




前面写过一篇关于现代数据技术栈中性价比选择的文章:现代数据技术栈中性价比,主要介绍了数据接入以及数据仓库相关的产品的价格计量方式以及合适的场景。文章的英文版在medium上发表后,有一些读者反馈说应该把Google的BigQuery加入到对比中,也有人提到了数据接入的Hevo。今天我们继续拾遗,把在数据接入和数据仓库中遗漏的产品先盘点一下,然后再进入后边的环节。
01
数据集成和接入
HevoData
HevoData是一家提供Data Pipeline的SaaS公司。公司的核心的服务也是数据集成,只不过在数据集成的时候,支持用户进行Transform,构建从数据接入到数据转换处理的Data Pipeline。从这个角度看,Hevo Data与现在国内做数据接入的几个产品都有点儿类似。不过一个产品什么都有所涉及,就会让大家觉得特色不足。因此无论在数据集成还是在数据建模领域,大家提到Hevo Data并不多。Hevo Data在2017年成立,总部在旧金山,总融资规模4300万美金。
在数据集成方面,HevoData支持超过150个数据源,因此集成能力与Fivetran接近。基本上主流的数据源和目标对象HevoData都能支持。
在定价方面,HevoData的价格计划如下:
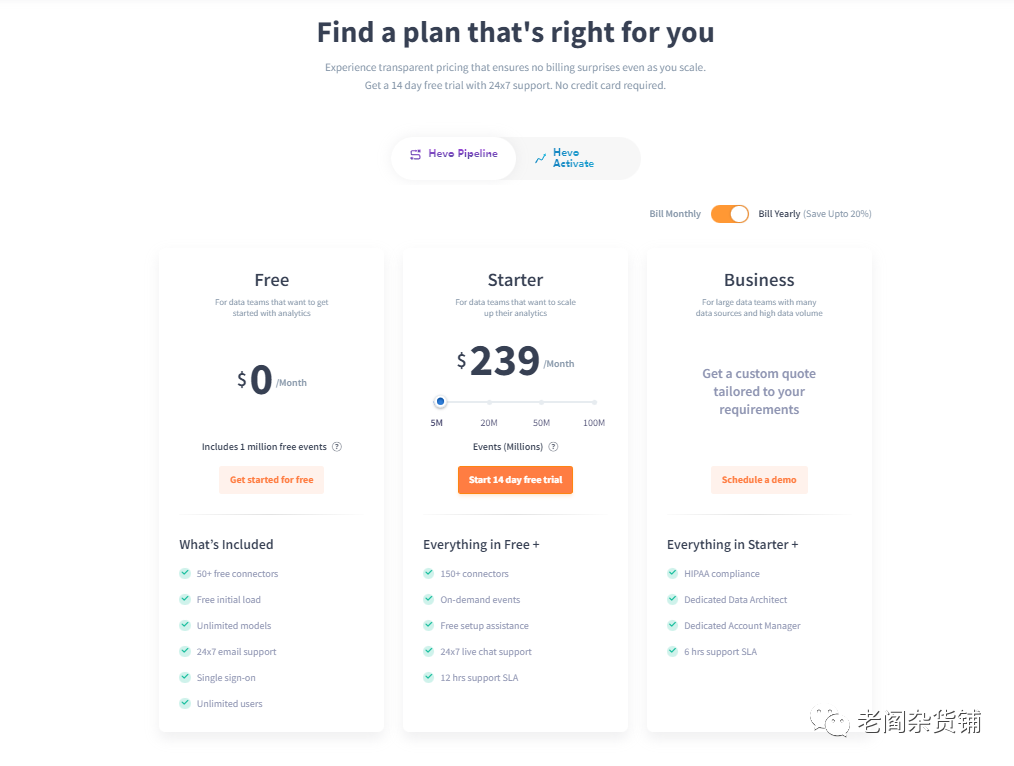
Hevo Pipeline主要是面向的数据集成,Heva Activate则是反向ETL。我们这里主要看看Hevo Pipeline的定价。
Hevo Pipeline分为免费版,入门版和商业版。免费版限制50个数据源和不超过100万事件/月的数量。而入门版则可以使用所有的连接器,最低可以500万事件,然后后续根据事件数量的增加会增加费用,基本上每100万数据大约花费10美金。
从Hevo Data的定价看,如果一个小型团队,数据量不多并且接入的数据源是在免费的数据源中,那么实际上可以免费去使用的。而后续增加数据之后,价格也相对合理。因此从性价比的角度考虑,Hevo Data做数据接入和集成应该还是相对不错的选择。
Matillion
Matillion是来自于欧洲的一家做数据集成的现代数据技术栈公司。目前的估值也已经是独角兽级别。Matillion支持超过110个数据源,并且支持把数据集成到主流的数据仓库和数据湖中。
与HevoData类似,Matillion也包括了数据集成和转换的能力。就是同样支持数据集成之后,再建模和转换,实现一个Data Pipeline把数据装入到目标数据库或者数据仓库当中。
Matillion的价格计划如下:
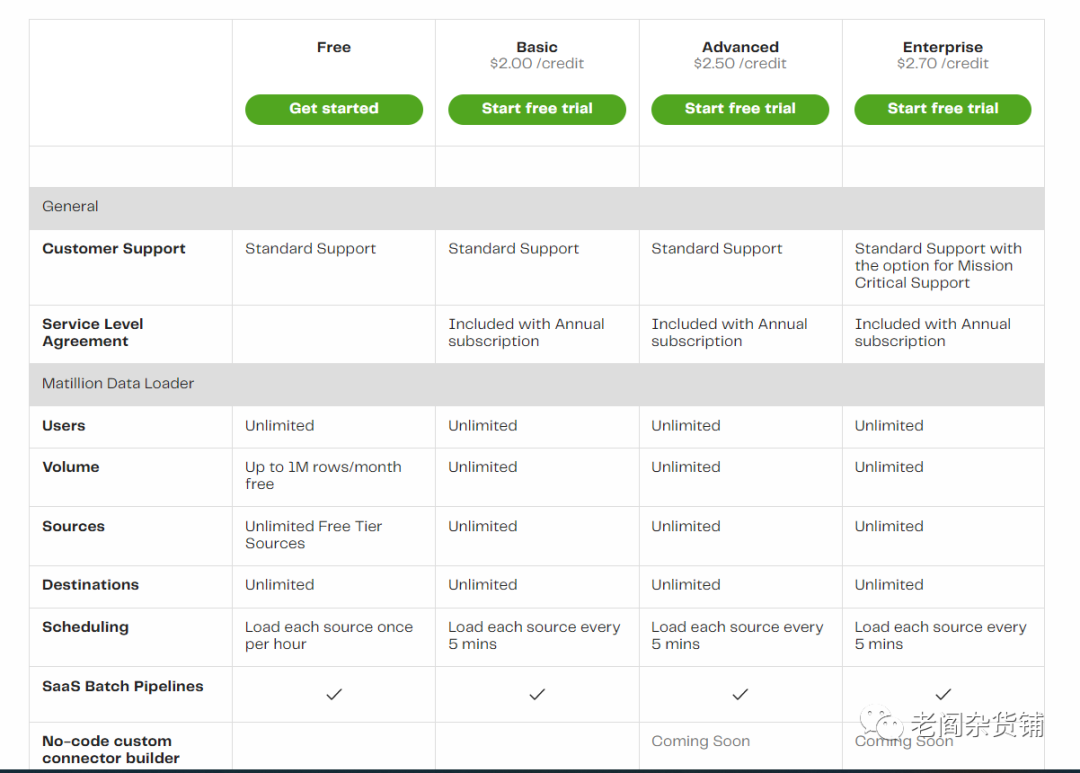
我们可以看到,与HevoData类似,Matillion也有免费套餐。免费套餐的量是100万条以下。Matillion的付费套餐则采用了购买credit的方式。基础版本的credit为2美金一个credit,高级版本为2.5美金,企业版本则为2.7美金。不同的版本,在支持的功能上有一定的区别。但是主要的区别在于Matillion ETL的功能区别,如果仅仅使用Matillion Data Loader,则功能差别不大。Matillion收费的版本中,如果只使用Matillion Data Loader,每个credit能够处理的数据条数根据数据量不同而不同。每月低于500万记录的时候每个credit能集成20000条,后边分不同的阶梯,到每个月10亿条数据的时候,则每个credit能处理1000万条记录。
从Matillion的定价策略看,如果一个企业数据很小的数据量,那么可以采用Matillion的免费套餐。如果数据规模非常大,Matillion的价格也还不错。但是在中等规模的数据,Matillion的价格就有点儿高了。
02
数据仓库和数据湖
在前面的一篇文章中,我主要介绍了独立于云厂商的数据仓库和数据湖产品。因为medium有读者问为啥不写Google BigQuery,今天我就把公有云三个厂商的数据仓库产品Google BigQuery, Amazon Redshift, Microsoft Azure Data Warehousing.
Amazon Redshift
Amazon Redshift是亚马逊公司推出的在公有云上的数据仓库产品,2012年正式推出。可以说Amazon的Redshift的推出促进了现代数据技术栈的产生。关于Redshift的技术,我这里不做过多介绍。作为10年前就推出的云端数据仓库产品,Redshift已经获得非常多的客户的认可和使用。我们这里主要看看它的定价。
如果一个客户从来没有用过Redshift, Aws提供客户两个月的DC2 large的免费试用。对于从来没有使用过Redshift Servless的客户来讲,Aws提供300美金的有效期为90天的credit。在新客户引入方面,aws从来都是比较大方的。
Redshift的定价策略非常的灵活,即支持按照实例类型的按需使用,也支持按照实例类型的长期预订服务。另外,Redshift也支持servless的按照使用量的付费模式。
Redshift的按需模式,DC2 8Xlarge的单实例每小时的费用为4.8美元。如果使用Redshift Servless,则为0.36美元一个RPU每小时。
通过网上不同的资料看,如果一个客户有长期的任务跑的话,用Redshift的预占模式应该更节省费用,不过灵活性不足。如果都是采用pay as you go的方式,Redshift应该跟snowflake的价格差不多。
对于选择来讲,如果你不想被云厂商绑定,那么选择snowflake, databricks, starburst等等更合适。如果你很多东西都在aws上,并且日常的运算比较稳定,在aws购买有更高折扣店预占实例,应该更省钱。
Google BigQuery
Google BigQuery是谷歌公司推出的云端数据仓库产品。Google实际上是比Amazon更早的就发布了自己的公有云的数据仓库产品BigQuery。在2010年的5月份,Google正式发布BigQuery。只不过因为aws在公有云领域的领先地位,使得Redshift被更多的人所了解和使用。
从技术上来讲,BigQuery依托于Google在大数据领域的技术积累,推出的时候就是存储计算分离的架构,实际上比Redshift老的版本更先进。到了今天,基本上所有的公有云的数据仓库/数据湖都是存储计算分离的了,技术上也逐渐的接近。
在价格上,BigQuery是纯粹的Servless的,因此客户不用考虑系统的启停。BigQuery的价格分为两个部分,分别是存储和计算。这个与Snowflake非常的类似。存储价格大家都非常的便宜,BigQuery存储价格是每月前10G免费,然后超过10G之后,活跃存储每G每月0.02美金,长期存储每G每月0.01美金。计算的价格则是按照计算的数据量来计量,这个与其他产品都不相同。如果是按需方式,每T数据的计算5美金,每个月第一个T免费。客户也可以选择专属资源,每月每100槽的计算的花费是2000美金,包年的话折后价格是1700美金。
因为BigQuery是按照计算的数据量来收费,因此如果用户有分析型的业务,通过数仓建模方式,实现很多维度的预聚合,另外针对性的做存储设计让数据读取规模变小,都能节省分析的费用。所以对于相对固定的BI类型的分析,用BigQuery还是不错的性价比选择的。
Microsoft Azure Data Warehousing
Azure Data Warehousing是微软Azure平台推出的云端数据仓库产品。Azure Data Warehousing同样支持servless和专属资源两种方式。对于Servless的按需收费,Azure的价格和Google BigQuery相同。也是处理每T数据花费5美元,在2022年12月底之前,每个月的第一个TB数据处理免费。同样存储是单独收费,价格划分比Google更细,如下:

综合来看,跟Google的存储价格相当。
综合来看,三大公有云厂商的云端数据仓库产品应该在价格上不会有明显的差异。微软和Google因为是按照计算的数据量来收费,因此如果一个企业固定的报表比较多,有比较好的数据仓库分层设计的话,采用Google和微软应该更省钱。由于现在三大厂商都支持存储计算的分离,因此把数据存储在对象存储中,根据自己的需求选择合适的分析计算引擎也能降低被云厂商绑定的担忧。
03
数据建模和转换
在介绍完数据接入和集成、数据仓库和数据湖之后,我们接下来介绍一下数据建模和转换。
在现代数据技术栈中,使用数据的过程已经逐渐地从传统的ETL转变为了ELT。主要的原因是数据的来源越来越多而且不稳定,使用数据的场景也从传统的BI报表到更多的面向运营支撑的日常数据使用。所以先通过数据集成和接入把数据存储到数据湖或者数据仓库中,然后再根据数据应用的场景做建模和转换就成了新的数据使用的方式和流程。
也正是因为这种需求和场景的变化,使得曾经在一体的ETL过程中的建模和转换部分单独作为一个新的高频场景被独立出来。在现代数据技术栈中,专门进行数据建模和转换的产品有dbt, datameer以及QuickTable。
Dbt
关于Dbt这个公司,我在海外数据转换工具独角兽 - dbt labs 有过介绍,所以这里不再介绍更多的公司相关的东西。我们主要来看看Dbt的价格相关的信息。下图是Dbt的价格计划:
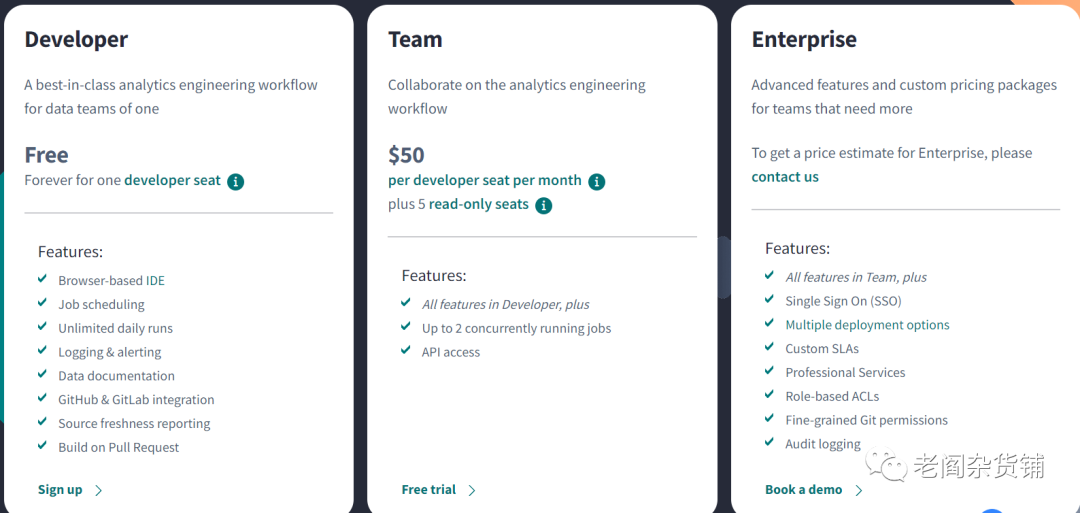
我们可以看到dbt有开发者,团队和企业三个版本。开发者版本为免费版本,单个用户可以使用IDE去建模、进行任务调度以及进行源代码的管理。但是不能进行协同,不能进行多个任务的并发调度。
如果企业想要多个人协同,那么就可以购买团队版本。团队版本每个开发者席位50美金,支持一个可以编写代码的席位以及5个只读模式的席位。另外支持同时两个并发调度任务。
跟所有的SaaS产品一样,dbt的企业版则需要单独跟销售进行沟通,获取定价了。
从最新的dbt公开的资料看,dbt去年有1800个付费客户,预计年收入在3000万美金左右。不过考虑到dbt一直在飞速增长过程中,估计2022年的收入有可能会超过1亿美金。
作为一个数据建模和转换的产品,dbt对于数据工程师比较友好。工程师可以通过SQL和jinja(python template)去进行数据的抽取、转换等等数据加工工作。不过,由于dbt本身没有执行器,因此用户需要先配置transform需要执行的环境。也就是说,需要先购买数据仓库或者数据库。
Dbt支持主流的数据仓库、数据湖以及数据库,另外现在Dbt也已经在抽象自己的语义层,从而方便用户将来实现跨平台的数据加工和处理。因此如果一个团队有非常不错的数据工程能力,并且需要考虑将来跨平台的兼容,dbt是很好的一个选择。
Datameer
Datameer是另外一个数据建模和转换的平台。与dbt不同的是,datameer专门针对snowflake,可以说抱紧了snowflake的大腿。
另外,与Dbt不同的是,datameer除了支持工程师写SQL,还支持用无代码的方式进行数据建模和转换。因此Datameer可以支持跨工程师和业务团队的协同。
在Datameer的官网上,没有列出自己的价格计划。从网上搜到的一些信息看,datameer个人版本一年300美金左右,团队版本则接近20000美元一年。另外, datameer本身不带计算引擎,是完全依赖于snowflake的计算能力的,因此用户需要先购买snowflake才能使用datameer。
如果一个企业的数据仓库构建在Snowflake上,并且希望能让自己的业务团队自服务的进行数据加工和处理,datameer应该是不错的选择。
QuickTable
QuickTable是一个最新发布的在现代数据技术栈中提供无代码进行数据建模和转换的产品。产品的设计基于表格作为用户交互界面,把常用的数据建模和转换功能以菜单功能项的形式提供给技术不熟练的用户进行交互式的数据建模和转换。
与dbt和datameer不同,QuickTable的数据建模和转换不依赖于底层的计算引擎。在G级别的数据,用户可以所见即所得的实现数据建模和转换。因此对于一些数据规模不大,并且日常使用数据比较频繁的用户,日常的数据操作可以不消耗数据仓库的计算成本。只需要把数据存储到廉价的对象存储就可以用QuickTable进行建模和转换了。
从定价来讲,QuickTable包括了个人免费版、个人收费版、团队版和企业版本。个人收费版每个月的定价在50美金左右,团队版按照席位收费。
从兼容角度来讲,QuickTable兼容主要的对象存储以及主要的数据仓库、数据库。相对Datameer具备更好的兼容性。
从性价比角度看,对于中小型技术能力不是很强同时预算也不是很多的企业,采用QuickTable应该是性价比更高的选择。
04
总结
这一期我们补充了数据集成和转换以及三大主要云厂商的数据仓库产品,同时对数据建模产品做了一定的总结。疫情叠加国际局势的不稳定,造成全球经济处于明显的下行状态,性价比无疑是未来两年所有企业都要去考虑的。根据自己企业数据驱动的需求和场景,选择性价比合适的产品,才能让企业更好的度过这个冬天,在春天来临的时候有更好的基础去发展。
