




介绍
随着日常数据的增加,对商业智能的需求前所未有地蓬勃发展。商业智能是关于数据分析以收集商业洞察力以更好地采取商业行动,并且可以使用一些 ETL 工具来完成这种分析。
.jpg)
Hive 是一个 ETL(Export, Transform & Load) 工具,可以查询存储在 Hadoop 分布式文件系统上的大型数据集。Facebook 为其业务分析师设计了 Hive 框架,这些分析师对任何编程语言知识有限,但擅长运行 SQL 查询以查找业务信息。
Apache Hive 的特点
它不是数据库,因为它不存储数据和模式。数据始终存储在 Hadoop 分布式文件系统中;Hive 在读取时仅在该数据上存储模式;因此读取时称为模式。
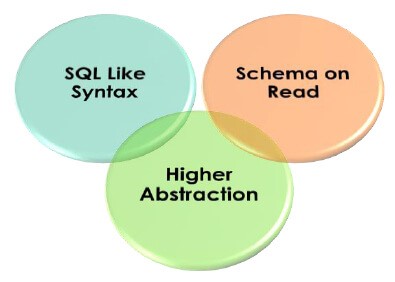
SQL作为语法:
Hive 使用一种称为 Hive 查询语言 (HQL) 的类似 SQL 的语言来执行数据分析。Apache Hive 在熟悉 SQL 查询的业务分析师和测试人员中非常流行。
更高的抽象:
Apache Hive 基于 Hadoop 框架构建,并在后台运行 MapReduce 作业。HQL 查询被转换为 Java 程序,在 Hadoop 之上作为 Mappers 和 Reducers 运行并执行分析。
了解大数据中的 Apache Hive
Apache Hive 是一个特别强大的大数据工具(要分析的指数数据)。Hive 大数据的概念在技术领域非常流行。它是一个定期支持大数据分析过程的仓库数据软件。由于数据存储在 Apache Hadoop 分布式文件系统 (HDFS) 中,数据在其中被组织和结构化,Apache Hive 有助于处理和分析这些数据,并根据数据创建模式和趋势。Apache Hive 适用于组织或机构,在大数据及其不断变化的增长领域非常有用。
结构化查询语言或 SQL 软件的概念涉及与许多数据库通信并收集所需数据的过程。通过数据分析了解 Hive 大数据可以帮助我们更深入地了解 Apache Hive 的工作原理。Hive 使用批处理序列以更简单、更有条理的形式生成数据分析,与传统工具相比,所需时间更少。HiveQL 是一种类似 SQL 的语言,可以跨不同组织与 Hive 数据库进行交互,并以结构化格式分析所需数据。
Hive 大数据的未来
最终,大数据中的蜂巢价值会下降。随着越来越多的基于云的软件(如 Google Bigquery)在即时数据跟踪方面变得更加高效,Apache Hive 正在退居二线,因为其在市场上的品牌逐渐恶化。
Hive 在大数据预测方面的未来似乎并不光明,但它仍然是当时领先的软件之一。由于今天的大数据在分布上更具弹性,因此 Hive 的过程比其他的稍慢。
随着许多科学家和技术领导者宣布 Apache Hive “已死”,该软件的未来可以概括为一条下行轨迹。
Apache Hive 的架构
用户界面:
Hive 在用户和 HDFS 之间提供了一个接口,以对存储在 Hadoop 文件系统中的数据运行 HQL 查询。各种受支持的 Hive 界面是 Hive 命令行、Hive Web UI 和 Hive HDInsight。
元商店:
Hive 将模式和表元数据(如列名、列类型和 HDFS 位置(存储数据的位置))存储在单独的数据库中。默认情况下,内部使用 Derby 数据库来存储模式,但可以将其替换为任何其他数据库,例如 Postgres 或 MySQL,用于生产环境。
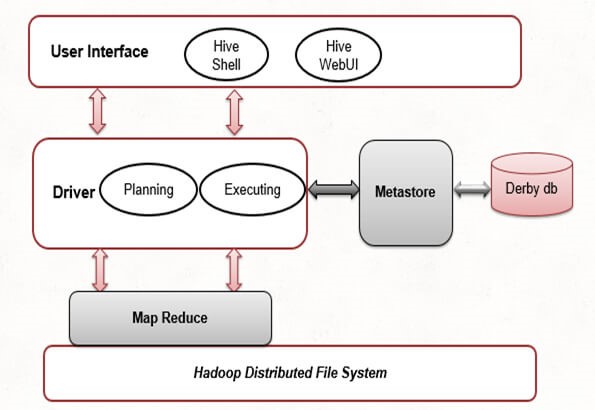
HiveQL 流程引擎:
此处理引擎与 Metastore 通信以编译和分析 HQL 查询。
执行机器:
它处理 HQL 查询以创建相应的MapReduce作业,该作业在 Hadoop 分布式文件系统之上运行以访问数据并生成最终输出。
在 Apache Hive 中创建数据库
为了使用 Hive,我们需要一个可以在其中创建表的数据库。下面的命令可以在 Hive 中创建、描述和删除数据库。
蜂巢数据库
如果公司不存在,则创建数据库; 描述数据库公司; 删除数据库公司;
外部/托管表
子注册表中有两种类型的表——外部表和托管表。两者之间的主要区别在于,如果您删除托管表,则附加到该表的数据和架构将被删除。相反,如果您删除一个外部表,则只有与该表关联的模式将被删除,尽管 HDFS 上的数据将保持不变。
创建托管表
CREATE TABLE employees (custId INT, name STRING, name STRING, city STRING) LINE FORMAT RESTRICTED FIELD TERMINATED '|.' 保存为文本文件;
CREATE TABLE employees (emp Id INT, f_Name STRING, name STRING, city STRING) LINE FORMAT RESTRICTED FIELD TERMINATED '|.' 另存为纺织文件
位置'/用户/Cloudera/员工;
Apache Hive 分析
Hive 支持执行数据分析的各种方式,例如
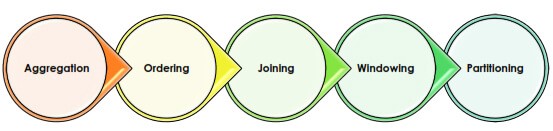
聚合:
您可以使用 Hive 提供的各种聚合 API 来聚合数据,例如 count、sum、avg 等。
命令:
分发中的排序/排序与传统系统几乎没有区别。您可以在所有计算机上对数据进行排序,从而导致数据混合,也可以在一台计算机内对数据进行排序。在一台机器内排序数据并不能保证所有机器上的顺序。
连接:
您还可以基于某些键连接数据并对连接的数据执行聚合。
窗户:
使用 Hive 中的窗口概念,您可以分析落在窗口内的数据。例如,您想查找过去 10 分钟内搜索次数最多的网站或过去 7 天内最畅销的产品。
分配:
您还可以在 HDFS 上对数据进行分区。数据分区的概念可以使查询运行得更快。例如,在按人口统计的数据中,您可以按国家和城市拆分数据。假设我想根据国家/城市汇总人口数据;我可以直接按国家/城市进行分区,而不是搜索整个数据,减少查询延迟。
聚合
假设我想找出所有员工人数超过 100 人的城市。我可以在 HQL 下运行查询。
一个拥有100多名员工的城市
SELECT city, count(*) FROM employees GROUP BY city HAVING count(*) > 100
Hive 提供了许多内置的聚合操作,例如 Sum、Min、Max 和 Avg。Hive 还提供字符串、日期和数学运算来执行高级分析和一些格式化或高级分析。
分区
如前所述,拆分可以让 HQL 运行得更快。在下面的示例中,我们根据员工所在的城市拆分了员工数据。运行以下查询将根据编号在 HDFS 上创建物理目录。城市,来自同一个城市的所有数据将进入同一个分区。例如,Partitioning Newyork City 将拥有来自纽约的所有员工。
按城市划分
CREATE EXTERNAL TABLE employees_partitioning (embed INT, name STRING, name STRING) SPLIT (city STRING) LINE FORMAT RESTRICTED FIELD TERMINATED ',';
连接
我们可以使用 Hive 加入数据。例如,我们在 HDFS 上有员工和部门数据,我们想加入这些数据以获取我们的员工最终的部门信息。Hive 支持不同的连接类型——内连接、右外连接和左外连接;您可以使用 Hive 中的连接查询将多个表连接在一起。
举个例子;假设我们在两个不同的地方有关于员工和部门的信息,我想结合这些数据来得到最终结果中的员工和部门名称。下图表示数据集和使用内连接后的最终结果。
基于 EmpId 的内连接 SELECT e.emp_name,d.dep_name FROM employee e JOIN department d ON (e.dep_id==d.dep_id)
结论
Apache Hive 在业务分析师、测试人员、数据分析师甚至开发人员中很受欢迎,因为它灵活且易于对大数据公司运行 SQL 查询。然而,其他 ETL 工具每天都在进入市场,比如 Presto 和 Impala,但 Hive 已经占据了一席之地,并且在整个行业中得到了很好的使用。
- 总而言之,Apache Hive 于 2010 年 10 月推出,以促进对跨组织可用的大数据进行数据分析。Hive 快速、熟悉、高效且可靠,已成为当时最好的大数据软件工具之一。
- 尽管该软件的未来看起来不太乐观,但在过去十年中,它无疑是将大数据分析推向顶峰的明星。随着越来越多的竞争对手的到来,该软件在其高度重视的功能方面仍然是独一无二的。
- 大数据无处可去,因此当今技术领域需要更高级的 Apache Hive 版本来处理每秒生成的大量 PB 数据。
原文标题:Chetan Dekate
原文作者:Performing Big Data Analysis with Apache Hive
原文链接:https://www.analyticsvidhya.com/blog/2022/10/performing-big-data-analysis-with-apache-hive/
