ECUG(Effective Cloud User Group,实效云计算用户组)主办的 2021 ECUG Con 于 2021 年 4 月 10 日 - 11 日在上海举办。会上,Zilliz 合伙人、系统架构师郭人通以「Milvus:探索云原生的向量搜索引擎」 为主题进行了分享,介绍了 Milvus 项目,并分享 Milvus 社区在构建云原生向量搜索引擎过程中的探索工作。以下为演讲内容整理。
Embedding 是新的数据来源
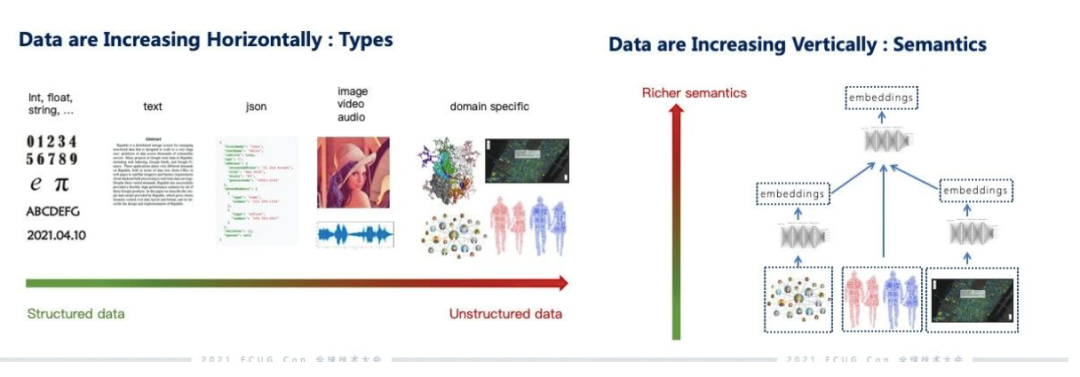
演讲一开始,郭博士从基础软件的角度出发探讨了近几年数据的变化,整体上可以分为两个方面的变化:一个是水平方向,一个是垂直方向。主要是数据种类多样性的变化。最早传统的数据库是一些高度抽象的数据类型,但随着这些数据越来越多样化之后, 数据的抽象程度逐渐地降低。主要是借由神经网络提取非结构化数据里面的内容和语义。这部分在发展和能力上都有很显著的提升。提取内容和语义的过程叫做 embedding,这个提取出来的东西叫向量。物理上它就是一个稠密的浮点数向量的形式。越往高处的 embedding 越会综合多个维度的信息,这些 embedding 对于数据的描述更立体,语义也会更丰富。综合水平和垂直两个方向的变化,我们发现 embedding 很重要,在 embedding 这一层,它可以很好地去汇总数据横向类型的扩张和纵向语义层面的扩张。特别是 embedding 这个向量的类型也是一种高度抽象的数值类型,这样就给我们做系统软件的人提供了一个非常好的数据基础。虽然说文本的分析和搜索有 ES (ElasticSearch),但是除了 ES 以外还有非常多不同的非结构化数据,以现在数据扩张的速度如果每一种都做一个非结构化系统,这个工作量将很难想象。 非结构化数据的处理和分析
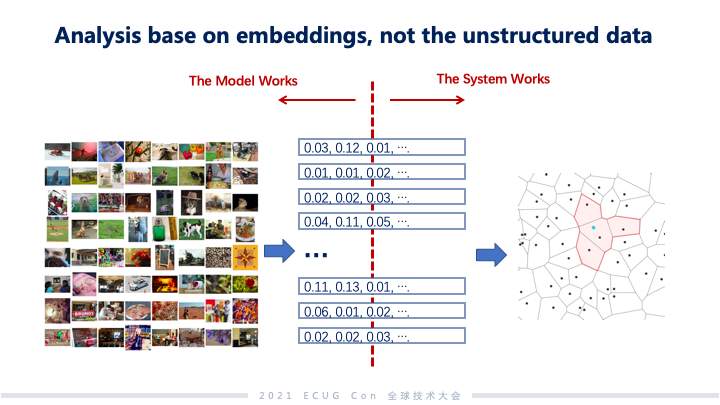
非结构化数据处理的过程可以分成两部分,上图左边的部分更多是算法工作,右边则是系统工作。随着神经网络的发展,左边这部分工作在落地的时候还是有很多工作达到了很好的效果,但是在右边的系统工作,我们生成了这些向量之后,怎么管理这些向量,分析这些向量,系统软件层面还是有一个比较大的缺口。因此,我们 ZILLIZ 团队针对这些问题发起了 Milvus 这个项目,希望能够有一个能力比较强的基础软件去支撑 embedding 向量这样新兴的数据类型,以及其需要的分析和搜索的能力。 Milvus 向量搜索引擎
向量和向量相关的数据属性的存储。
在这些数据上面构建一系列高级的索引结构。
在这些索引结构上支撑整个向量化数据的分析和检索。
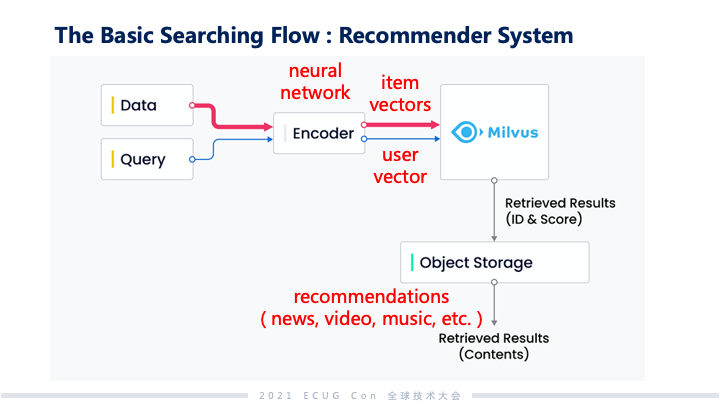
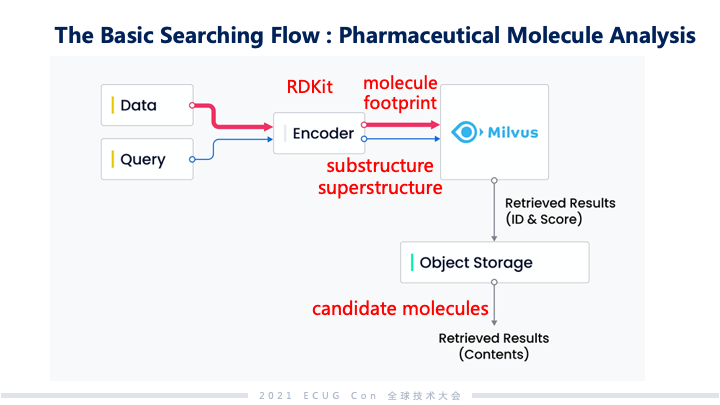
搜索的流程大致上分为 AI 驱动的搜索与神经驱动的搜索。数据和查询语义这两方面都通过 Encoder 投射到 embedding 空间里面去产生向量,查询到的结果会以 ID 或者是打分的形式投出来,然后再根据这些 ID 找到对应原始存储里面的物料。以推荐系统为例,推荐系统里利用了许多神经网络模型,在通过这些模型之后,比如说我们刷的视频或者是文本新闻这些信息会形成 item vectors;对应的用户使用偏好也会形成 user vectors,这两个 vectors 在 Milvus 里面去做综合的分析。从这些用户最近被观察到的行为分析下来以后,哪些内容是他们最感兴趣的,最终通过系统反馈之后给出来的,就是大家手机上看到的一系列的推荐内容。生物制药分析也是可以透过这样的方式去做分析和搜索。药物筛选时,会从药物的子结构去匹配病毒上面的蛋白质特征,如果能匹配上那就意味着它们有可能产生一个治愈的效果。在 embedding 或者是向量空间里面,可能产生效果的药物和病毒的分子结构距离会比较近。最终筛选出的结果会是一系列候选的药物分子式,以及关于药物的详尽内容。这些信息会进一步再给医药的专家们做更深入的分析。 Milvus vs. ElasticSearch
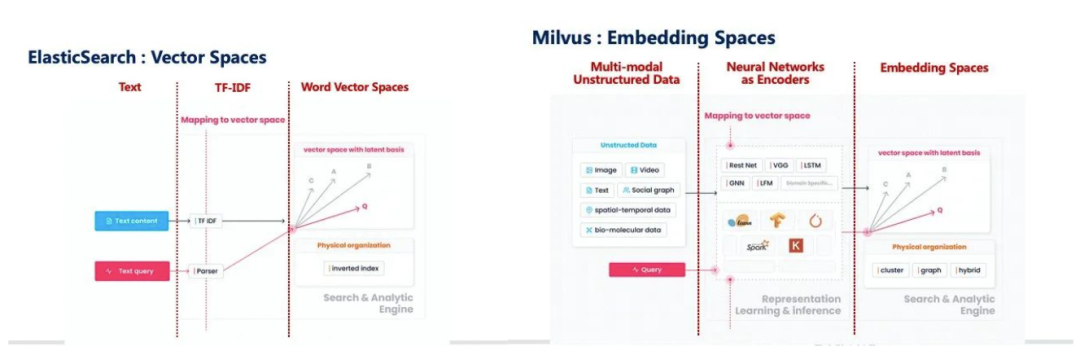
Milvus 与 ElasticSearch 有什么区别?这是我们经常被问到的问题。两者都是面向非结构化数据做分析,ES 这边更多是作用在文本这个点上,也是文本搜索的事实标准;Milvus 则作用在 embedding 这个数据基础上,提供的是一种泛化的搜索能力,并不会像 ES 这样面向一种具体的非结构化数据。整体上来看,其实整个分析和搜索的机制,ES 和 Milvus 还是有很大的相似性的,基本上大家都做同样的一件事情——把非结构化数据映射到一个空间里面,在空间里面做语义的相似度分析。像 ES 文本和查询条件通过 TF-IDF 这样一个统计量去放到子向量空间里面去做分析;Milvus 则是更多是把多样化的非结构化数据去经过一些神经网络作为 Encoder,映射到 embedding 空间里面去做分析。 如何权衡 CAP?
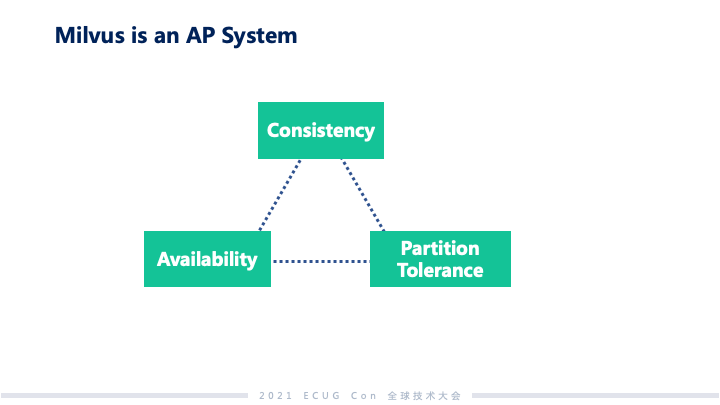
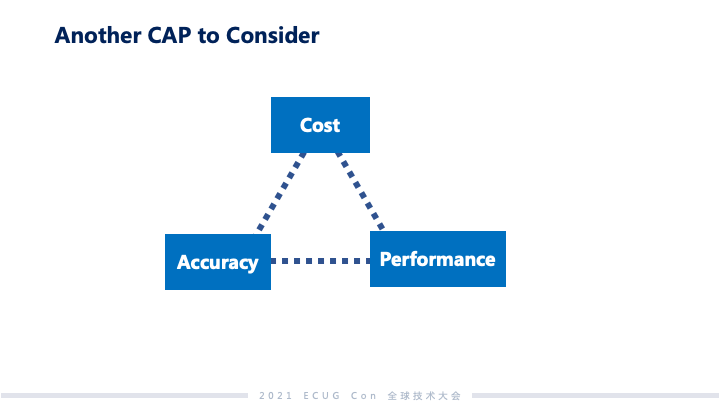
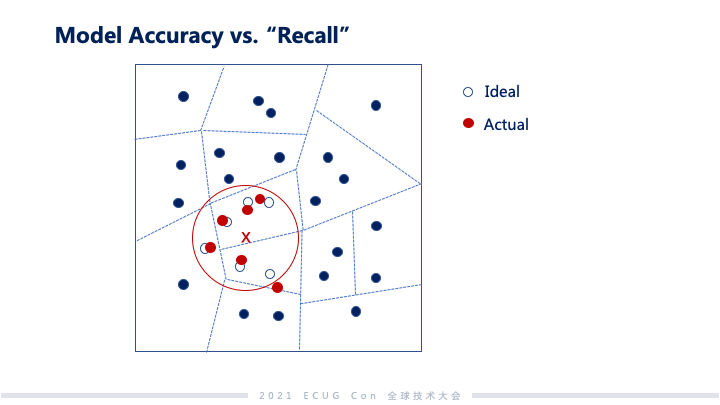
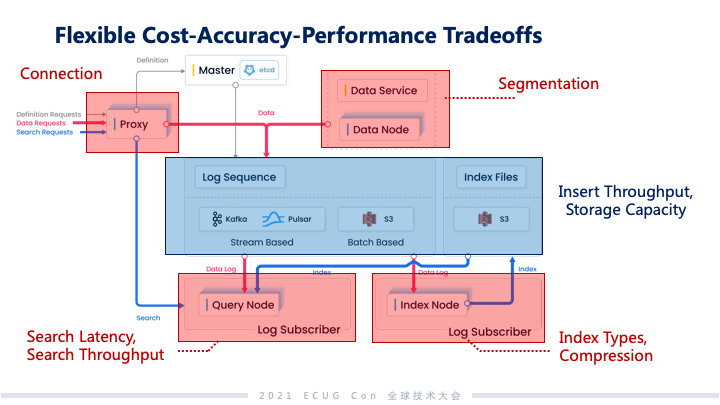
从 Milvus 项目开始到现在历经了一年多时间,我们在做这个项目中也遇到了很多 CAP tradeoff 的问题,接下来我将会分享我们在这方面的经验。第一类系统:比较典型的像 TP 类的数据库系统,更加关注的像事物性、强一致。第二类系统:更多关注的是在以往的全量数据上面做推理和分析,从而挖掘数据的价值。Milvus 属于第二类系统。第二类系统,基本上都是 AI 和神经网络做驱动的,这些系统更多讲的不是 100% 准确,一方面理论上有一些方法上限到不了 100%;另外一方面,虽技术上可以达到 100%准确,但是最后一公里的成本会非常高。 这个图是我们做检索准确度和检索性能的一个关系,可以看到随着准确率越来越逼近 100%,整个系统性能呈现急剧下降的趋势。对应来说,成本上面要保证足够的投入才可以同时得到高准确度与高性能。我们开发 Milvus 系统的时候,还遇到了另外一个 CAP 要去做权衡,那是什么呢?就是成本(Cost)、准确度(Accuracy)和性能(Performance)这三个的权衡。在非结构化数据分析领域,用户在这个三角里面应用的点是很不一样的。比如说在大规模的推荐系统里,性能和准确度实际上和系统用户的体验和黏性非常相关,所以在规模大的时候,对于成本上升还可以接受。但对于我们刚刚讲的生物制药这一类,基本上是离线去做筛查药物的侯选,这个时候对于性能没有那么敏感,更多时候用户可能会选择拿性能去换成本。所以第二类系统,其实不是 100% 准确反而比较重要,因为我们要去在里面给用户足够的空间,让他们根据成本、性能、准确度做 tradeoff。我们发现其实还蛮难的,因为准确度这个事情和系统里面很多的因素都有关系。Milvus 是一个搜索系统,和准确度相关的最主要的一个指标就是 Recall,中文叫做查询率。一个查询如果查询返回的结果都是我想要的,那准确率就是 100%,如果有 10 条不是我想要的,查询率就是 90%。Embedding 的准确度、索引的类型、是否使用压缩数据的方式、传统的一致性,还有可变性等这些都会有影响。举个例子,像模型的准确度和查询准确度的变化,因为神经网络这样一些模型很难做到 100% 准确,这样用这些模型做 embedding,最终产生的 embedding 的向量和实际理想的向量有一定的偏差,这些偏差会导致搜索最后结果准确度的变化。我们发现在 Milvus 应对的场景中,系统读副本和写入之间的延迟对 Recall 影响最低,基本上就是小数点后面几位。给我们的启发就是,可以拿一致性换其他的系统指标。我们也将这个思路应用到了 Milvus 2.0 的架构设计上。 Milvus 2.0
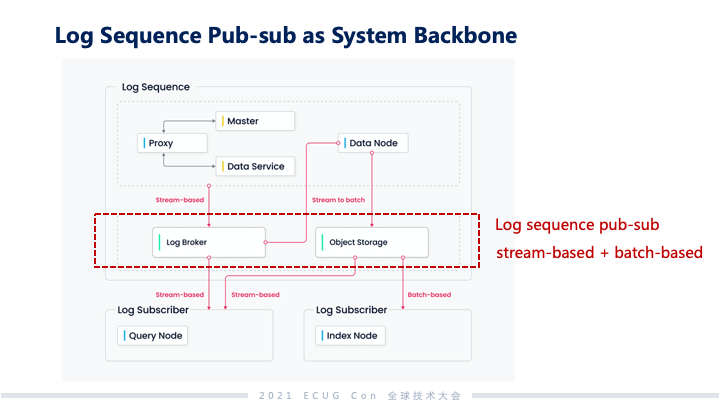
流批融合的日志系统
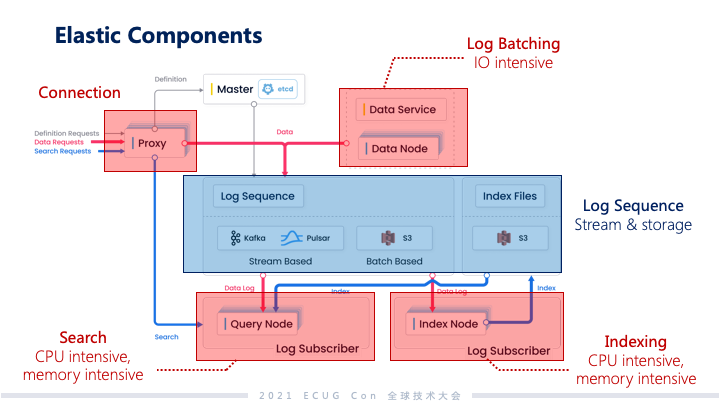
我们做的最主要的一件事是把日志子系统提出来,像这样的系统对于数据一致性的要求要低很多。我们还构建成流批融合的日志系统,这个系统是支持发布和订阅的。批处理的部分和流处理的部分我们分成两层,流的部分做到能够让订阅者或者是系统的副本快速看到变化,能够达成近实时同步的能力。批这部分的日志是面向系统全量日志维护的能力,具备更高的可靠性和更大的容量。因为 Milvus 的系统主要的服务都是基于索引的,我们会在向量和标签上面构建丰富的索引生态,再往上的生态和搜索都是索引基础之上做的,所以索引没有做传统数据库的图表结构。Milvus 里面把数据作为日志,没有做独立的库表结构,很大程度上降低了数据维护的复杂度。另外在发布和订阅层面,我们和其他相关的项目一样,也是把相关日志逻辑的通道和物理的通道做隔离,这样整个日志系统能够比较好地做伸缩。把日志系统提出来之后系统变成这样子,中间蓝色部分是日志序列。我们可以支持用户去选择底层的引擎,在这个基础之上,其他的系统组件被自然解耦出来,这些组件可以做分组件级别的组内的弹性。这个对于 Milvus 来说非常重要,因为向量分析是属于一种计算密集和内存密集的应用。像上面一些日志的规整、连接管理模块和下面偏计算的节点所需要的资源类型都不太一样。根据用户负载的不同和对应他们占用到的物理资源,可以独立地去做弹性,这样一方面可以综合帮助用户达到一个比较好的降成本的效果,另外也可以独立地调动对于系统来说比较好的机制。除了节点可以独立地调动之外,这样的结构可以很好地去做支撑查询的准确度、性能等。上面提到需要做 CAP 权衡的,像索引的类型、数据量的压缩,还有查询的延迟、查询的吞吐,这些都可以落到不同的系统模块里面。根据用户对 CAP 不同的考量,这些系统模块可以做灵活的适配和相应的裁剪。 其他的探索工作
硬件加速向量搜索
整个向量的分析和处理,其实对于算力的要求是非常高的,成本也很高。神经网络之所以在近几年有了很好的发展,一方面是数据规模的影响,另一方面更多是算力。现在通用 GPU 发展起来后,通用的算力大幅提升。Milvus 目前也与英伟达和澜起科技、寒武纪做了面向 embedding 检索的一系列的基础高性能算法库。Milvus 现在对 CPU 的支持和 GPU 都比较完善,FPGA 和 MLU 这块,我们也在和澜起科技、寒武纪在进一步合作中。自动化系统调优
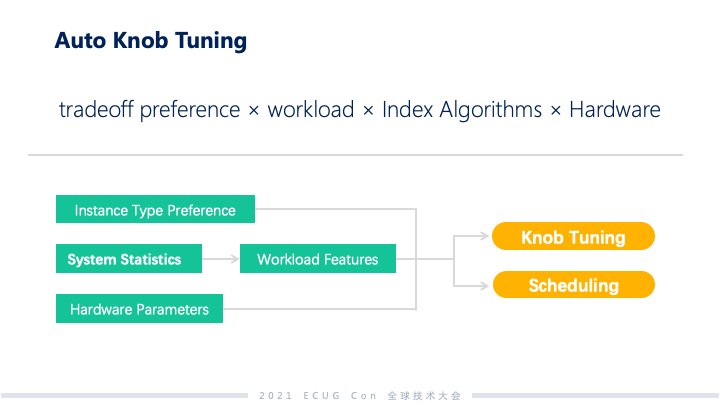
以前其他的数据库系统很复杂,参数也很多,所以一定要有 DBA 了解你的系统、了解你的负载,并在了解之后帮你把系统调到最优的工作状态。Milvus 这个系统存在同样的问题,刚才我们讲用户需做准确度、性能、成本的权衡,还有索引算法等的选择。每个算法有参数,最后乘以硬件的加速,整个乘起来对系统的参数选择和搜索空间就很大了。这些问题对于用户来说都很难回答。讲道理一个易用的系统用户也不需要关心这些问题。我们现在打算尝试的一个方法是基于 AI 的一些手段去系统里面采集比较丰富的用户特征数据,再用 AI 的算法构建系统自动调优的工具。整体来讲这些工具面向两点,一个是系统参数自动调优化,另外一点就是系统内部的资源调度。这样用户能够比较好地去用这些系统,而不是说陷入一个泥潭里面,调这些他们暴露出来的很复杂的系统内部的问题。最后,希望大家能够关注到我们项目,或是参与到我们社区里面来。Milvus 是数据库和 AI 交叉的领域,有很多新的挑战要去探索。希望各位大牛加入我们这个非结构化数据分析和向量搜索的全新领域,谢谢大家!
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量相似度搜索引擎,以加快下一代数据平台的发展。Milvus 目前是 LF AI & Data 基金会的孵化阶段项目,能够管理大量非结构化数据集。我们的技术在新药发现、计算机视觉、推荐引擎、聊天机器人等方面具有广泛的应用。
欢迎加入 Milvus 社区
github.com/milvus-io/milvus | 源码zhihu.com/org/zilliz-11| 知乎zilliz.blog.csdn.net | CSDN 博客
space.bilibili.com/478166626 | Bilibili