




一、概述
随着应用的微服务化改造、数据分库分表、数据量越来越大,传统的DB自增ID难以满足大型分布式应用的需求,那么本篇来阐述分布式全局唯一ID的理论和实践。
实践中,业务对分布式ID规则有哪些要求?对分布式ID系统有什么要求?分布式ID算法有哪些?业内大厂是怎么用的?我们又是怎么玩的?接下来一一揭晓。
二、分布式序列要求
分布式序列是一个通用的产品,要满足以要求:
2.1、全局唯一性
在同一场景下不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
2.2、趋势递增
在主键的选择上面我们应该尽量使用有序的主键保证写入性能、同时有利于索引提高查询的性能。
2.3、序列数据类型
序列的数据类型决定的存储空间大小,序列尽可能用整类型,以MYSQL bigint unsigned为例存储空间为8字节,范围(0~2*2^63-1 )是一个极大的整数,足以满足需求。
2.4、简单易用
能够拿来即用,接入方便,同时在系统设计和实现上要尽可能的简单。
三、序列常用算法
3.1、UUID
UUID 含义是通用唯一识别码 (Universally Unique Identifier),这是一个软件建构的标准。UUID是由一组32位数的16进制数字所构成,UUID理论上的总数为16^32=2^128。若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
UUID组成:
标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12)。
优点:
1. 本地生成,无依赖,速度极快,序号个数无限。
2. 序号全局唯一性。
不足:
1. 序列无规律,对索引不友好。
2. 字段串由数字与字母组合,存储空间大。
3.2、雪化算法(snowflake)
snowflake是Twitter开源的分布式ID生成算法,支持多语言(Java、go、scala等),结果是一个64bit大小的整型的ID。结构图如下:
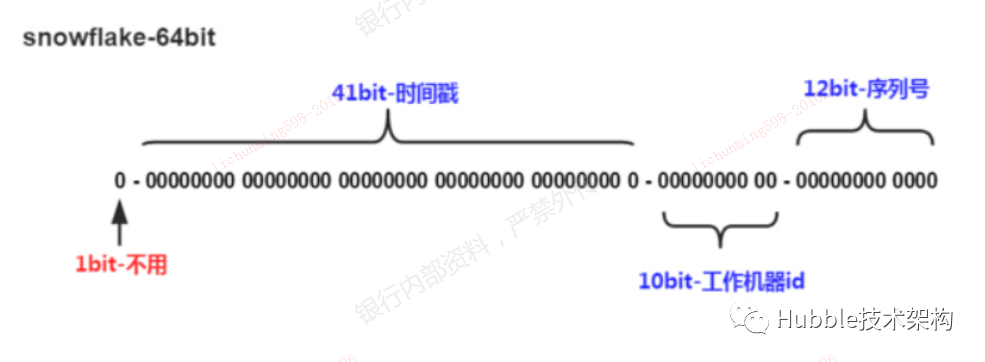
位数说明:
| 标识 | 位数 | 说明 |
| 序列号 | 12bit | 毫秒内的计数,12位的计数顺序号最大支持每个节点每毫秒产生4096个ID序号。 |
| 数据机器位 | 10bit | 最大支持1024个节点,包括5位datacenterId和5位workerId。 |
| 时间戳 | 41bit | 存储时间截的差值,41位的时间戳,毫秒级,可以使用69年。 |
| 标识 | 1bit | 正数是0,负数是1,ID一般是正数,最高位是0。 |
优点:
1. 本地生成,无依赖。
2. 整型,趋势递增,有效利于索引。
3. 效率较高,理论每节点每秒最大能产生26万ID。
不足:
1. 依赖机器时间,如果发生时钟回拨会导致可能生成id重复。
2. workid节点有限,无存储容易碰撞,在超大服务集群使用有风险。
3.3、基于DB数据段算法
利用DB表的存储机制,表主要字段有:命名空间、当前最大值、步长、版本号。通过步长的大小及利用缓存数据段来控制,解决DB的性能瓶颈,提高效率。
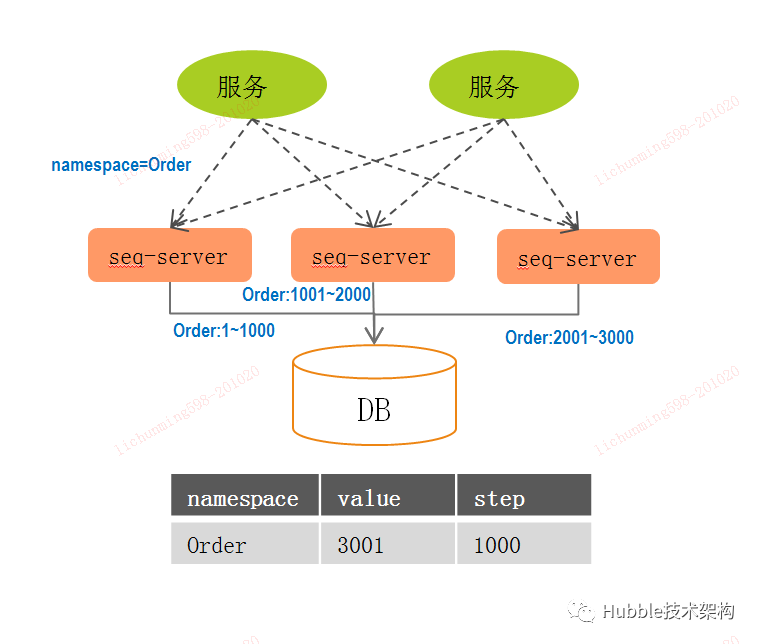
数据库表主要字段:
| 字段 | 字段名称 | 说明 |
| version | 版本号 | 用于防并发的乐观锁。 |
| value | 当前最大值 | 当前namespace业务场景的最大值。 |
| step | 步长 | 每次从数据库获取序号段到服务节点内存,步长越大对DB的压力越小。 |
| retrytimes | 重试次数 | 乐观锁更新异常时重试次数。 |
| namespace | 命名空间 | 业务场景,用于区分不同的业务。业务之间相互隔间,互不影响。 |
优点:
1. 高性能,序列无极限(取决于步长长度)。
2. 整型,有顺序,趋势递增,有利于索引。
3. 可以自定义value的大小,非常方便业务从原有的ID方式迁移过来。
不足:
1. 服务强依赖DB,来存储业务场景、最大值、步长等信息。
2. 中心化部署,序列号段缓存服务节点,对序列服务可靠性要求极高。
四、业内大厂序列方案
4.1、美团点评(Leaf)
Leaf美团点评分布式ID生成系统,leaf是基于springboot、以HTTP协议的方式提供获取分布式唯一ID的服务。总计集成了两种模式:Leaf-snowflake算法和Leaf-segment(基于DB数据段算法)。
Leaf-segment在基于DB数据段算法上进行了优化:在号段消耗的临界点的ID时,会用异步线程从DB获取新的号段,补充进行到内存中,避免号段消耗再补充新的号段。
Leaf-snowflake在原生snowflake进行了优化,弱依赖Zookeeper及延迟3秒上报时间差,可以缓解时间回拔的问题。
优点:
1. Leaf-segment 双buffer优化,避免号段消耗完,再更新DB的TP999波动。
2. Leaf-snowflake 缓解时间回拔的问题。
不足:
1. 中心化的部署,通过http获取序列,存在网络开销。
2. Leaf-server故障会影响所有序列的生成,必须保证Leaf-server可用性100%。
部署方式:
中心化部署,leaf-server是基于springboot,以HTTP协议的方式提供获取分布式唯一ID的服务。
4.2、滴滴出行(Tinyid)
Tinyid是滴滴出行推出的分布序列生成器。Tinyid是基于美团点评分布式ID生成系统(Leaf)基础上进行了优化。
优化办法:
1. 双号段缓存,提前异步加载下一个号段,避免号段消耗再补充新的号段。
2. 增加tinyid-client,把号段缓存在应用的客户端,有效的减少Tinyid-server的网格开销。
最终架构图如下:
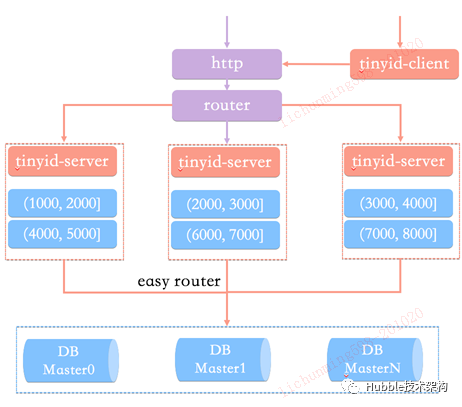
优点:
1. Tinyid提供http和tinyid-client两种方式接入。
2. tinyid-client有效的减少的网格开销,大大提高了性能。
3. tinyid-server容忍短时间的down掉,大大的提高了可用性。
不足:
暂无
部署方式:
中心化部署,tinyid-server是基于springboot,以HTTP协议及tinyid-client两种方式提供获取分布式唯一ID的服务。
4.3、百度(UidGenerator)
UidGenerator是百度开源的Java语言实现,基于雪花算法的唯一ID生成器。对Snowflake算法的组成部分进行了调整、优化和改进,并解决workid不足及时钟回拨序列重复的问题。它通过消费未来时间克服了雪花算法的并发限制,UidGenerator提前生成ID并压测结果显示,单独实例的QPS理论最大值超过600W。
Uid结构图:

位数说明:
| 标识 | 位置 | 说明 |
| 标识 | 1bit | 正数是0,负数是1,ID一般是正数,最高位是0。 |
| 时间截 | 28bit | 存储时间截的差值,28位的时间截,可以使用8.5年(2^28-1/86400/3655)。 |
| 数据机器位 | 22bit | 最大支持400W个节点。 |
| 序列号 | 13bit | 毫秒内的计数,13位的计数顺序号最大支持每个节点每毫秒产生8192个ID序号。 |
默认调整了各段的位数。
优点:
1. QPS最大值突破生原nowflake算法的限制。
2. 解决了时钟回拨序列重复的问题。
3. 通过依赖DB优化workid顺序问题,并提升了节点数。
4. snowflake结构图可以自定义调整。
不足:
1. 在原生Snowflake算法新增了DB的依赖。
2. 因调整时间部分位数,Uid寿命减短,只能承受8.5年(2 ^ 28-1 86400/365)。
3. 中心化的部署,通过HTTP获取序列,存在网络开销。
4. uid-server故障会影响所有序列的生成,必须保证uid-server可用性100%。
部署方式:
中心化部署,uid-server是基于springboot,以HTTP协议的方式提供获取分布式唯一ID的服务。
4.4、阿里(TDDL-sequence)
TDDL(Taobao Distributed Data Layer)是阿里的一个分库分表数据库中间件,它在阿里内部被广泛的使用,主要是为了解决分布式数据库产生的相关问题。而tddl-sequence 顾名思义,为解决分布式序列而生的组件。
tddl-sequence的原理基于DB数据段算法,以客户端JAR方式的与应用共存,在应用的DB中创建序列表,并利用应用的数据源,在本地生成序列。这种去中心化部署,减少获取序列http接口的网络开销,也不担心seq-server故障的带来的风险。
tddl-sequence架构图:
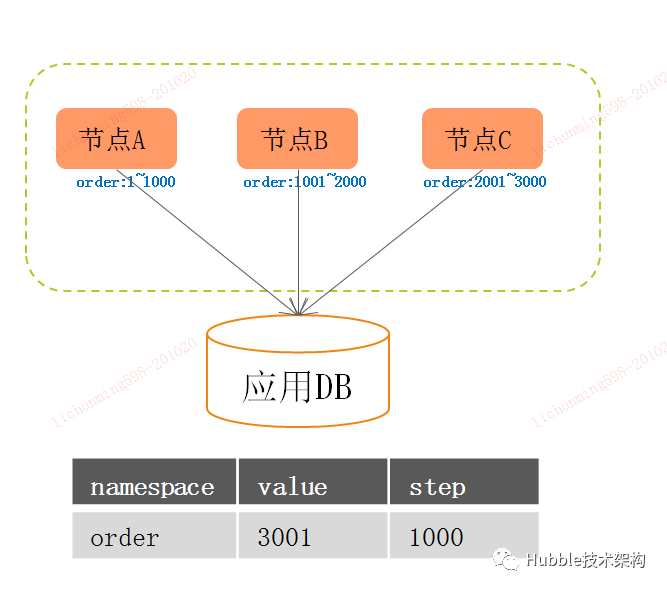
优点:
1. 去中心化部署,本地获取序列,本地缓存号段,极大提高序列的性能。
2. 不同应用之间的序列生成互不影响,极大提高容错性了。
不足:
1. 接入的复杂度增加,每个应用都要创建自己的序列表。
部署方式:
分布式部署方式,以JAR的方式与应用有机的结合在一起。
五、序列部署方式(中心化 & 分布式)
在前面介绍的各大厂的分布式序列的方案中,部署方式分为:中心化、分布式两方式,两者之间对序列的性能、可用性、数据一致要求是不一样的。
中心化部署:
中心化部署是指:序列以微服务的方式单部署,连接独立的序列库。提供Http、RPC、restful等协议的接口,给各应用调用并返回序列或号段。
分布式部署:
分布式部署是指:序列以组件JAR的方式,应用有机的结合一起部署,把序列的相关表,与应用的数据表放一个库,共用数据源。
两者的要求区别如下:
| 项目 | 中心化 | 分布式 |
| 高性能 | 平均延迟和TP999延迟都要尽可能低 | 当前本地生成,无网络开销,性能高 |
| 可用性 | 无限接近于100%的可用性,但可用性达到99.999(5个9) | 与当前应用的可用性一致。 |
六、hubble-sequence
哈勃分布式序列(hubble-sequence) 是参考了业内大厂的几个分布式序列方案后,全面了解各方案的优缺点,并结合行内的实际情况形成的方案。最终采用非中心化部署的阿里tddl-sequence为基于DB数据段算法的原型,这命名为AI (AutoIncre简写),并集成雪化算法(snowflake)。
Hubble-sequence哈勃序列生成工具。确保全局唯一、高性能序列的组件。内置丰富的算法,满足各种序列场景的需求。
架构图如下:
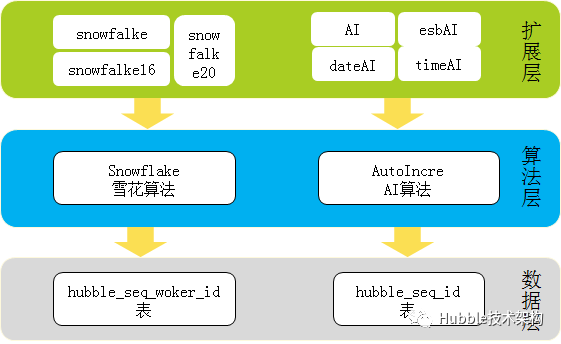
算法介绍:
| 算法 | 类型 | 功能描述 |
| snowflake | Long | 原生的snowflake算法。 |
| snowflake16 | String | 原生snowflake算法转36进制(13位)+随机转36进制(3位) 长度固定16位。 |
| snowflake20 | String | 原生snowflake算法转36进制(13位)+namepace转36进制(4位)+随机转36进制(3位),长度固定20位. |
| ai | Long | 从0-Long.MAX_VALUE,最大19位数据足够大,不支持循环。 |
| dateAI | Long | 格式:yyyyMMdd+序列。 11位自增序列:从00000000001-99999999999 支持循环:当序列大于99999999999时自动归位00000000001 |
| esbAI | String | 格式:系统号(6位)+yyMMdd(6位)+序列(10位) 10位自增序列:从0000000001-9999999999 支持循环:当序列大于9999999999时自动归位0000000001 |
| timeAI | Long | 格式:yyMMddHHmmss 7位自增序列:从0000001-9999999 支持循环:当序列大于9999999时自动归位0000001 |
优点:
1. 非中心化部署,本地获取序列,本地缓存号段,极大提高序列的性能。
2. AutoIncre算法不同应用之间的序列生成互不影响,极大提高容错性了。
3. 支持halo、spring boot、pafa5架构。
4. 扩展算法丰富,满足各种序列场景的需求。
不足:
1. 接入复杂度增加,每个应用都要创建自己的序列表。
部署方式:
去中心化部署方式,以jar的方式与应用有机的结合在一起。
七、总结
分布式序列各大厂公司做法都差不多,无非都是在snowflake、基于DB数据段两大基础算法及结合自身的特点做优化。
hubble-squence后续会增加中心化的方式来满足各种业务方的需求。
