




文章目录
前言
第一部分简单介绍 PostgreSQL 全文检索
第二部分演示全文检索对 json 、 jsonb 数据类型的支持 。
一、PostgreSQL 全文检索简介
对于大多数应用来说全文检索很少在数据库中实现,一般使用单独的全文检索引擎,例如基于 SQL 的全文检索引擎 Sphinx 。PostgreSQL 支持全文检索 ,对于规模不大的应用如果不想搭建专门的搜索引擎, PostgreSQL 的全文检索也可以满足需求 。
如果没有使用专门的搜索引 擎 ,大部检索需要通过数据库 like 操作匹配,这种检索方式的主要缺点在于:
- 不能很好地支持索引,通常需全表扫描检索数据,数据量大时检索性能很低 。
- 不提供检索结果排序,当输出结果数据量非常大时表现更加明显 。
PostgreSQL 全文检索能有效地解决这个问题 , PostgreSQL 全文检索通过以下两种数据类型来实现 。
在 PostgreSQL 10 版本之前全文检索不支持 json 和 jsonb 数据类型, 10 版本的一个重要特性是全文检索支持 json 和 jsonb 数据类型,这一小节将演示 10 版本的这个新特性 。
1. tsvector
tsvector 全文检索数据类型代表一个被优化的可以基于搜索的文挡,要将一串字符串转换成 tsvector 全文检索数据类型,代码如下所示:
postgres=# select 'Hello,cat,how are u?cat is miling!'::tsvector;
tsvector
----------------------------------------------
'Hello,cat,how' 'are' 'is' 'miling!' 'u?cat'
(1 row)
字符串的内容被分隔成好几段
::tsvector只是做类型转换,没有进行数据标准化处理
to_tsvector函数可对于英文全文检索进行数据标准化处理
postgres=# select to_tsvector('english','Hello cat,');
to_tsvector
-------------------
'cat':2 'hello':1
(1 row)
2.tsquery
tsquery 表示一个文本查询 ,存储用于搜索的词, 并且支持布尔操作“&” 、“ | ”、“!”
将字符串转换成tsquery,没有做标准化
postgres=# select 'hello&cat'::tsquery;
tsquery
-----------------
'hello' & 'cat'
(1 row)
to_tsquery 函数可以执行标准化
postgres=# select to_tsquery('hello&cat');
to_tsquery
-----------------
'hello' & 'cat'
(1 row)
全文检索示例:用于检索字符串是否包括“ hello”和“ cat ” 字符,本例中返回真。
postgres=# select to_tsvector('english','Hello cat,how are u')@@to_tsquery('hello@dog');
?column?
----------
f
(1 row)
注:这里使用了带双参数的 to_tsvector 函数,函数 to_tsvector 双参数的格式如下所示:to_tsvector([ config regconfig, ] document text),本节 to_tsvector 函数指定了 config 参数为english ,如果不指定 config 参数,则默认使用 default_text_search_config 参数的配置 。
3.英文全文检索例子
下面演示一个英文全文检索示例,创建一张测试表并插入 200 万测试数据,如下所示:
create table test_search(id int4,name text);
insert into test_search(id,name) select n,n||'_francs' from generate_series(1,2000000) n;
select * from test_search where name like '1_francs';
explain analyze select * from test_search where name like '1_francs';

执行计划进行了全表扫描,执行时间为 145毫秒左右,性能很低
创建索引,再次执行计划
create index idx_gin_search on test_search using gin(to_tsvector('english',name));
explain analyze select * from test_search where to_tsvector('english',name)@@to_tsquery('english','1_francs');

创建索引后,以上查询走了索引并且执行时间下降到0.2毫秒,性能提升了。如果将 SQL 修改为不走索引
explain analyze select * from test_search where to_tsvector(name)@@to_tsquery('1_francs');

由于创建索引时使用的是 to_tsvector(’english’,name)函数索引,带了两个参数,因此 where条件中的 to_tsvector 函数带两个参数才能走索引,而 to_tsvector(name)不走索引。
二、 json 、 jsonb 全文检索实践
1.查看to tsvector 函数
postgres-# \df *to_tsvector*
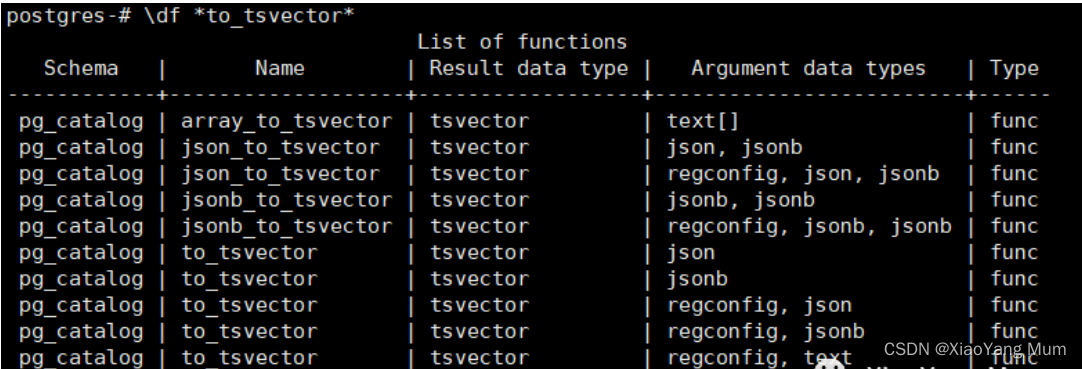
10 版本的 to_tsvector 函数支持的数据类型增加了 json 和 jsonb 。
2.创建数据生成函数
为了便于生成测试数据,创建以下两个函数用来随机生成指定长度的字符串, random_range(int4, int4)函数的代码如下所示:
create or replace function random_range(int4,int4)
returns int4
language sql
as $$
select ($1+floor(($2-$1+1)*random()))::int4;
$$;
接着创建 random_text_simple(length int4)函数,此函数会调用 random_range(int4, int4)函数,其代码如下所示 :
create or replace function random_text_simple(length int4)
returns text
language plpgsql
as $$
declare
possible_chars text:='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ';
output text:='';
i int4;
pos int;
begin
for i in 1..length loop
pos:=random_range(1,length(possible_chars));
output:=output||substr(possible_chars,pos,1);
end loop;
return output;
end;
$$;
random_text_simple(length int4)函数可以随机生成指定长度字符串,下列代码随机生成含3位和6位字符的字符串 :
select random_text_simple(3);
select random_text_simple(6);
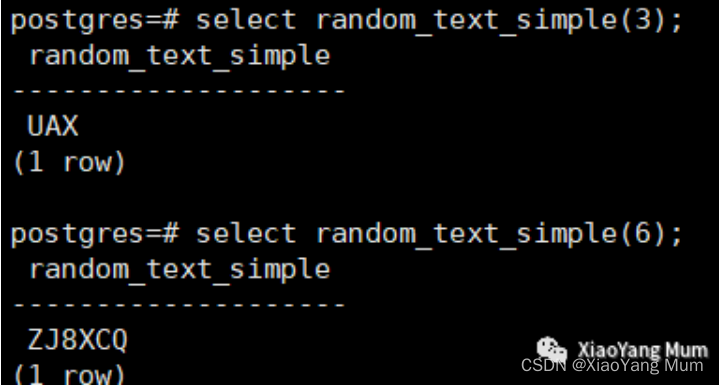
后面会使用这个函数生成测试数据
3.创建 json 测试表
创建 user_ini 测试表,并通过 random_text_simple(length int4) 函数插入 100 万随机生成的六位字符的字符串 ,作为测试数据 , 如下所示 :
create table user_ini_text(id int4,user_id int8,user_name character varying(64),create_time timestamp(6) with time zone default clock_timestamp());
insert into user_ini_text(id,user_id,user_name) select r,round(random()*1000000),random_text_simple(6) from generate_series(1,1000000) as r;
select * from user_ini_text limit 1;
4.json 数据全文检索测试
使用全文检索查询表 user_ini_text且on 的 user_name 字段中包含 U6XUW4 字符的记录,如下所示 :
select * from user_ini_text where to_tsvector('english',user_name)@@to_tsquery('ENGLISH','U6XUW4');
explain analyze select * from user_ini_text where to_tsvector('english',user_name)@@to_tsquery('ENGLISH','U6XUW4');
正常执行说明全文检索支持 json 数据类型 ,只是上述 SQL 进行了全表扫描,性能较低,执行时间为738毫秒

创建索引,再次执行SQL查看执行计划
create index idx_gin_search_json on user_ini_text using gin(to_tsvector('english',user_name));
create index idx_gin_search_json on user_ini_text using gin(to_tsvector('english',user_name));

从上述执行计划看出走了索引, 并且执行时间降为 0.034 毫秒,性能非常不错 。
总结
前一部分对 PostgreSQL 全文检索的实现做了简单介绍,并且给出了一个英文检索的例子,后一部分通过示例介绍了 PostgreSQL的一个新特性,即全文检索对 json、jsonb类型的支持 。PostgreSQL 对中文检索也是支持的, 可自行测试 。
csdn:https://blog.csdn.net/qq961573863/article/details/127470028
墨天轮:https://www.modb.pro/db/530796
公众号:Xiao Yang Mum

