




介绍
图机器学习因其巨大的潜力和在非传统任务上表现出色的能力而迅速受到关注。这一个领域正在被积极研究并被吹捧为机器学习的新前沿。那么大家关注的究竟是什么呢?图形机器学习可以做什么,它又是如何工作的?让我们探索一下。
什么是图表?
图是一种数据结构,对理解现实生活中的实体之间的复杂关系非常有帮助。出于这个原因,它在各个领域都有应用,从社会科学到生物学中的蛋白质折叠、计算机网络和谷歌地图。
图的特点是“节点”是现实生活中实体的抽象表示(例如社交网络中的人或计算机网络中的计算机),以及捕获这些实体之间关系的“边”(例如,如果两个人是朋友,他们将通过“友谊图”中的一条边链接)。
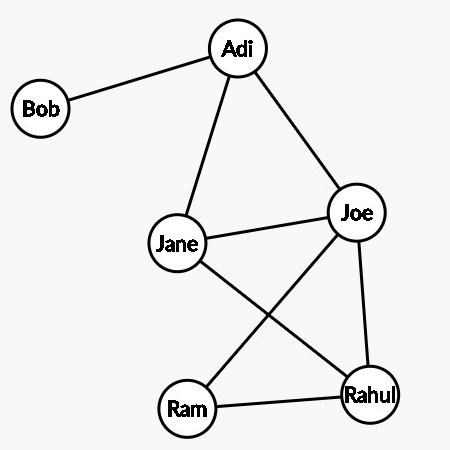
此图显示了图表如何模拟人与人之间的友谊的示例。虽然这是一个简单的例子,但图的真正优势在于有效地建模非常复杂的关系。
建模不同类型的关系
我们可能想要描述非常不同类型的关系,而图表为它们提供了许多工具。从广义上讲,根据边,每个图可以称为“有向”或“无向”。上面显示的图是无向的,因为每条边只是在没有特定方向的情况下连接两个节点。说“Adi 是 Bob 的朋友,但 Bob 不是 Adi 的朋友”是没有意义的。
但是,如果该图是对一群人之间的货币交易进行建模,我们可能会使用有向图。如果 Adi 要给 Bob 一些钱,我们会将其显示为从 Adi 指向 Bob 的箭头(边)。我们可以做的另一件事是利用加权边缘。并非所有关系都具有相同的强度。如果 Rahul 给了 Joe 一些钱,而 Adi 给了 Bob 两倍的钱,那么从 Adi 到 Bob 的有向边可能被认为是从 Rahul 到 Joe 的有向边的两倍厚(更重)。节点通常具有与它们所代表的现实对象相关的属性。这些属性本身可以用作机器学习任务中的特征。甚至可以为边缘分配属性。
图表中的这些规定,加上它们的庞大规模,使它们能够捕捉到极其复杂的关系(微妙的和突出的),超出了我们希望直接解释的任何东西。图表是对许多现实场景进行建模的自然选择;因此,开发允许我们利用这些结构可以提供给我们的丰富信息的机器学习技术应该是一个自然的优先事项。
挑战与解决方案
再次查看图中的图形,并意识到同一个图形可以用许多不同的方式表示。图的一大挑战是它们没有空间或顺序的局部性,并且通常没有参考点。将此与深度神经网络可以轻松利用的具有有序网格状结构的图像进行对比。但是图表是“分散的”和“混乱的”;这使得传统的神经网络很难处理图。在图中表示关系是一个挑战。
传统方法
因此,传统上,大部分努力都针对特征工程,以想出准确捕获图中不同组件的拓扑信息的方法。以图中的节点为例。我们拥有的关于特定节点的一种信息是附加到它的一组属性。例如,在一个友谊网络中,一个节点代表每个人,我们可以有年龄、性别、家乡等属性。当然,这些属性给了我们很多信息,因此我们将它们用作任何我们想要的特征正在尝试预测。但是,图所能获得的信息的真正优势在于更大的图结构中特定节点的连接和位置。假设我们有一个不完整的图,我们试图预测两个节点之间是否存在边(也就是说,如果你考虑一个友谊图,这两个人是朋友吗?)。拥有关于这些节点在图中位置的结构信息在这里非常有用。如果这两个节点没有直接连接,而是连接到另一个分别连接到两个节点的不同节点,那么这两个人也有可能是朋友。
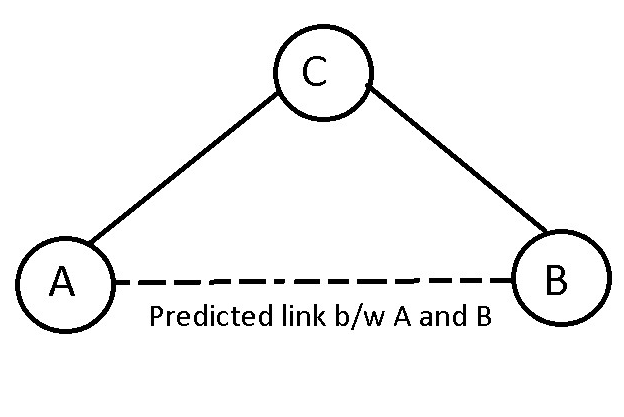
如果 A 和 B 由更多像 C 这样的节点连接,但从未直接连接,那么他们成为朋友的机会也会增加。
因此,在图表中捕获结构信息对于实际利用图表所提供的内容至关重要。但这无论如何都不是一件容易的事,由于通常会长大的巨大尺寸的图表而变得更加困难。为此目的开发了许多方法。
例如,可以通过考虑节点度(节点具有的边数)来获得有关节点在图中的位置的信息。直观地,具有较高度数的节点在图中获得中心位置。根据上下文,这些微不足道的信息可能被证明是非常有用的。然而,还有更复杂的方法可用。节点中心性指标,如中介中心性和特征向量中心性是流行的选择。其他复杂的选择包括计算称为聚类系数的东西,它为我们提供有关给定节点的局部邻域结构的信息,以及类似的graphlet度向量,它再次可以提供有关节点邻域的非常有用的信息。许多这样的特征设计方法在基于边缘和基于整个图的任务级别上也是可用的。这些方法可以提供有关图的关键信息并帮助我们做出良好的预测。唯一的缺点是,这一步手动进行特征设计需要花费大量时间,并且可能导致复杂的非传统预测任务的结果效率低下。
表征学习
然而,如今,该领域已经足够成熟,可以使用表示学习自动为我们提供一种表示图及其不同组件的方法。这使我们能够利用端到端的深度学习,一旦我们输入了一个图形,我们就会得到想要的输出,中间不需要任何手动操作。
作为表示学习的使用示例,以节点嵌入为例,它是图中节点的向量表示,旨在捕获有关节点的拓扑信息。我们不必担心这些嵌入代表什么特征(除非机器学习系统的可解释性是一个关键问题)。基本思想是,由某个相似度函数确定的图中的相似节点应该具有相似的节点嵌入,由向量相似度度量(如余弦相似度)来衡量。有多种方法可用于学习节点嵌入。我们可以使用像 node2vec 这样的算法,它利用图上的随机游走来学习嵌入。另一种选择,现在更流行,或者我们可以使用深度编码器,它使用灵活的神经网络架构通过节点及其邻域之间的“消息传递”来学习节点嵌入。这些方法非常强大,并且在今天使用。
结论
因此,图结构数据包含丰富的信息,尤其是可以帮助捕捉不同实体之间复杂关系的信息。可以有效使用这些信息的机器学习任务具有巨大的预测能力和良好的准确性。图机器学习在当今各行各业都得到了应用。
计算生物学中最具挑战性的突出问题之一,即预测折叠蛋白质的 3D 结构的能力,几乎已经得到解决,部分归功于图形机器学习。请参阅AlphaFold。
对于可以用图构造的任何类型的数据,都存在使用图机器学习的范围。
关键要点
- 图形结构化数据是许多现实生活场景的自然选择,因为图形可以捕捉现实生活实体之间的复杂关系。允许我们处理图结构化数据的一组 ML 技术称为图机器学习。
- 有许多可供选择的图形表示。这些选择使我们能够对各种现实生活场景进行建模。
- 图没有顺序或空间局部性,这使得传统神经网络更难处理它们。因此,设计捕捉图中关系的特征是一项重要的任务。已经开发了许多方法来从图形中获取有用的特征。表示学习今天被广泛用于自动提取节点嵌入等特征。
- 当今,图形机器学习在各行各业都得到了应用,有助于解决一些最重大的科学问题。
原文标题:An Overview of Graph Machine Learning and Its Working
原文作者:Rishit Malpani
原文地址:https://www.analyticsvidhya.com/blog/2022/10/an-overview-of-graph-machine-learning-and-its-working/
