑到企业内部集群不一定能访问互联网,我们也可以选择在内部确定一台NTP服务器。
一般情况下,Centos7.6 已经自带NTP,其配置文件路径为/ect/ntp.conf,只需要修改配置文件即可。
NTP服务器的配置,在westgis101上打开配置文件 vim etc/ntp.conf 并增加如下内容:
----------------------------------------
#授权10.103.104.0网段上所有机器可以从这台机器上查询和时间同步
restrict 10.103.104.0 mask 255.255.255.0 nomodify notrap
#当外部NTP服务器无法连接时,使用本机为NTP服务器
server 127.0.0.1
fudge 127.0.0.1 stratum 10
-------------------------------------------
此处10代表计算机在网络top中的层级数,一般在15以内。
NTP客户端的配置,在westgis102~westgis115所有节点上执行。打开配置文件
vim etc/ntp.conf 增加如下内容:
---------------------------------------------
#只需在配置文件的server下在加一条代码,允许同步10.0.0.31这台主机时间
server 10.101.103.101 iburst
--------------------------------------------
重启NTP服务,在每个节点上执行命令: systemctl restart ntpd
1.2 每个节点创建相同的账号
使用root账户执行命令创建账号,例如账号名为xiongwen。需要执行以下命令: useradd -m xiongwen
备注:useradd命令的详细使用方法可以通过man useradd的方式获得。
1.3 主机名和IP地址的映射
打开文件/etc/hosts,增加HDFS集群涉及的所有节点的IP地址和节点名称,如图1-2所示。
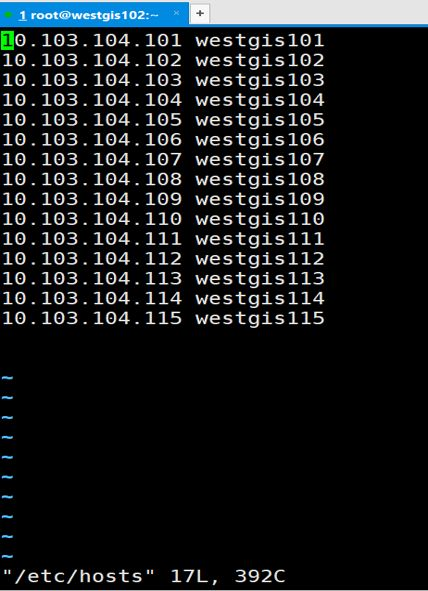
图1-2 HDFS集群涉及的所有节点
1.4 主节点到从节点的免密码登录
主节点到所有从节点,即westgis101到westgis102~westgis115,此处westgis101为NameNode,其它节点为DataNode。以westgis102为例,配置可以分为三小步,分别是:
a. 在westgis101上产生公钥和私钥文件
私钥/home/xiongwen/.ssh/id_rsa
公钥/home/xiongwen/.ssh/id_rsa.pub
b. 将公钥文件id_rsa.pub远程拷贝到slave节点任意位置,例如/tmp
scpid_rsa.pub xiongwen@westgis102:/tmp
c. 将公钥文件追加到/home/xiongwen/.ssh/
远程登录到westgis102节点
cat tmp/id_rsa.pub>> home/xiongwen/.ssh/authorized_keys
二、单节点配置(以主节点为例)
纵向配置主要涉及各节点操作系统的环境变量配置,横向配置主要用于不同节点间组件的相互协调。
2.1 纵向配置
如果使用root账户配置全部用户的环境变量,修改配置文件/ect/profile。
如果使用xiongwen配置环境变量,则修改配置文件/home/xiongwen/.bashrc
增加如下内容:
#Hadoop
export HADOOP_HOME=/opt/bigdata/hadoop
export PATH={HADOOP_HOME}/bin:$PATH
#Java
export JAVA_HOME=/opt/bigdata/jdk
export PATH={JAVA_HOME}/bin:$PATH
/*此处需要说明的是:/opt/bigdata/hadoop和/opt/bigdata/jdk分别为hadoop和jdk安装包所在路径*/
2.2 横向配置
横向配置涉及$/HADOOP_HOME/etc/hadoop目录下的四个配置文件,分别是:core-site.xml, hdfs-site.xml. hadoop-env.sh和slaves
a. 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://westgis101:8020</value>
</property>
</configuration>
/*此处wetgis101为NameNode的机器名,8020为RPC通讯端口*/
b. 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdfs/data</value>
</property>
</configuration>
/*此处dfs.replation为数据的备份个数,一般情况为3*/
/*此处/opt/hdfs/name为元数据在NameNode本地存储路径,手动创建*/
/*此处/opt/hdfs/data为实际数据在DataNode本地存储路径,手动创建*/
c. 配置hadoop-env.sh
在文件最后增加 export JAVA_HOME=/opt/bigdata/jdk
/*在配置文件中增加jdk的路径*/
d. 配置slaves
打开该文件,将HDFS集群所有的DataNode机器名加入到文件中,每行一个DataNode,形式如:
westgis102
westgis103
westgis104
......
三、复制主节点配置到所有从节点
首先,将NameNode上环境变量配置文件拷贝到每个DataNode,接着将NameNode上$/HADOOP_HOME/etc/hadoop下的四个配置文件拷贝到所有DataNode节点。
此处可以写全自动化的脚本在主节点上执行,脚本内容如下:
scp $/HADOOP_HOME/etc/hadoop/core-site.xml xiongwen@westgis102: $/HADOOP_HOME/etc/hadoop/
/*写脚本的过程中,配置文件名和节点名称均可以作为变量*/
四、集群的初始化与启动
a.格式化HDFS
hadoop namenode -format
b.启动HDFS
主节点执行 $HADOOP_HOME/sbin/start-dfs.sh
c.Web监控界面
URL http://westgis101:50070
/*监控界面显示了集群的相关信息如NN节点个数、节点存储空间等信息*/
d.命令行状态查看集群状态
hadoop dfsadmin –report /*显示节点个数、节点存储空间等信息*/
e.停止HDFS
主节点执行 $HADOOP_HOME/sbin/stop-dfs.sh
五、常见的错误排查方法
a. 查看java进程(一)
jps /*显示当前账户java进程*/
b.查看java进程(二)
ps aux|grep java /*显示当前节点java进程,功能比(一)强大*/
c.查看端口是否开启
netstat –tunlp|grep 50070
d.占用某个端口的进程
lsof–i:50070
e.异常处理查看日志
$HADOOP_HOME/logs/*-DataNode-.log
$HADOOP_HOME/logs/*-DataNode-.out
HDFS的安装模式
伪分布模式
在本地文件系统上运行
NameNode、DataNode、secondarynamenode全部部署在一台机器上,在一台机器上模拟分布式部署
集群模式
运行在多台机器的HDFS上
需要配置好的文件:
1、设置静态IP地址
2、设置DNS解析
Hadoop 集群之间通过主机名互相访问,因此需要设置DNS解析
设置主机名:编辑配置文件“/etc/sysconfig/network”
NETWORKING=yes
HOSTNAME=hadoop
设置节点IP与主机名的映射:编辑文件“/etc/hosts”
例如:192.168.126.110 hadoop
注意:标红需保持一致
验证配置:执行“ping hadoop/192.168.126.110”命令。
3、关闭防火墙
4、设置SSH自动登录
5、安装JDK
安装HDFS
1.解压hadoop安装包
tar zxvf hadoop-2.6.0-cdh5.5.0.tar.gz
2. 重命名:
mv hadoop-2.6.0-cdh5.5.0 hadoop
3.配置环境变量:
vi etc/profile
#set java enviroment
export JAVA_HOME=/opt/software/java/jdk1.8.0
export JRE_HOME=/opt/software/java/jdk1.8.0/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JRE_HOME/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#set zookeeper enviroment
export ZOOKEEPER_HOME=/opt/software/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#set hadoop enviroment
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
4.修改配置文件: hadoop-env.sh
cd home/hadoop/hadoop/etc/hadoop
vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk
vi core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master2:9000</value>
<description>change your own hostname</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/software/hadoop/hadoop-2.7.3/temp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
5.修改配置文件:hdfs-site.xml
<property> <name>dfs.namenode.name.dir</name>
<!--namenode节点数据存储目录-->
<value>/opt/software/hadoop/hadoop-2.7.3/hdfs/name</value>
</property>
<property>
<!--datanode数据存储目录-->
<name>dfs.datanode.data.dir</name>
<value>/opt/software/hadoop/hadoop-2.7.3/hdfs/data</value>
</property>
<property>
<!--指定DataNode存储block的副本数量,不大于DataNode的个数就行-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!--指定master的http地址-->
<name>dfs.namenode.http-address</name>
<value>master2:50070</value>
</property>
<property>
<!--指定master的https地址-->
<name>dfs.namenode.secondary.https-address</name>
<value>master2:50091</value>
</property>
<property>
<!--必须设置为true,否则就不能通过web访问hdfs上的文件信息-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
6.修改配置文件:mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
7.配置:yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master2</value>
</property>
<property>
<!--用户可通过该地址在浏览器中查看集群各类信息。-->
<name>yarn.resourcemanager.webapp.address</name>
<value>master2:8088</value>
</property>
<property>
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,
才可运行MapReduce程序-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
8. vi slaves
slave01
........
9.hdfs初始化:
hdfs namenode -format ---格式化namenode
注意:如果NameNode出现错误,删掉name文件并重新格式化即可。

显示成功即可。
10.启动HDFS
start-dfs.sh
jps
start-yarn.sh
