





介绍
GoogleAI研究人员提出了一种帧插值算法,该算法从近乎重复的照片中合成清晰的慢动作视频,这些照片通常表现出大的场景运动。近重复插值是一种新颖而有趣的应用。然而,大运动对现有方法提出了挑战。已经提出了大运动帧插值 (FILM)架构来解决这个问题。在本文中,我们将更详细地研究这种架构。
现在,让我们开始吧!
强调
FILM 是一个帧插值神经网络,它采用两个输入图像并生成/插值中间图像。它在常规视频帧三元组上进行训练,中间帧作为监督的基本事实。
本质上,FILM 架构采用了一个与尺度无关的特征金字塔,它在不同尺度上共享权重,这使我们能够构建一个“与尺度无关”的双向运动估计器,它可以从正常运动的帧中学习,并很好地推广到具有大运动的帧.
为了处理由大场景运动引起的广泛遮挡,FILM 通过匹配ImageNet预训练 VGG-19 特征的 Gram 矩阵进行监督,这有助于创建逼真的修复和清晰的图像。
FILM 在处理小/中等动作的同时在大动作上表现出色,并产生时间上平滑的高质量视频。
什么是帧插值?
顾名思义,帧插值是从给定的一组图像中生成/插值图像的过程。这种方法通常用于提高视频的刷新率或实现慢动作效果。
为什么我们需要类似电影的模型?
使用当今的数码相机和智能手机,我们经常快速拍摄多张照片以获得最佳照片。在这些“近乎重复”的照片之间进行插值可以产生有趣的视频,这些视频突出了场景运动,并且经常传达出比原始照片更愉悦的瞬间感。
与视频不同,近乎重复的图像(快速连续捕获)之间的时间间隔可能是几秒钟,中间运动成比例地较大,这是现有帧插值技术的主要缺点。最近的技术试图通过训练极端运动数据集来处理大运动,尽管它们对较小的运动无效。为了解决这些问题,建议使用 FILM 架构从近乎重复的图像中生成高质量的慢动作视频。FILM 是一种神经网络架构,可以处理具有 SoTA 结果的大运动,同时也能很好地处理较小的运动。

GIF 1:FILM 架构通过插入两个近乎重复的图像创建的慢动作视频(来源 GoogleAI)
电影模型概述
图 1 说明了FILM 架构,它由以下三个组件组成:
1. 一个与尺度无关的特征提取器,用深度多尺度金字塔特征总结每个输入图像
2. 一个双向运动估计器,在每个金字塔级别计算像素级运动
3. 生成最终插值图像的融合模块。
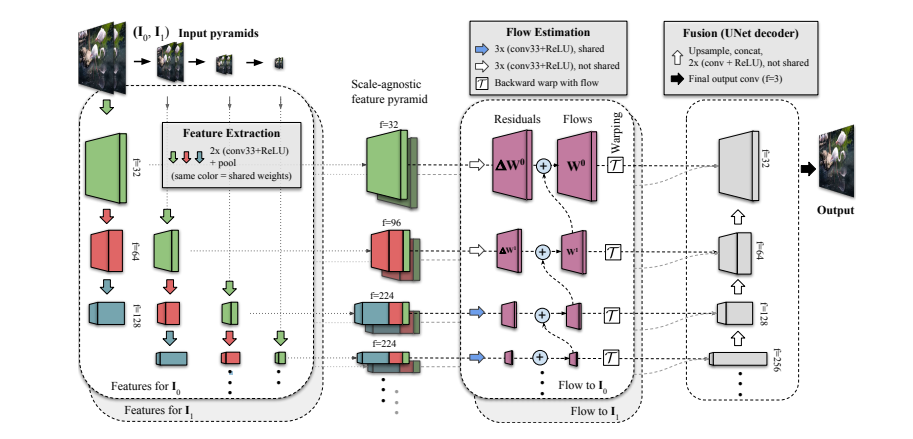
图 1:FILM 模型架构
现在让我们更详细地了解每个组件。
1) 与尺度无关的特征提取: 为了处理可能在最深金字塔级别消失的小型和大型快速移动对象,使用了一个特征提取器,该特征提取器在不同尺度上共享权重,以创建一个“与尺度无关”的特征金字塔.
该特征提取器 i) 通过将浅层的大运动与深层的小运动等同起来,实现了跨金字塔层级的共享运动估计器(第二个模块),并且 ii) 有助于创建一个权重更少的紧凑网络。
给定两个输入图像,通过成功地对每个图像进行下采样来更详细地创建图像金字塔。接下来,使用共享的 U-Net 卷积编码器从每个图像金字塔级别中提取一个较小的特征金字塔(参见以下 GIF 中的列)。最后,水平构建一个与尺度无关的特征金字塔,连接从共享相同空间维度的不同卷积层获得的特征。值得注意的是,从第三级开始,特征堆栈由相同的共享卷积权重集(以相同颜色显示)构成。这确保了所有特征都是相似的,以便可以在随后的运动估计器中共享权重。此外,该图显示了四个金字塔级别,但实际上使用了七个。

GIF 1:描绘整个过程的动画
2) 双向流估计:FILM 在特征提取之后执行基于金字塔的剩余流估计 ,以确定从尚未预测的中间图像到两个输入的流。
在一堆卷积的帮助下,从最深的层次开始对每个输入进行流估计。通过将残差校正添加到来自下一个更深级别的上采样估计值来估计给定级别的流量。这种方法采用以下输入:i)来自该级别的第一个输入的特征,以及 ii)与上采样估计值扭曲的第二个输入的特征。除了两个最高级别,所有级别共享相同的卷积权重。
共享权重有助于将更深层次的小运动解释为类似于浅层次的大运动,从而增加可用于大运动监督的像素数量。此外,模型需要共享权重以适应实际应用的 GPU 内存,并训练可以实现更高峰值信噪比 (PSNR) 的模型。

图 2:描述权重共享对图像质量影响的图像(左:无权重共享,右:权重共享)
3) 用于中间帧生成的融合模块:估计双向流后,将两个特征金字塔扭曲对齐。通过在每个金字塔级别进行堆叠获得连接的特征金字塔。最后,在 U-Net 解码器的帮助下,从对齐和堆叠的特征金字塔创建插值输出图像。
损失函数:在实验中发现,结合绝对L1、感知损失和风格损失这三种损失,相比于用绝对L1损失和感知损失训练FILM,大幅提高了清晰度和图像保真度。

评估结果
FILM 在包含具有大场景运动的近乎重复照片的内部数据集上进行了评估。此外,将 FILM 与最近的帧插值方法(如 SoftSplat 和 ABME)进行了比较。在跨大运动进行插值时,FILM 表现良好。即使运动高达 100 像素,FILM 也能生成精确到输入的清晰图像。
结论
总而言之,在本文中,我们学到了以下内容:
- FILM 模型是一种与尺度无关的神经网络架构,用于从近乎重复的图像中生成高质量的慢动作视频。
- FILM 架构由三个组件组成:i) 与尺度无关的特征提取器,ii) 双向流估计器,以及 iii) 用于中间帧生成的融合模块。
- 与尺度无关的特征提取器用深度多尺度金字塔特征总结每个输入图像,双向运动估计器计算每个金字塔级别的像素运动,融合模块生成最终的插值图像。
- FILM 架构采用了一个与尺度无关的特征金字塔,它在不同尺度上共享权重,这使我们能够构建一个“与尺度无关”的双向运动估计器,它可以从具有正常运动的帧中学习,并很好地推广到具有大运动的帧。
- 在实验过程中发现,与使用绝对L1损失和感知损失训练FILM相比,结合绝对L1损失、感知损失和样式损失这三种损失可以大大提高清晰度和图像保真度。
- FILM 模型在处理中小动作的同时,在大动作上表现良好,可生成时间上平滑的高质量视频。
原文标题:FILM Model: Scale-Agnostic NN Architecture for Creating High-Quality Slow-Motion Videos
原文作者:Drishti Sharma
原文地址:https://www.analyticsvidhya.com/blog/2022/10/film-model-scale-agnostic-nn-architecture-for-creating-high-quality-slow-motion-videos/
