




介绍
最近,每当我们希望在机器学习中进行图像分割时,我们想到的第一个模型就是 U-Net。与以前最先进的方法相比,它在性能改进方面具有革命性意义。U-Net 是一种编码器-解码器卷积神经网络,具有广泛的医学成像、自动驾驶和卫星成像应用。然而,重要的是要了解 U-Net 如何执行分割,因为 U-Net 之后的所有新架构都是在相同的直觉上开发的。我们将深入了解 U-Net 如何执行图像分割。为了增强我们的理解,我们还将把 U-Net 应用于大脑图像分割的任务。
图像分割
在我们了解为什么 U-Net 在图像分割任务中如此受欢迎之前,让我们了解什么是图像分割。计算机视觉一直是机器智能众多令人兴奋的应用之一。它在当今世界有许多应用,让我们的生活更轻松。两个最常见的计算机视觉任务是图像分类和对象检测。
两个类别的图像分类涉及预测图像是属于 A 类还是 B 类。预测的标签被分配给整个图像。当我们想查看图像中的类别时,分类很有帮助。
另一方面,对象检测通过预测对象在我们输入图像中的位置来进一步实现这一点。我们通过在对象周围绘制边界框来定位图像中的对象。检测对于定位和跟踪图像的内容很有用。
图像分割可以被认为是分类和定位的结合。
图像分割涉及将图像分割成更小的部分,称为片段。分割用于了解图像在像素级别上给出的内容。它提供有关图像的细粒度信息以及对象的形状和边界。图像分割的输出是一个掩码,其中每个元素指示该像素属于哪个类。让我们通过一个例子来理解这一点。

如上所示,左边是我们的猫的输入图像。我们的任务是将猫从背景中分离出来。所以我们有两个输出类——cat 和 background 。然而,在将这只猫从它的背景中分离出来时,我们需要知道这只猫在图像中的确切位置。我们要找到两个问题的答案——
1. 输入图像中有“什么”?
Ans: Cat and Background
2. 输入图像中那个物体在“哪里”?
Ans:图片中猫的位置
图像分割逐个像素地解决了上述问题。我们希望将相似的像素分组并分离不同的像素。在每个像素上,我们将执行该像素是猫的一部分还是背景的分类任务。因此,我们的模型预测为属于猫的所有像素都将具有标签 1,其余像素将具有标签 0。在此过程中,我们将创建输入图像的掩码,如上所示,并且在在这个逐像素分类结束时,我们也会检测到猫在我们的图像中的确切位置。
现在我们已经了解了分割,让我们了解 U-Net 模型。
网络
U-Net 由 Olaf Ronneberger 和他的团队于 2015 年开发,用于生物医学图像方面的工作。它通过使用更少的图像和数据增强来提高模型性能,从而超越了滑动窗口技术,从而赢得了ISBI挑战。
滑动窗口架构在任何给定的训练数据集上都能很好地执行定位任务。它用于为每个像素创建一个局部补丁,为每个像素创建单独的类标签。然而,这种架构的两个主要缺点是,首先,由于补丁重叠,会产生大量的整体冗余。其次,培训过程缓慢,耗费大量时间和资源。这些原因使得该架构不适用于各种任务。U-Net 克服了这两个缺点。
我们最初讨论了分割如何由分类和定位组成。让我们了解 U-Net 如何执行这两个任务以及为什么它如此适合分割。
U-Net 得名于其架构。“U”形模型包括卷积层和两个网络。首先是编码器,然后是解码器。借助 U-Net,我们可以解决上述两个分割问题:“what”和“where”。
.jpg)
模型架构来源
编码器网络也称为承包网络。该网络学习输入图像的特征图并尝试解决我们的第一个问题——“图像中有什么”?它类似于我们使用卷积神经网络执行的任何分类任务,除了在 U-Net 中,我们最终没有任何完全连接的层,因为我们现在需要的输出不是类标签而是掩码与我们的输入图像大小相同。
该编码器网络由 4 个编码器块组成。每个块包含两个卷积层,内核大小为 3*3 和有效填充,后跟一个 Relu 激活函数。这被输入到内核大小为 2*2 的最大池化层。通过最大池化层,我们将学习到的空间维度减半,从而降低了训练模型的计算成本。
在编码器和解码器网络之间,我们有瓶颈层。这是最底层,正如我们在上面的模型中看到的那样。它由 2 个卷积层和 Relu 组成。瓶颈的输出是最终的特征图表示。
现在,使 U-Net 在图像分割方面如此出色的是 跳过连接和解码器网络。到目前为止,我们所做的与任何 CNN 都相似。跳过连接和解码器网络将 U-Net 与其他 CNN 分开。
解码器网络也称为扩展网络。我们的想法是将我们的特征图上采样到输入图像的大小。该网络从瓶颈层获取特征图,并在跳过连接的帮助下生成分割掩码。解码器网络试图解决我们的第二个问题——“图像中的物体在哪里”?它由 4 个解码器块组成。每个块都以转置卷积(在图中表示为 up-conv)开始,内核大小为 2*2。该输出与来自编码器块的相应跳过层连接相连接。之后,使用两个内核大小为 3*3 的卷积层,然后是一个 Relu 激活函数。
跳过连接在模型架构中用灰色箭头表示。跳过连接帮助我们使用在编码器块中收集的上下文特征信息来生成我们的分割图。这个想法是使用我们从编码器块中学习的高分辨率特征(通过跳过连接)来帮助我们投影我们的特征图(瓶颈层的输出)。这有助于我们回答“图像中的对象在哪里”?
一个 1*1 卷积跟随最后一个带有 sigmoid 激活的解码器块,它给出了包含逐像素分类的分割掩码的输出。这样,可以说收缩路径将信息传递到扩展路径。因此,我们可以在 U-Net 的帮助下捕获特征信息和定位。
让我们通过 U-Net 的应用来更好地理解模型。
在医学图像处理中的应用
我们以脑肿瘤分割为例。脑肿瘤分割是一项至关重要的任务;早期发现可提高患者的存活率。手动检测这些肿瘤是一项繁琐的任务。使用机器学习自动执行此任务可以帮助医生和患者。我们的应用程序尝试使用 U-Net 预测脑肿瘤位置。
我们使用公开可用的数据集。这个脑肿瘤 T1-Lighted CE-MRI 图像数据集由 3064 张图像组成。冠状图像1047张,轴向图像990张,矢状图像1027张。该数据集为每个图像都有一个标签,用于识别肿瘤的类型。这 3064 张图像属于 233 名患者。该数据集包括三种类型的肿瘤——708 种脑膜瘤、1426 种神经胶质瘤和 930 种垂体瘤。
每个图像的大小为 512X512 像素。让我们分解细分项目的每个步骤。
数据加载-
我们从上面给出的链接下载数据集。数据集需要解压缩并可用。我们的数据集以 matlab 格式给出,因此我们将这些数据转换为图像、标签和掩码的 numpy 数组。我们最终显示每个 numpy数组的大小。
https://gist.github.com/angadbajwa23/595c05a361077dab3b878a15a691c5d6
我们的下一步是预处理这些数据并可视化这些数据。我们显示每个结果以更好地理解我们的数据集。
https://gist.github.com/angadbajwa23/3ebfa554e6e4f0e7e5fbb984e1158b8e
接下来,我们对输入图像进行归一化。这一步之后是定义我们的评估指标。我们使用二元交叉熵、骰子损失和由这两者组成的自定义损失函数。我们还为 train:val:test 拆分使用 80:10:10 的比例,并显示每个的大小。
https://gist.github.com/angadbajwa23/5bfee380692a566476c3e070bb002a67
现在来到我们的 U-Net 模型,如我们上面的解释中所详述:
https://gist.github.com/angadbajwa23/c98cc1cc4d04215f750ba89ced962bec
在对该网络进行 40 个 epoch 训练后,我们的骰子得分为 0.67。以下是对测试集的一些示例预测。
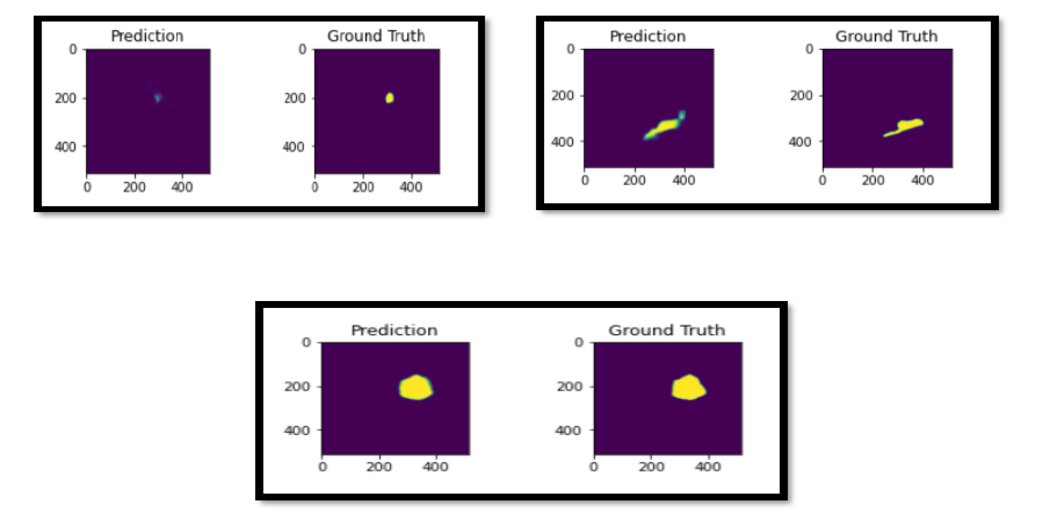
结论
总之,我们已经了解了以下关于图像分割和 U-Net 的内容:
- 图像分割可以被认为是分类和定位任务的组合。
- 我们希望回答图像分割中的两个问题——“什么”和“在哪里”?
- U-Net 的编码器路径回答图像中的“什么”,其行为类似于任何 CNN。
- U-Net 的解码器路径回答“哪里”是图像中的对象,并生成原始图像大小的掩码。
- 跳过连接使我们能够使用在编码器网络中学习到的特征来帮助生成我们的输出掩码。
我们通过上述应用实现了用于生物医学分割任务的 U-Net。同时,我们了解图像分割以及 U-Net 如何处理任何分割任务。我们已经深入了解了模型架构和每一层的功能。
通过为我们的编码器网络预先训练权重,可以进一步改进该模型。U-Net 的几个变体也出现了,但基本的直觉和工作保持不变。
原文标题:Image Segmentation with U-Net
原文作者:Angad Bajwa
原文链接:https://www.analyticsvidhya.com/blog/2022/10/image-segmentation-with-u-net/
