




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
故障现象
故障分析
2.1 20点28分左右,收到节点3大量sql积压短信告警,积压SQL主要为:9yy1zhgjvfbpj.
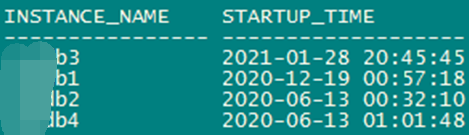
节点3:

2.2 登陆环境核查数据库实例状态及实例启动时间,20点36分确认数据库实例状态正常,且实例没有重启。当即对异常等待事件的sql进行查杀,但是由于应用还在不停的发起连接,在20点45分时节点3发生重启。
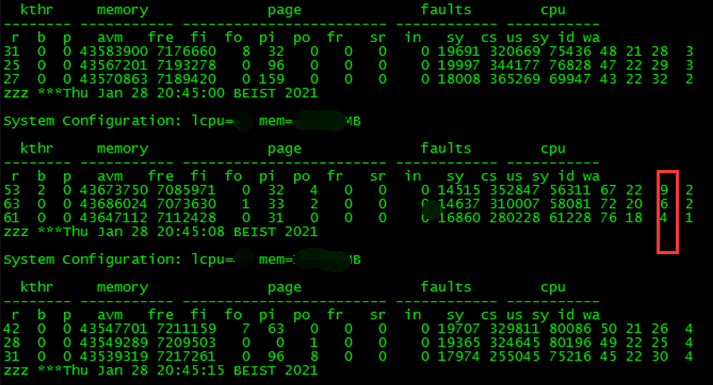
2.3 查看主机日志,并确认无异常报错信息。
节点3主机日志:

2.4 通过检查数据库运行状况时发现节点3上有大量sql积压的等待事件。
enq:us-contention,rowcache local行缓存锁;
enq: IV - contention队列等待之询问IV。
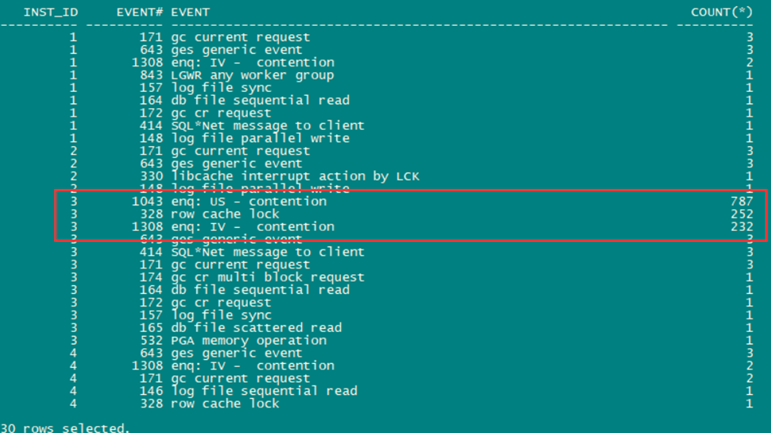
附:
enq:us-contention
这个等待事件有许多脱机撤消段,并且工作负载在短时间内开始联机许多撤消段。当使用具有自动调整的撤销保留期的系统管理撤销时,这可能会导致在DC_ROLLBACK_SEGMENTS上出现高“闩锁:行缓存对象”争用,同时出现高“enq:US-争用”等待。 rowcache local
该是一个共享池相关的等待事件。是由于对于字典缓冲的访问造成的。每一个行缓冲队列锁都对应一个特定的数据字典对象,这被叫做队列锁类型,并可以在V$ROWCACHE视图中找到。在AWR中需要查看DictionaryCache Stats部分用以确定问题。 enq:IV - contention
物化视图(mview)有两部分:
1)保存数据的表;
2)摘要对象。
当提交mview基表上的DML时,summary对象将失效。这是必要的,因为mview可能需要用于查询重写。失效采用IV排队,直到summary对象在所有节点上失效为止。如果存在大量摘要无效,则会导致此排队上的争用。
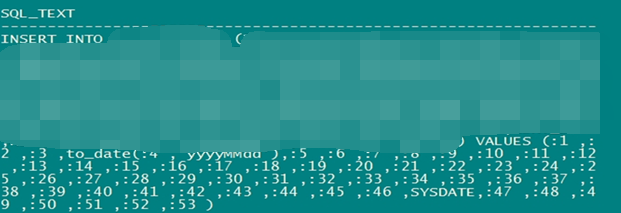
2.5 通过核查节点3上sql积压等待事件对应的会话信息,定位到积压sql对应的sql_id,查到其sql文本就是一个insert语句。
节点3:

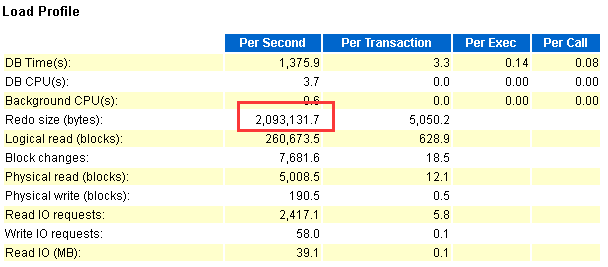
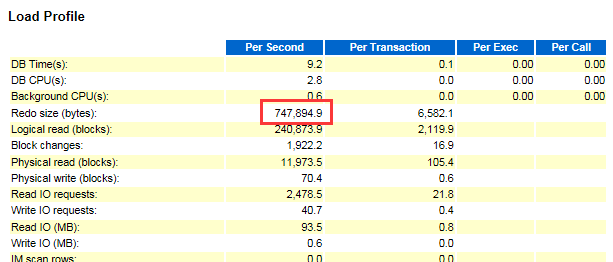
2.6 故障时间段节点3redo变化分析。
故障时间段每秒产生的redo量相比正常时间段增长了约180%。
故障时间段每秒产生redo量:
正常时间段每秒产生redo量:
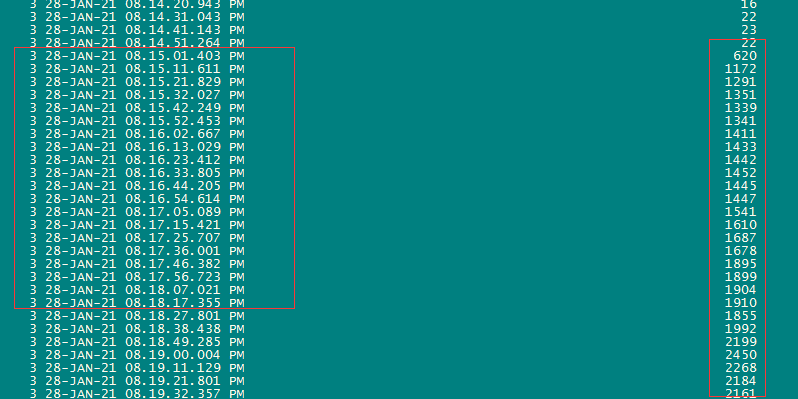
2.7 查看会话变化情况发现从20点15分开始数据库会话开始突增。
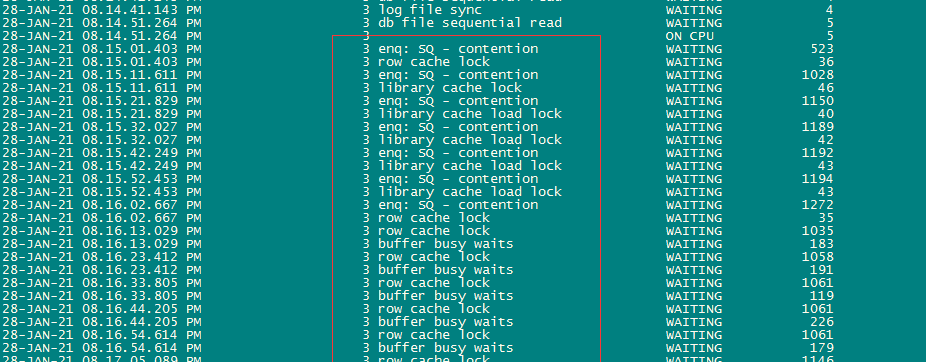
2.8 通过分析故障时间段哪些SQL占用了资源,发现其中sql_id为9yy1zhgjvfbpj的语句占用了数据库48.24%的DBTIME。并最终于20:45分CPU资源耗尽导致实例重启。

9yy1zhgjvfbpj语句执行频次突增截图如下所示,11月2日故障时间段该sql执行频次上下浮动较大,而本次故障时间段该sql每分钟的执行频次持续保持在四千+,最高峰甚至达到1万+.
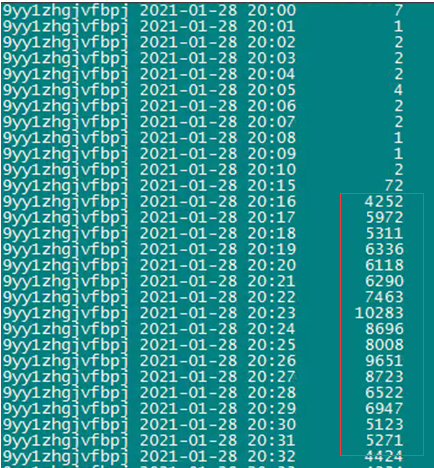
结论:sql_id为9yy1zhgjvfbpj的语句因高并发且频次突增,引发数据库序列及undo争用,消耗了大量的数据库资源,数据库主机最终CPU资源耗尽导致实例重启。
建议一:应用连接降低并发,并查询到该SQL是单次commit,建议修改成批量提交。
建议二:先将高并发insert写入内存库,然后在批量同步至核心库。
文章首发于2021年2月6日

本文作者:魏 斌(上海新炬王翦团队)
本文来源:“IT那活儿”公众号

