




声明:本系列文章是《图数据库(第二版)》的读书笔记,内容是笔者消化之后多转述。需要阅读原书的可以自己购买,或者从网站(www.graphdbs.com)/公众号(图数据库杂谈/graphdbs)下载高清扫描版电子书。
上一章我们已经知道,图是由「节点」和「联系」组成,我们可以称为关联数据。那么问题就来了,为什么非要用图数据库存储呢?我用关系型数据库、NoSQL数据库存储不行么?答案当然是可以的,但是图数据库更合适。
一、关系型数据库缺少联系
关系型数据库是建立在关系模型基础上的数据库,简单来说就是指二维表格模型,因而一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织。
联系一般出现在数据表的建模阶段,作为连接表的方式,常见的就是外键。但是随着离群数据(离群值指在数据中有一个或几个数值与其他数值相比差异较大)的增加,数据结构的宏观结构会越发的复杂和不规整,关系模型将造成大量表连结、稀疏行和非空逻辑检查,这会阻碍性能,并使已有的数据库难以响应业务需求的变化。
1.1 电商系统中的关联
下图是一个电商系统部分表设计:用户表 User、订单表 Order、订单-商品表 LineItem、商品表 Product。
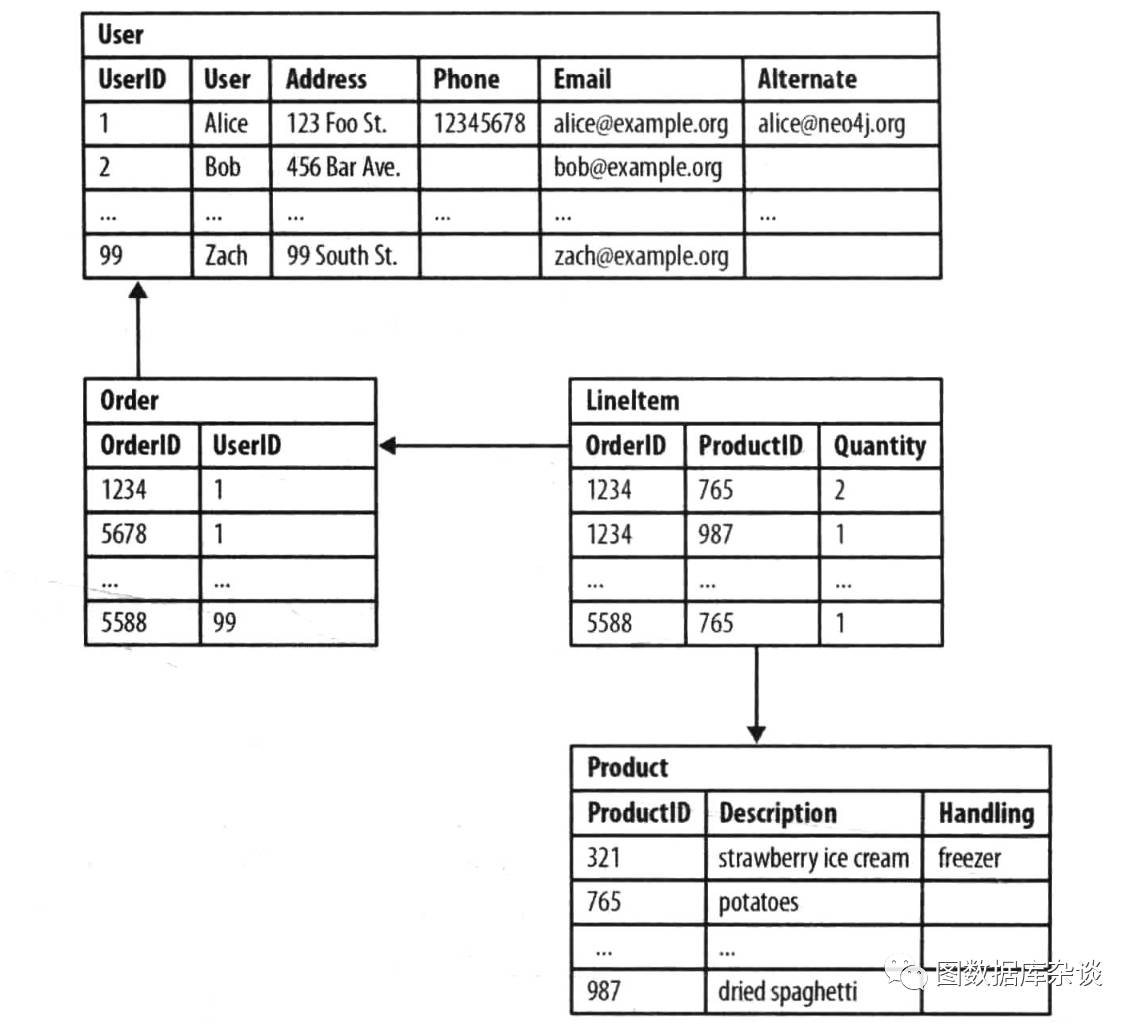
图一:关系型数据库中的关联
我们不妨先分析下,这种表结构的设计是否合理?用户表和商品表毋庸置疑,一个主键,其他是详细信息,没有额外关联。但是,订单表需要考虑,为啥还要拆出一个订单-商品表?详细的考虑下,订单需要的主要信息是订单ID、下单用户、商品数量、总金额、下单时间、订单状态等信息,而具体买了什么商品并不是很重要,所以就需要拆分出一张订单-商品的关联表。订单-商品表可以有一个主键(没有实际用途),也可以不要主键。
好,在我们认定表结构设计没有问题的情况下,我们考虑几个问题:
1、谁买了什么需要几张表关联?
SELECT t4.* from User t1 JOIN Order t2 on t1.UserID=t2.UserID
JOIN LineItem t3 on t2.OrderID=t3.OrderID
JOIN Product t4 on t3.ProductID=t4.ProductID
WHERE t1.User = 'XXX';
2、某个商品被哪些人买了要怎么查询?
由此可见,对于强关联的情况下,关系型数据库的表现并不是很好。除此,还存在业务数据和外键数据混杂、外键约束增加额外成本、稀疏表的空值需要额外检查等问题。
1.2 社交关系中的关联
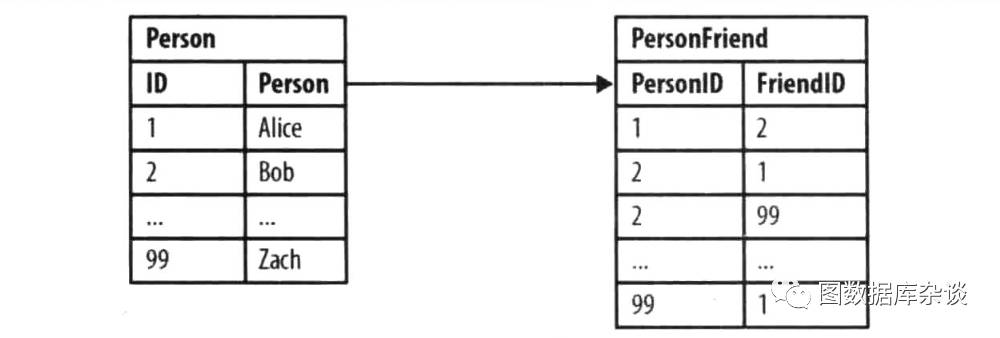
图二:关系型数据库中对朋友关系的建模

1、查询Bob的朋友?
SELECT t1.Person from Person t1 JOIN
(SELECT t3.FriendID from Person t2 JOIN PersonFriend t3 on t2.ID=t3.PersonID
WHERE t2.Person='Bob') t4 on t1.ID=t4.FriendID;

2、Bob是谁的朋友?
SELECT t1.Person from Person t1 JOIN
(SELECT t3.PersonID from Person t2 JOIN PersonFriend t3 on t2.ID=t3.FriendID
WHERE t2.Person='Bob') t4 on t1.ID=t4.PersonID;

3、Alice的朋友的朋友们?
SELECT t1.Person from Person t1 JOIN (
SELECT t5.FriendID from PersonFriend t5 JOIN
(SELECT t3.FriendID from Person t2 JOIN PersonFriend t3 on t2.ID=t3.PersonID
WHERE t2.Person='Alice') t4 on t4.FriendID=t5.PersonID
) t6 on t1.ID=t6.FriendID

通过上面的三个查询示例,我们看到只是查询三度人脉的时候,SQL语句已经开始非常复杂,而查询过程的复杂度也变得很高、查询效率开始恶化,那么当问题延伸到第四度、第五度甚至第六度关系时呢?
二、NoSQL数据库也缺少联系
NoSQL数据库有很多种,常见的有键值数据库(Redis、Memcached)、文档数据库(MongoDB、CouchDB)、列数据库(Cassandra、HBase)、图数据库(Neo4J、OrientDB)。这部分主要指前三种,因为前三种数据库存储的都是无关联的值/文档/列,因此很难将它们用于关联数据和图。这里容易引起歧义,需要分清这里主要是指很难用于直接存储数据和关系,并不是不能存储,因为第一节我们讲过图的存储分原生和非原生,非原生的就是存储在NoSQL数据库中,比如Titan。
对于这几种NoSQL数据库来说,一种广为认知的添加联系的策略就是添加外键,但是这样又需要在应用层连结聚合数据,也会增加额外的代价。
2.1 电商系统中的关联
下图是一个电商系统中的聚合存储模型,通过k-v表示数据之间的联系。
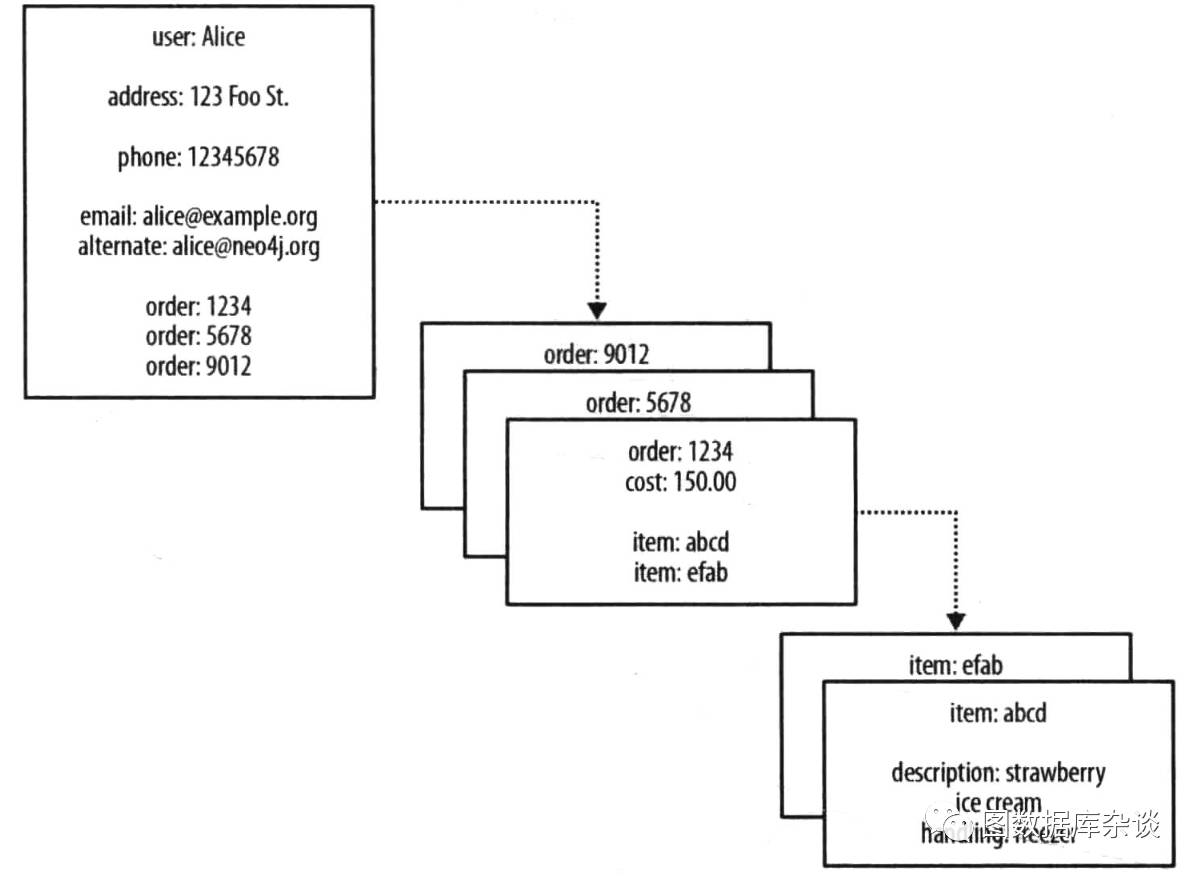
图三:聚合存储模型中的联系
在图中,我们确实看到了一些属性值引用了数据库中其他聚合数据,然而将这些引用转化为可导航的结构需要一定的代价,因为聚合数据之间的联系并非数据模型中的一等公民--多数聚合存储只是以内嵌映射结构的方式装饰在聚合数据之内。相反,应用程序使用数据库时必须从这种扁平的、无关联的数据结构中建立起联系。我们还必须确保应用程序能够随着数据的变化更新或者删除外部聚合数据。假如不这样做,存储将积累无用的引用,从而破坏数据的质量和查询性能。
这种方案还有另外一个弱点。由于没有反向指针(外部聚合引用的指针不是自反的),数据库丧失了运行其他有趣的查询的能力。比如图中,想要知道谁买了某种商品(基于购买历史做商品推荐),就是一个代价高昂的操作。想要处理这类问题,我们需要导出数据集,并在外部计算框架(如Hadoop)上运行计算来获取结果;或者只能回过头来将外部聚合引用反向插入,随后才能查询结果。但是无论哪种方法,都不是直接的,而是隐含的。
1.2 社交关系中的关联
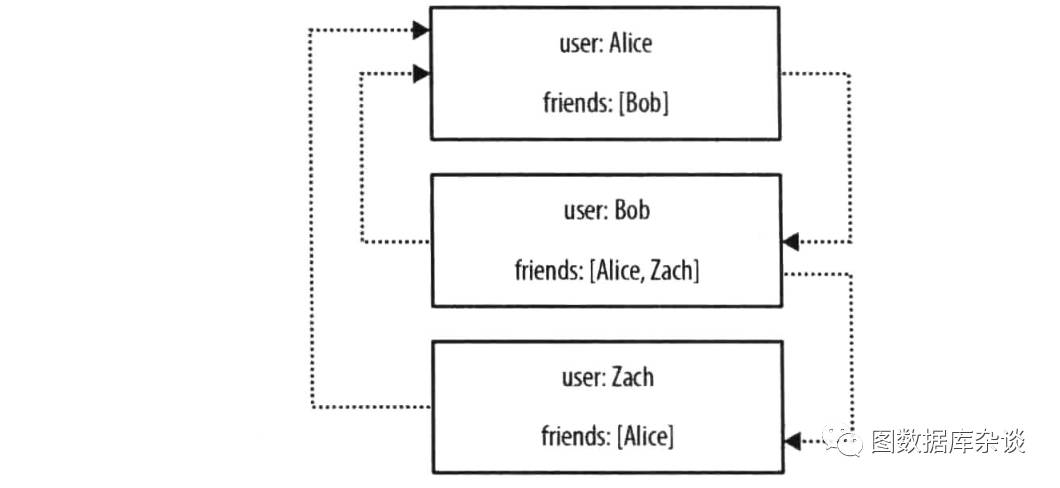
图四:小型社交网络的聚合存储模型
图四是一个基于文档实现的聚合存储的小型社交网络。通过这种结构,我们可以很明显的找到用户的直接朋友(查询Bob的朋友),不需要进行全表扫描。但是当我们回到 "Bob是谁的朋友"这样的问题时,就必须要进行全表扫描。当然我们可以通过添加属性friend_by,来表示入度关系(friends表示出度关系),但是这样又增加了数据维护成本和存储成本。
当需要处理,"Alice的朋友的朋友们",或者第四度以及更深的人脉关系时,这种开销就更大了。
三、图数据库拥抱联系
通过上面的介绍,我们知道了在关系型数据中,关联关系通常以外键存在;在NoSQL数据库中,关联关系通常以键值对存在;而在图的世界中,关联数据被肢解存储为关联数据。
3.1 电商系统中的关联
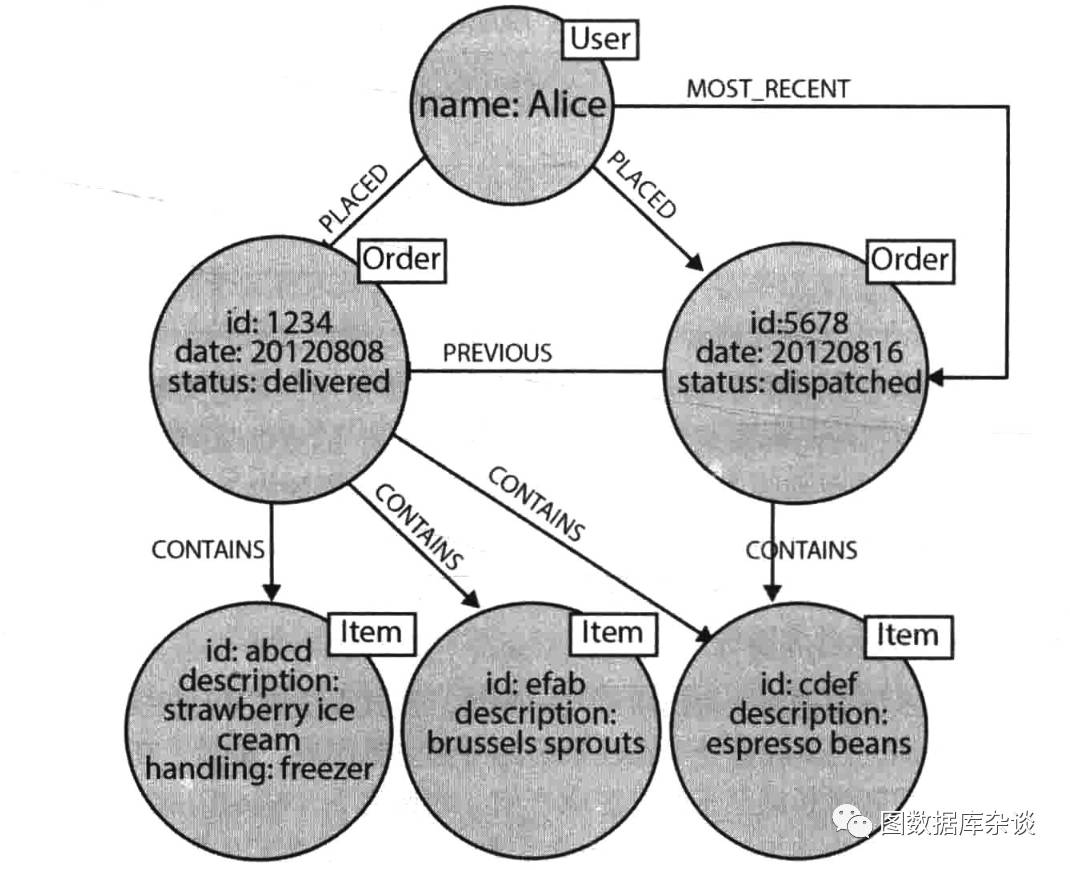
图五:电商系统的图数据库建模
首先,我们将用户的购买历史建模为关联数据。这在图中很简单,只需要将用户和订单链接起来,再将订单和商品链接起来,然后再将订单链接为购买历史。图五中,我们可以看到用户已经订购(PLACED)的所有订单,同时很容易推出没个订单包含(CONTAINS)哪些商品。通过MOST_RECENT可以找到用户最近的订单,随后沿着PREVIOUS可以回溯到更早的订单。
3.2 社交关系中的关联
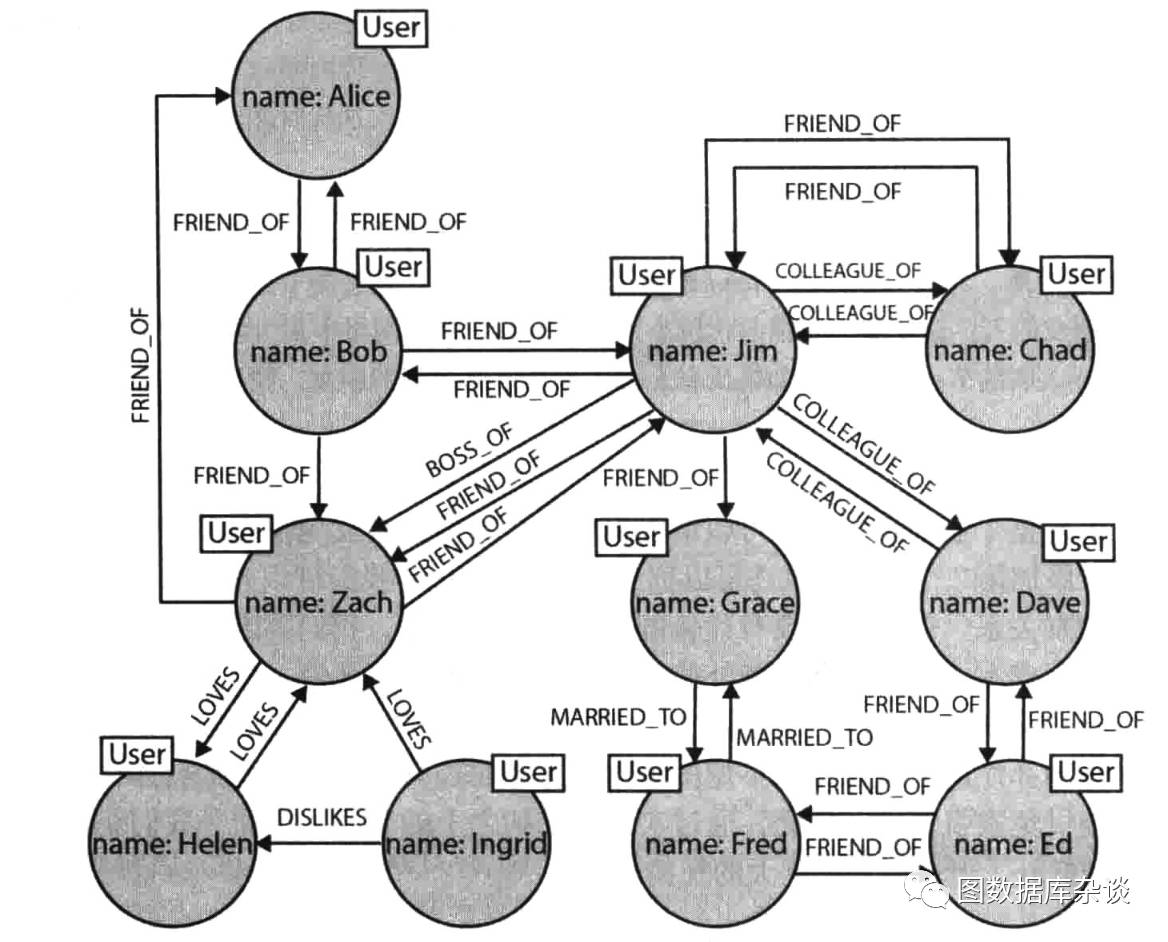
图六:小型社交网络的图数据库建模
图六的社交网络中包含了朋友、恋人/单恋、同事/老板、婚姻等关系,规模上潜在朋友关系已经达到六度。图模型等灵活性,使得我们可以增加额外的节点和新的联系,同时不影响现有的社交网络,也不用做数据迁移。
图中的关系,自然的形成了路径。查询图或者遍历图都涉及路径。由于从根本上说,数据模型是面向路径的,多数基于路径的图数据库的操作都与数据模型本身呈现高度一致性,所以图数据库极为高效。

