






PostgreSQL的MVCC是通过使用一种多版本模型来维护,所以表或索引的膨胀是不可避免的。
通常我们收缩膨胀表或索引可以使用vacuum full、rewrite table(如在线CLUSTER)的方式重建表,至于索引可以重建或重定位表的索引。
pg_squeeze和pg_repack区别
首先说pg_repack,pg_repack 是pg_reorg的一个分支。其工作机制如下:
创建一个日志表来记录对原始表所做的更改。 在原始表上添加一个触发器,将 INSERT、UPDATE 和 DELETE 记录到我们的日志表中。 创建一个包含旧表中所有行的新表。 在这个新表上建立索引。 将日志表中产生的所有更改应用到新表。 使用system catalog(包含了元数据的VIEW和表的一个schema)交换表,包括索引和toast table。 删除原始表。
所以相对于pg_repack,其不需要建触发器,并且在重组时对原表的DML几乎没有性能影响。另外pg_squeeze支持自动重组。即通过设置阈值,自动启动WORKER进程,将数据复制到重组表,最后加锁切换。但是要求表必须有一个PRIMARY KEY,或者在非空列上至少有一个唯一索引。
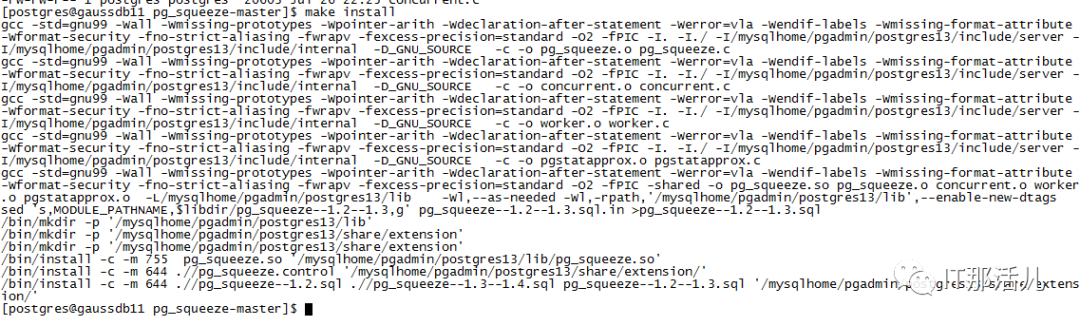
pg_squeeze安装及使用
下载路径如下:
https://github.com/cybertec-postgresql/pg_squeeze

wal_level = logical
max_replication_slots = 1 #或者在当前值上加1。
shared_preload_libraries = 'pg_squeeze' #将pg_squeeze添加到现有库中。
CREATE EXTENSION pg_squeeze;
INSERT INTO squeeze.tables (tabschema, tabname, schedule)
VALUES ('public', 'person', ('{10}', '{23}', NULL, NULL, '{4, 6}'));
INSERT INTO squeeze.tables
(tabschema, tabname, schedule, free_space_extra, vacuum_max_age,max_retry)
VALUES ('public', 'person', ('{10}', '{23}', NULL, NULL, '{4, 6}'), 30,'2 hours', 2);

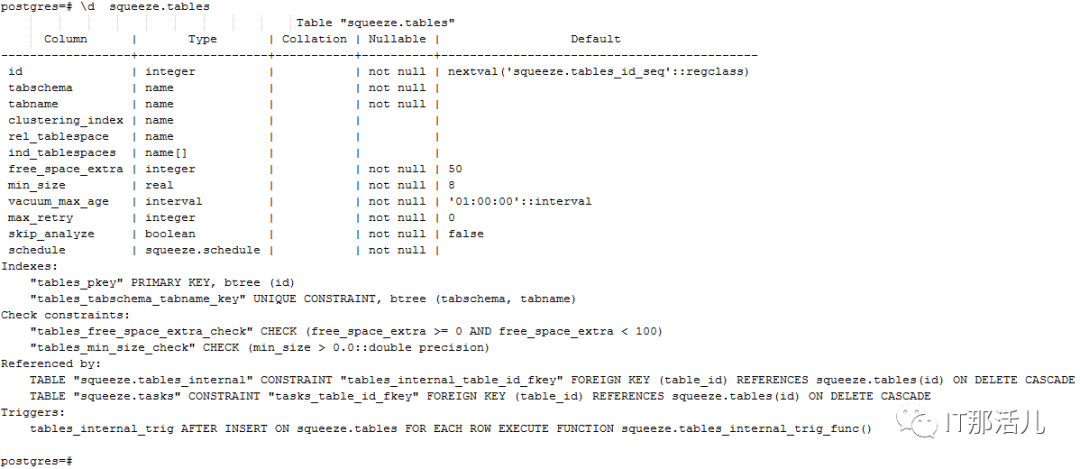
字段描述如下:
“tabschema”和“tabname”分别是模式和表名。
“schedule”列告诉何时应该检查表,并且可能会被squeezed。调度由以下复合数据类型的值描述,CREATE TYPE schedule AS ( minutes minute[], hours hour[], days_of_month dom[], months month[], days_of_week dow[] ); “minutes”(0 到 59)和“hours”(0 到 23)指定一天内的检查时间,而“days_of_month”(1 到 31)、“months”(1 到 12)和“days_of_week” "(0 到 7,其中 0 和 7 都代表星期日)确定日期。 如果“分钟”、“小时”和“月”都与当前时间戳匹配,则执行检查,而 NULL 值分别表示任何分钟、小时和月。至于“days_of_month”和“days_of_week”,至少其中之一需要与当前时间戳匹配,或者两者都需要为 NULL 才能进行检查。
“free_space_extra”表示空闲空间超过多少时就会对表进行重建,默认是50。
“min_size”是表必须占用的最小磁盘空间(以 MB 为单位)才能进行处理。默认值为 8。
“vacuum_max_age”当进行一次vacuum后,认为fsm是有效的最大时间,默认1小时。
“max_retry”当重建表失败时最大的重新尝试的次数,默认是0。
“clustering_index”是已处理表的现有索引。处理完成后,表的元组将按此索引的键进行物理排序。
“rel_tablespace”是表应该移动到的现有表空间。NULL 意味着表应该保持在原来的位置。
“ind_tablespaces”是一个二维数组,其中每一行指定索引的表空间映射。第一列和第二列分别代表索引名和表空间名。所有未指定映射的索引都将保留在原始表空间中。
“skip_analyze”表示表处理后不应该有ANALYZE命令。默认值为“false”,表示默认执行 ANALYZE。
SELECT squeeze.start_worker();
SELECT squeeze.stop_worker();
SET squeeze.max_xlock_time TO 100;
squeeze.squeeze_table(tabchema name, tabname name, clustering_index name, rel_tablespace name, ind_tablespaces name[])
SELECT squeeze.squeeze_table('public', 'person_old202209', null, null, null);

本文作者:魏 斌(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

